需求
给定一个目录,生成一个doc文件,内容是:目录的内容。
**目录结构:
|--一级文件夹A
| |--压缩包A4.rar
| |--文档A1.docx
| |--文档A2.docx
| |--文档A3.docx
|--一级文件夹B
| |--文件夹B1
| | |--文档B11 .docx
| | |--文档B12.docx
| |--文档B1.docx
| |--文档B2.docx
|--主要内容.docx
主要内容就是我们要生成的doc文件,放在要解析的目录就可以了。
**doc内容:

思路
我们分三部分实现这个功能:
1、首先我们做一个简单的gui,有很多gui的库可以选择,这个需求功能简单,所以选了thinker,python标准库方便,满足需求
2、遍历目录结构,选择python标准库os
3、将目录内容写到word中,选择docx库
Gui
怎么说呢,thinker库很直观?我很少接触gui库,不过几分钟弄个demo出来还是很简单的。
from tkinter import *
from tkinter.filedialog import askdirectory
#选择路径
def selectPath():
path_ = askdirectory()
path.set(path_)
def outPut():
pass
# 创建窗口对象
root_window = Tk()
root_window.title('目录内容识别工具')
root_window.geometry('300x100')
#文本框中显示路径地址
path = StringVar()
Label(root_window,text = "目标路径:").grid(row = 0, column = 0)
#textvariable关联一个StringVar类,可以用set()和get()函数去设置和获取控件中的值
Entry(root_window, textvariable = path).grid(row = 0, column = 1)
Button(root_window, text = "选择", command = selectPath,width=6).grid(row = 0, column = 2)
Button(root_window, text = "导出", command=outPut ,width=6).grid(row = 0, column = 3)
#进入消息循环,没这个不显示
root_window.mainloop()
大致是这样的,先创建一个窗口对象TK,然后往里边组件
Label:目标路径
Entry:文本框
Button:按钮
selectPath() :路径选择逻辑
outPut() :导出逻辑
askdirectory():内置函数,获取路径地址
结果
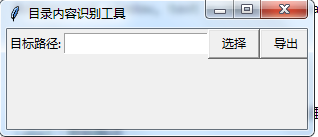
遍历目录
遍历目录有三种方式,os.walk() 、os.listdir()、os.scandir()
其中listdir和scandir都不对目录递归遍历,就是说不返回目录下的子文件下的内容,walk可以返回子文件下的内容,但他是广度遍历。就是返回第一层目录,再接着遍历第二层,接着第三层。详细看下一节介绍。
我这里选择scandir,然后自己递归遍历下层文件夹(深度遍历)。
import os
import os.path
def test_showdir(path, depth):
for item in os.scandir(path):
print("| " * depth + "+--" + item.name)
# #递归出口
if item.is_dir():
test_showdir(item.path, depth + 1)
if __name__ == '__main__':
path = r'C:UsersAdministratorDesktop测试'
test_showdir(path, 0)
这里有两个知识点:
1、函数的递归调用(出口if 、参数depth)
2、目录遍历方法的选择
结果:

python-docx
docx简直是神器呀,基本能实现大部分的word需求,以前写自动巡检报告的时候经常要用到。
这里先贴一段官方代码感受一下吧
from docx import Document
from docx.shared import Inches
document = Document()
document.add_heading('Document Title', 0)
p = document.add_paragraph('A plain paragraph having some ')
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote')
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'first item in ordered list', style='List Number'
)
document.add_picture('monty-truth.png', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
document.save('demo.docx')
总结:
本节介绍一下需求和思路,上述的三个环节在以下章节再详细讨论。