DQL 查询语句
排序

# 单列排序
* 只按某一个字段进行排序,单列排序
# 组合排序
* 同时对多个字段进行排序,如果第1个字段相等,则按照第2个字段排序,依次类推
* 语法:
# 具体操作
* 查询所有的数据,在年龄降序排序的基础上,如果年龄相同再按照数学成绩升序排序
聚合函数
之前我们做的查询都是横向查询,都是根据条件一行一行的进行判断。而使用聚合函数查询是纵向查询,是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值 NULL。
# 五个聚合函数

# 语法(我们发现对于 NULL 的记录不会统计,因此如果统计个数,不要使用有可能为 null 的列)
# 如果必须统计 NULL,可以使用 IFNULL() 函数,如果记录为 NULL,则给个默认值,这样统计的数据就不会遗漏。
# 具体操作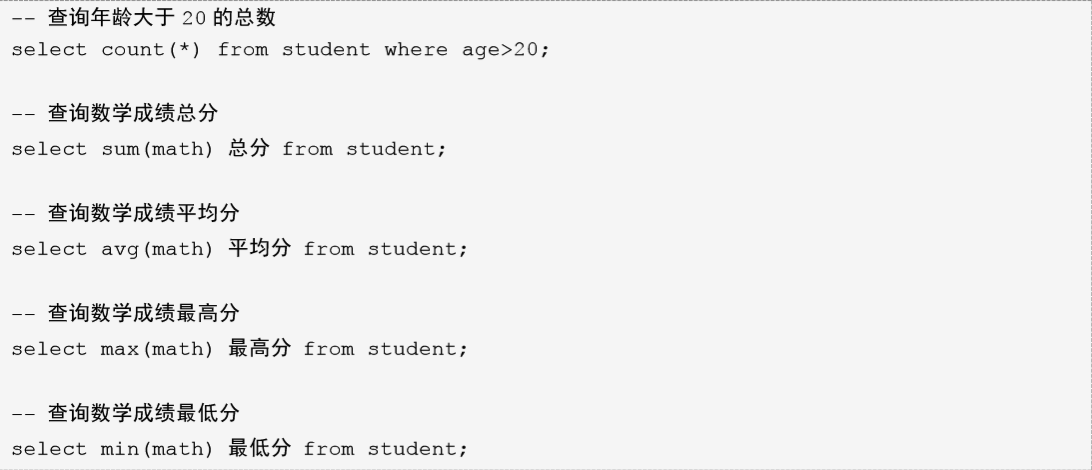
分组

# GROUP BY 怎么分组的?
* 将分组字段结果中相同内容作为一组,如:按照性别将学生分成 2 组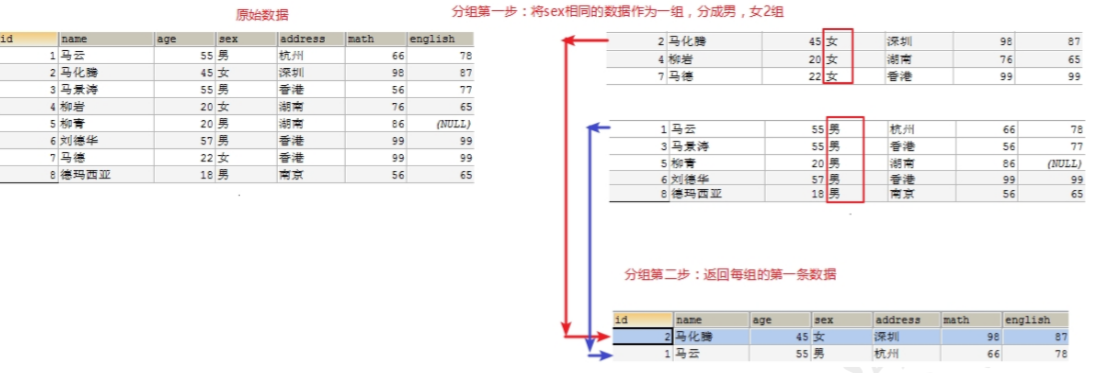
# GROUP BY 将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。
* 分组的目的就是为了统计,因此分组后查询的字段一般就是 分组字段 和 聚合函数。
# 具体操作
* 按性别进行分组,求男生和女生的数学平均分

* 查询男女各有多少人,按性别分组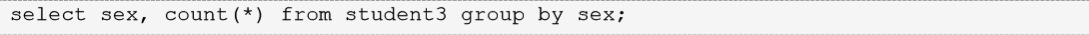

* 查询年龄大于 25 岁的人,按性别分组,统计每组的人数
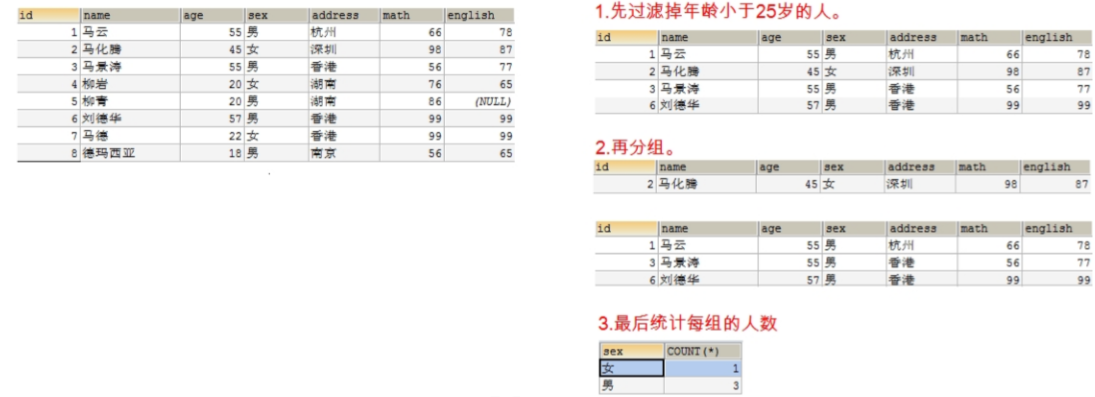
* 查询年龄大于 25 岁的人,按性别分组,统计每组的人数,并只显示性别人数大于 2 的数据

# 注意:如果我们使用某个字段进行分组,那么在查询的时候也需要将这个字段查询出来,否则看不到数据属于哪一组。
# having 和 where 的区别
# 面试题
* Orders 表数据如下所示,执行如下 SQL 语句,运行结果是?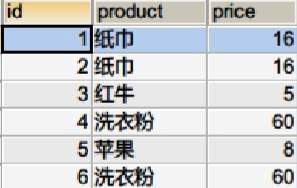
* SELECT
product,
sum(price)
FROM
orders
GROUP BY
product
WHERE
sum(price) > 30;
limit 语句
# 准备数据

# limit 的作用
* LIMIT 是限制的意思,所以 LIMIT 的作用就是限制查询记录的条数
* LIMIT 语法格式
# 具体操作
* 查询学生表中的数据,从第 3 条开始显示,显示 6 条
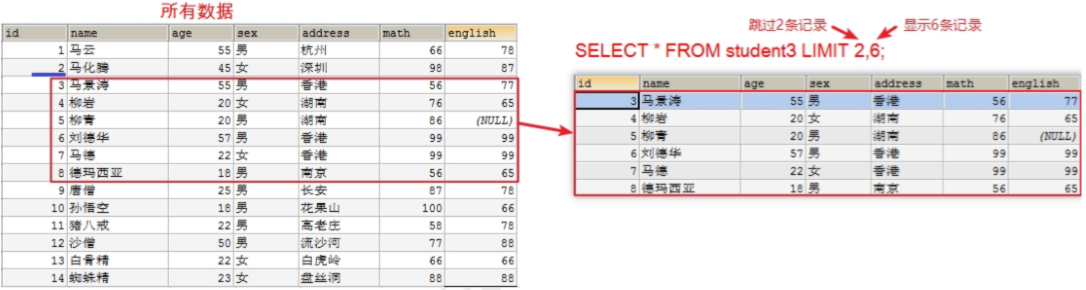
# LIMIT 的使用场景
* 分页:比如我们登录淘宝、京东,返回的商品信息可能有几万条,不是一次全部显示出来的,而是一页显示固定的条数。


# 开始索引的公式
* 开始的索引 = (当前页码 - 1)* 每页显示的条数
# 注意:LIMIT 分页操作是 MySQL 的方言,在别的数据库中都有各自不同的分页语句
数据库备份和还原
备份的应用场景
# 在服务器进行数据传输、数据存储和数据交换,就有可能产生数据故障。比如发生意外停机或存储介质损坏。这时,如果没有采取数据备份和数据恢复手段与措施,就会导致数据的丢失,造成的损失是无法弥补的。
备份与还原语句
# 备份格式:DOS 下,未登录的时候
# 还原格式:mysql 中的命令,需要登录后才可以操作
# 具体操作
* 备份 day21 数据库中的数据到 d:day21.sql 文件中(数据库中的所有表和数据都会导出成为 SQL 语句)
* 还原 day21 数据库中的数据
图形化界面的备份与还原
# 备份数据库中的数据
* 选中数据库,右键 “备份 / 导出”
* 指定导出路径,保存成 .sql 文件即可
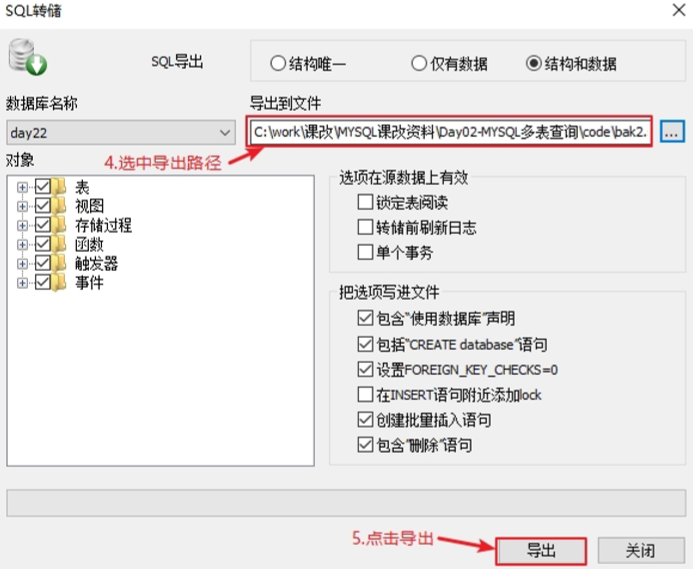
# 还原数据库中的数据
* 删除数据库
* 数据库列表区域右键 “执行 SQL 脚本”,指定要执行的 SQL 文件,执行即可。

数据库表的约束
数据库约束的概述
# 约束的作用
* 对表中的数据进行限制,保证数据的正确性、有效性和完整性。一个表如果添加了约束,不正确的数据将无法插入到表中。约束在创建表的时候添加比较合适。
# 约束的种类
主键约束
# 主键的作用
* 用来唯一标识数据库中的每一条记录
# 哪个字段应该被设置为表的逐渐
* 通常不用业务字段作为主键,单独给每张表设计一个 id 的字段,把 id 作为主键。主键是给数据库和程序使用的,不是给最终的客户使用的。所以主键有没有含义没有关系,只要不重复且非空即可。
* 身份证、学号等不建议设置成主键
# 创建主键
* 关键字:PRIMARY KEY
* 特点:
1)非空 not null
2)唯一
* 创建主键的方式
1)在创建表的时候给字段添加主键
2)在已有表中添加主键
# 具体操作
* 创建学生表 st5,包含字段(id,name,age),将 id 设置成主键


# 删除主键
# 主键自增
* 如果让我们自己添加主键很有可能重复,因此我们希望每次插入新记录时,数据库自动生成主键字段的值


# 修改自增长的默认起始值
* 默认地 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下列 SQL语法
1)创建表时指定起始值

2)创建好以后修改起始值

# DELETE 和 TRUNCATE 对自增长的影响
* DELETE:删除所有记录后,自增长没有影响
* TRUNCATE:删除以后,自增长又重新开始
唯一约束
# 什么是唯一约束?
* 表中某一列不能出现重复的值
# 唯一约束的基本格式
# 删除唯一约束
* ALTER TABLE 数据表名 DROP INDEX 列名;
# 实现唯一约束(唯一约束限定的列的值可以有多个 NULL)
非空约束
# 什么是非空约束?
* 某一列不能为 NULL
# 非空约束的基本语法格式
# 具体实现

# 默认值

# 疑问:如果一个字段设置了非空与唯一约束,该字段与主键的区别?
* 主键数在一个表中只能有一个。主键可以单列,也可以多列
* 自增长只能用在主键上
外键约束
# 单表的缺陷
* 创建一个员工表,包含字段(id,name,age,dep_name,dep_location),id 为主键并自动增长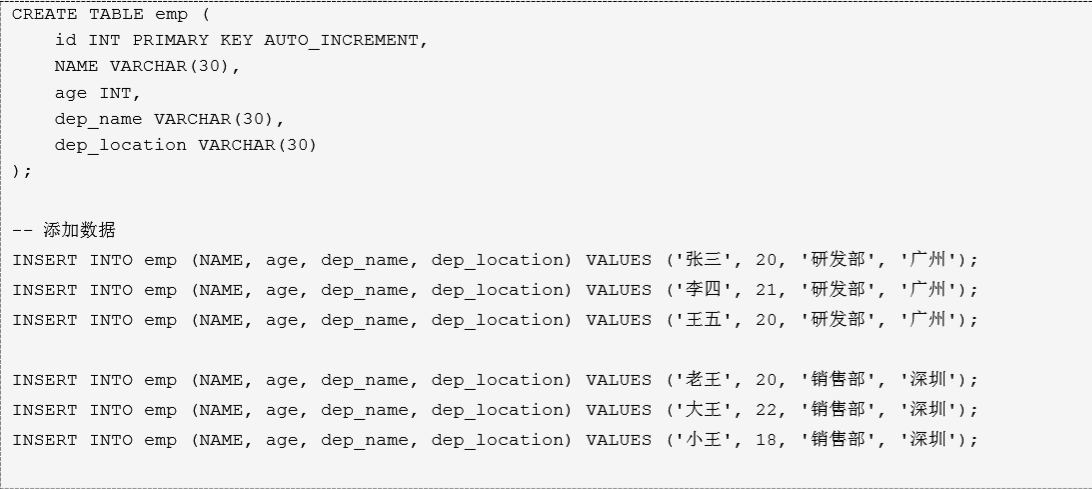
* 存在缺陷:
1)数据冗余
2)后期会出现增删改问题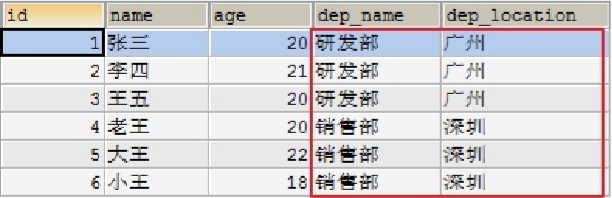
# 解决方案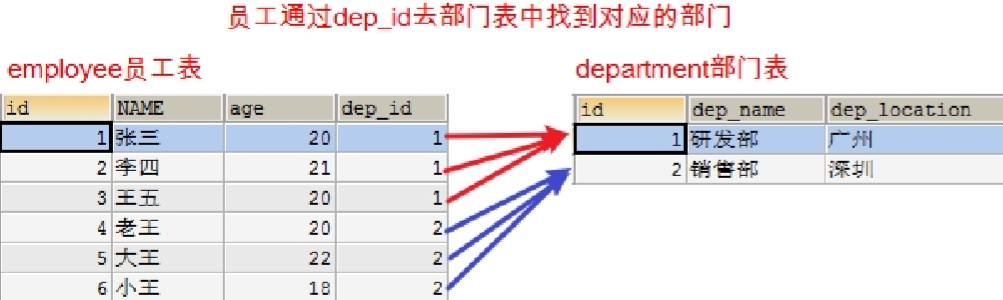


* 问题:当我们在 employee 的 dep_id 里面输入不存在的部门,数据依然可以添加,但是并没有对应的部门。employee 的 dep_id 中的数据理论上只能是 department 表中存在的 id
* 解决方式:使用外键约束
# 什么是外键约束
* 一张表的外键是另一张表的主键,所以两张表就形成了关联关系
* 什么是外键:在从表中与主表主键对应的那一列,如:员工表中的 dep_id
* 主表:一方,用来约束别人的表
* 从表:多方,被别人约束的表
# 创建约束的语法(外键可以为 NULL 但是不可以为主表主键中不存在的值)
* 新建表时增加的外键
* 已有表增加外键
# 具体操作(必须先创建主表,再创建从表)


# 删除外键

# 外键的级联
* 出现新的问题:

* 什么是级联操作:
在修改和删除主表的主键时,同时更新或删除副标的外键值,称为级联操作。


# 数据约束小结
表与表之间的关系
表关系的概念
# 现实生活中,实体与实体之间肯定是有关系的,比如:老公和老婆,部门和员工,老师和学生等。那么我们在设计表的时候,就应该体现出表与表之间的这种关系
一对多
# 一对多(1 :n)
* 例如:班级和学生,部门和员工,客户和订单,分类和商品
# 一对多建表原则:在从表(多方)创建一个字段,作为外键指向主表(一方)的主键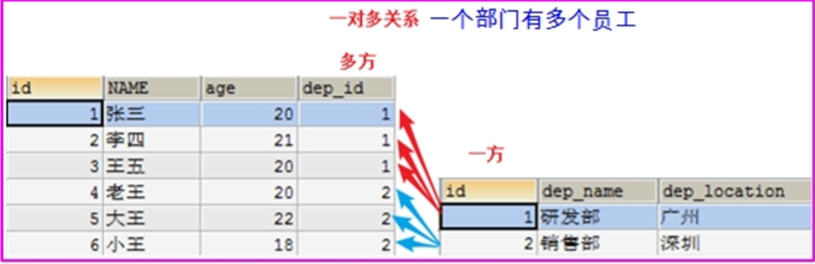
多对多
# 多对多(m :n)
* 例如:老师和学生,学生和课程,用户和角色
# 多对多关系的建表原则:需要创建第三张表,中间表至少两个字段,这两个字段分别作为外键指向各自一方的主键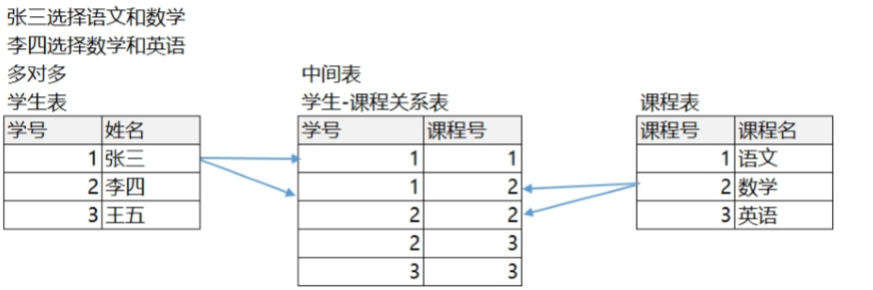
一对一
# 一对一(1 :1)
* 在实际开发中应用不多,因为一对一可以创建成一张表
# 建表原则
* 外键唯一:主表的主键和从表的外键(唯一),形成主外键关系,外键唯一 UNIQUE
* 外键是主键:主表的主键和从表的主键,形成主外键关系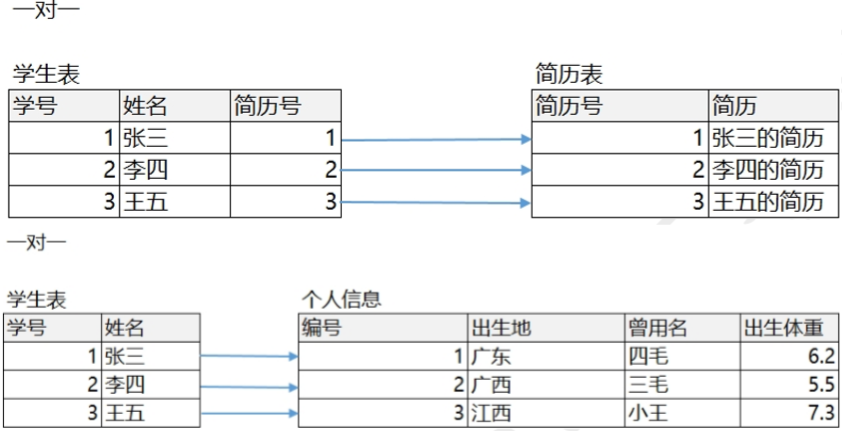
一对多关系案例
# 需求:一个旅游线路分类中有多个旅游线路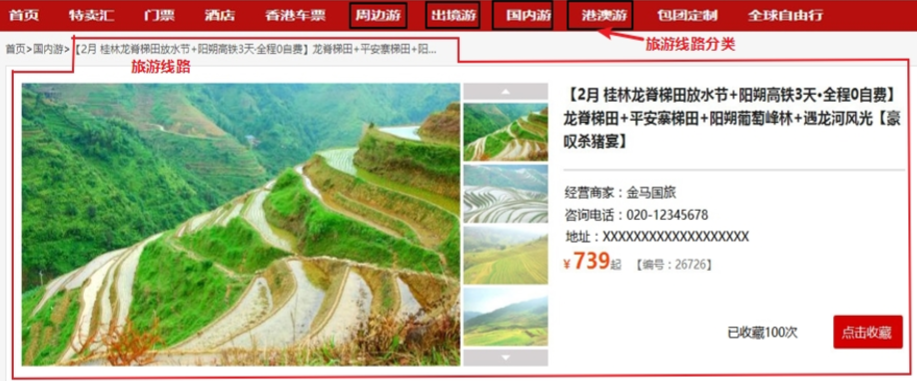


# 具体操作


多对多关系案例
# 需求:一个用户收藏多个线路,一个线路被多个用户收藏


# 具体操作


表和表之间的关系小结

数据库设计
数据规范化
# 什么是范式
* 好的数据库设计对数据的存储性能和后期的程序开发,都会产生重要的影响。建立科学的,规范的数据库就需要满足一些规则来优化数据库的设计和存储,这些规则就是范式。
# 三大范式:
* 目前关系型数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)
* 满足最低要求的范式就是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式依此类推。一般说来,数据库只须满足第三范式(3NF)就足够了。
1NF
# 概念:
* 数据库表的每一列都是不可分割的原子数据项,不能是集合、数组等非原子数据项。即表中的某个列有多个值时,必须拆分为不同的列。简言之,第一范式每一列不可再拆分,称为原子性。
# 示例
| 学号 | 姓名 | 班级 |
| 1 | 张三 | 一年级三班 |
| 2 | 李四 | 一年级二班 |
| 3 | 王五 | 一年级一班 |
2NF
# 概念:在满足 1NF 的基础上,非码属性必须完全依赖于候选码(消除非主属性对主码的部分函数依赖)
* 函数依赖:A -- > B,如果通过 A 属性(属性组)的值可以唯一确定 B 属性的值,则称 B 依赖于 A
如: 学号 -- > 姓名, (学号 , 课程名称)-- > 分数
* 完全函数依赖:A -- > B,如果 A 是一个属性组,则 B 属性值的确定需要依赖 A 属性组中的所有的属性值
* 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
* 当存在一个复合主键包含多个主键列的时候,才会发生不符合第二范式的情况。比如有一个主键有两个列,不能存在只依赖于其中一个列的情况,这就是不符合第二范式
# 示例:
* 借书证表
| 学生证号 | 学生名称 | 学生证办理时间 | 借书证号 | 借书名称 | 借书证办理时间 |
* 分成两张表
| 学生证号 | 学生名称 | 学生证办理时间 |
| 借书证号 | 借书名称 | 借书证办理时间 |
3NF
# 概念:
* 在满足第二范式的前提下,表中的每一个列都直接依赖于主键,而不是通过其他列简介依赖于主键
* 简言之,第三范式就是所有列不依赖于其他非主键列,也就是在满足 2NF 的基础上,任何非主列不得传递依赖于主键。
* 所谓传递依赖,指的是如果存在“A -> B -> C” 的决定关系,则C传递以来于A。因此满足第三范式的数据库表应该不存在以下的依赖关系:主键列 -> 非主键列x -> 非主键列y
# 示例:
* 学生信息表
| 学号 | 姓名 | 年龄 | 所在学院 | 学院地点 |
* 存在的决定关系:
学号(姓名) -> 所在学院 -> 学院地点
* 拆分成两张表
| 学号 | 姓名 | 年龄 | 所在学院的编号(外键) |
| 学院编号 | 所在学院 | 学院地点 |
