在每一次的热搜冲击下,新浪微博的能力也越来越全强。
从 2014 年开始,新浪微博做单机容器化和在线 Docker 集群。2015 年,基于 Docker 的思维做弹性调度,服务发现与私有云建设。
2016 年,开始做混合云的部署,当下在做混合云与机器学习的支持,同时混合云 DCP 技术进行开源 OpenDCP。
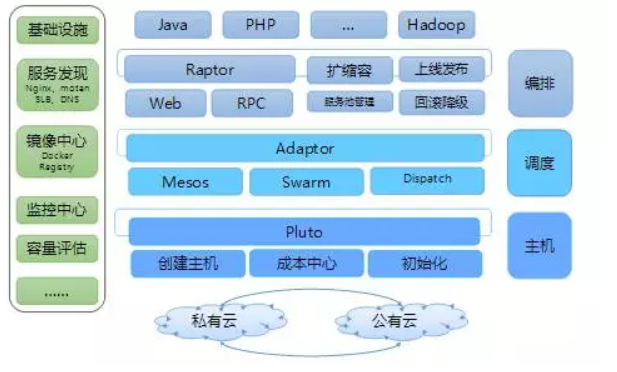
如图为微博的dcp架构(此图来自原文)
当流量来临时,主机层通过私有云和公有云的 SDK 进行主机的创建,之后做初始化达到快速上线的目的。初始化主要做运维环境和 Docker 环境的安装。
初始化之后,编程可运行 Docker 环境,在经过容器调度和服务编排之后,会自动被服务发现模块引入流量,进行上线。
什么是共享池?就是在私有云内部,不同的业务方,在不同的时间内,资源利用率会有所差别,把资源利用率低的共享到共享池,提供给资源利用率高的服务池进行使用。
DCP 大规模集群扩容方式有私有云弹性扩容、公有云弹性扩容和两者同时弹性扩容。
混合云 DCP 设计的核心思想是如何解决设备从哪里来的问题,当设备到位,如何进行一体化扩容,来快速应对峰值流量。
后来运用单机部署的方案计划:运用 Docker 做统一化部署,把代码、运维组件、监控组件等全部封装到容器中,这样一来,就打通了差异化,不管是 Openstack、还是阿里云机器都可直接使用。这里遇到一个很大的问题,就是镜像仓库。假设一个镜像是 1G,如果十分钟之内扩容 1000 台,那就是 1000G 都需要做镜像拉取。但任何一个分布式存储或镜像仓库都无法满足。微博通过镜像分层服务、优化带宽等方法来应对。
再后来就是dockerRedistry,根据多次大规模扩容经验来看,做镜像分层之后仓库还是扛不住,带宽是瓶颈。故构建私有 RegistryHub,在内网和阿里云分别搭建镜像缓存 Mirror。
如,阿里云端用户进行扩容时,Docker Client 就可以直接拉取镜像,而不用穿过内网的 IDC。同时,内网和阿里云的镜像缓存 Mirror 都支持分布式存储。
随着信息量的增大,面对 Reload 损耗的问题,开源解决方案大多利用 Nginx 的 Reload 机制。但在请求量方面,普通 Reload 会导致吞吐量下降 10%。微博的应对方案是 nginx-upsync-module,当 Docker 启动之后,支持基于 Consul 的自动服务发现。同时 Core-module 模块会从配置中心把 Docker 节点自动拉入,做平滑 reload。这样一来,可减少扩容时性能的波动。
文章部分内容摘自原文总结,如有侵权请联系作者,谢谢