一、小网站,应用和数据都在一台服务器上
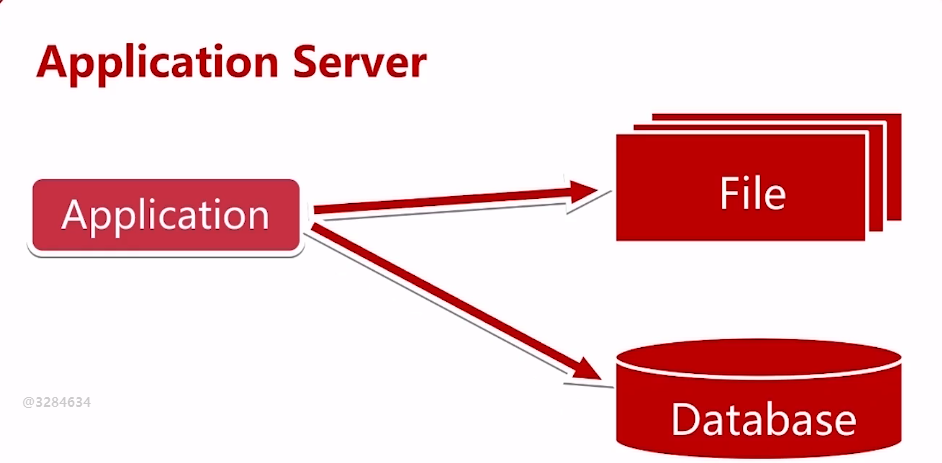
二、随着用户的数量增加,一台服务器已经不行了,我们把应用服务和数据服务分离,给应用服务器更好的CPU和内存,给数据服务器更好、更大、更快的硬盘

三台服务器:应用服务器、文件服务器、数据服务器
三、很多的数据不需要每次都从服务器获取,所以我们使用了缓存
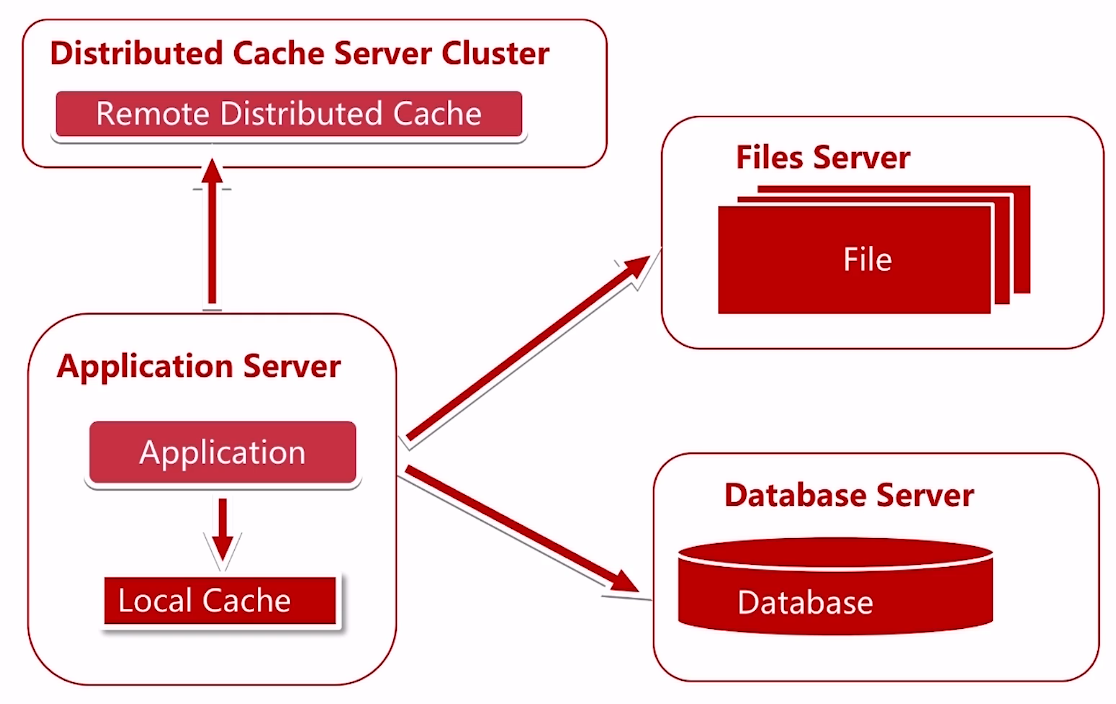
缓存分为俩种:本地缓存和远程服务缓存
四、随着数据量更大,就需要一直加服务器,费用指数级增加,这时候就可以使用负载均衡
负载均衡的策略:轮询、权重、地址散列(原IP地址散列、目标IP地址散列、加权最少链接)
优缺点:
轮询 实现简单 不考虑每台服务器处理能力
权重 考虑了每台服务器的处理能力
地址散列 能实现每一个用户访问同一个服务器
最少链接可以使集群中各个服务器负载更加均匀
加权最少链接就是在最少链接的基础上为每台服务器加上权值,算法就是活动连接数乘以256加上非活动连接数,和再除以权重,计算出来的值小的服务器优先被选择
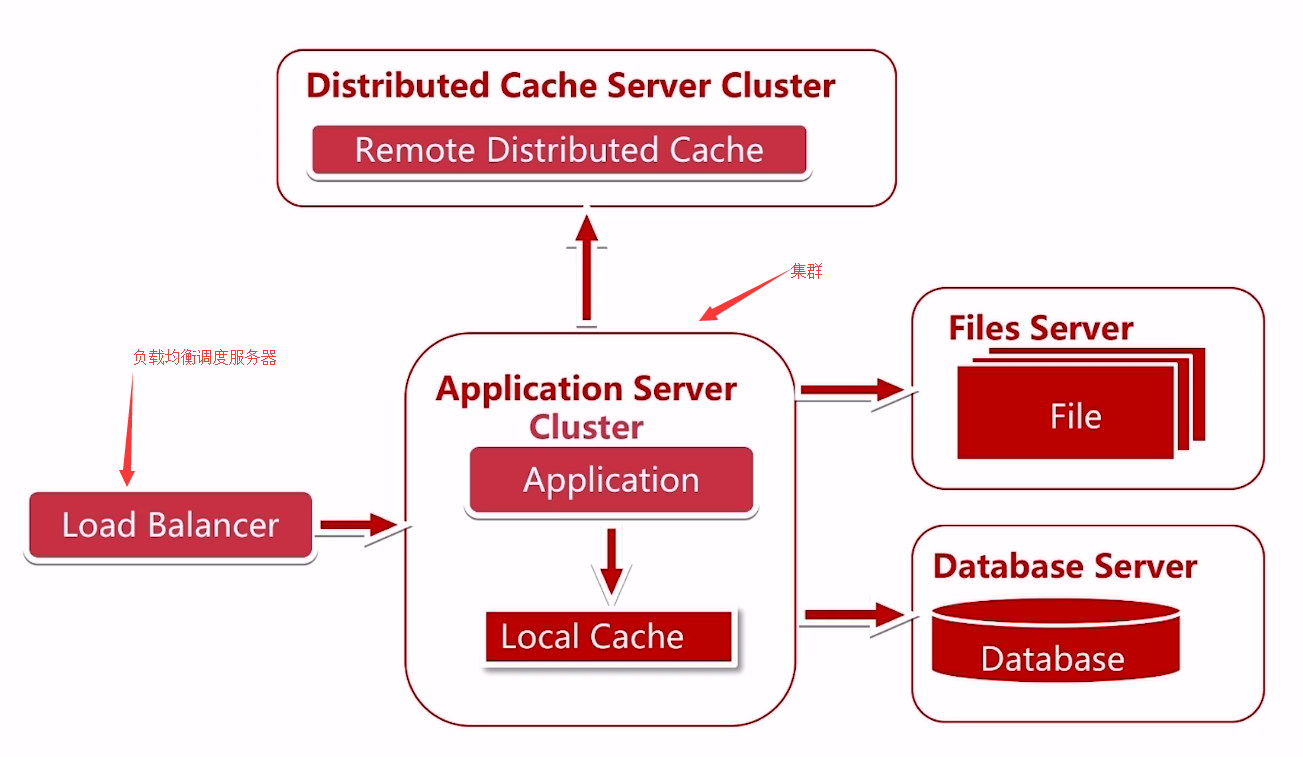
选择设想一个场景:我们登陆的时候,登陆了A服务器,session信息登陆到了A服务器,假设我们使用的负载策略是hash散列,登陆信息还可以从A服务器获取,但IP hash不够分散,就有可能造成某些服务器压力过大,某些服务器又没有什么压力,
这时候网卡的带宽就会成为一个瓶颈;
我们使用轮询或者最小负载均衡的策略,第一次访问把session信息保存到A服务器,再次访问的时候有可能访问B服务器,这时B服务器是没有session信息的,那我们就需要解决一个session管理的问题
使用一个服务器专门来处理session,把yoghurt的信息都保存到这个服务器上,

---恢复内容结束---
一、小网站,应用和数据都在一台服务器上
二、随着用户的数量增加,一台服务器已经不行了,我们把应用服务和数据服务分离,给应用服务器更好的CPU和内存,给数据服务器更好、更大、更快的硬盘
三台服务器:应用服务器、文件服务器、数据服务器
三、很多的数据不需要每次都从服务器获取,所以我们使用了缓存
缓存分为俩种:本地缓存和远程服务缓存
四、随着数据量更大,就需要一直加服务器,费用指数级增加,这时候就可以使用负载均衡
负载均衡的策略:轮询、权重、地址散列(原IP地址散列、目标IP地址散列、加权最少链接)
优缺点:
轮询 实现简单 不考虑每台服务器处理能力
权重 考虑了每台服务器的处理能力
地址散列 能实现每一个用户访问同一个服务器
最少链接可以使集群中各个服务器负载更加均匀
加权最少链接就是在最少链接的基础上为每台服务器加上权值,算法就是活动连接数乘以256加上非活动连接数,和再除以权重,计算出来的值小的服务器优先被选择
选择设想一个场景:我们登陆的时候,登陆了A服务器,session信息登陆到了A服务器,假设我们使用的负载策略是hash散列,登陆信息还可以从A服务器获取,但IP hash不够分散,就有可能造成某些服务器压力过大,某些服务器又没有什么压力,
这时候网卡的带宽就会成为一个瓶颈;
我们使用轮询或者最小负载均衡的策略,第一次访问把session信息保存到A服务器,再次访问的时候有可能访问B服务器,这时B服务器是没有session信息的,那我们就需要解决一个session管理的问题
使用一个服务器专门来处理session,把yoghurt的信息都保存到这个服务器上,
---恢复内容开始---
一、小网站,应用和数据都在一台服务器上
二、随着用户的数量增加,一台服务器已经不行了,我们把应用服务和数据服务分离,给应用服务器更好的CPU和内存,给数据服务器更好、更大、更快的硬盘
三台服务器:应用服务器、文件服务器、数据服务器
三、很多的数据不需要每次都从服务器获取,所以我们使用了缓存
缓存分为俩种:本地缓存和远程服务缓存
四、随着数据量更大,就需要一直加服务器,费用指数级增加,这时候就可以使用负载均衡
负载均衡的策略:轮询、权重、地址散列(原IP地址散列、目标IP地址散列、加权最少链接)
优缺点:
轮询 实现简单 不考虑每台服务器处理能力
权重 考虑了每台服务器的处理能力
地址散列 能实现每一个用户访问同一个服务器
最少链接可以使集群中各个服务器负载更加均匀
加权最少链接就是在最少链接的基础上为每台服务器加上权值,算法就是活动连接数乘以256加上非活动连接数,和再除以权重,计算出来的值小的服务器优先被选择
选择设想一个场景:我们登陆的时候,登陆了A服务器,session信息登陆到了A服务器,假设我们使用的负载策略是hash散列,登陆信息还可以从A服务器获取,但IP hash不够分散,就有可能造成某些服务器压力过大,某些服务器又没有什么压力,
这时候网卡的带宽就会成为一个瓶颈;
我们使用轮询或者最小负载均衡的策略,第一次访问把session信息保存到A服务器,再次访问的时候有可能访问B服务器,这时B服务器是没有session信息的,那我们就需要解决一个session管理的问题
使用一个服务器专门来处理session,把yoghurt的信息都保存到这个服务器上,
---恢复内容结束---
一、小网站,应用和数据都在一台服务器上
二、随着用户的数量增加,一台服务器已经不行了,我们把应用服务和数据服务分离,给应用服务器更好的CPU和内存,给数据服务器更好、更大、更快的硬盘
三台服务器:应用服务器、文件服务器、数据服务器
三、很多的数据不需要每次都从服务器获取,所以我们使用了缓存
缓存分为俩种:本地缓存和远程服务缓存
四、随着数据量更大,就需要一直加服务器,费用指数级增加,这时候就可以使用负载均衡
负载均衡的策略:轮询、权重、地址散列(原IP地址散列、目标IP地址散列、加权最少链接)
优缺点:
轮询 实现简单 不考虑每台服务器处理能力
权重 考虑了每台服务器的处理能力
地址散列 能实现每一个用户访问同一个服务器
最少链接可以使集群中各个服务器负载更加均匀
加权最少链接就是在最少链接的基础上为每台服务器加上权值,算法就是活动连接数乘以256加上非活动连接数,和再除以权重,计算出来的值小的服务器优先被选择
选择设想一个场景:我们登陆的时候,登陆了A服务器,session信息登陆到了A服务器,假设我们使用的负载策略是hash散列,登陆信息还可以从A服务器获取,但IP hash不够分散,就有可能造成某些服务器压力过大,某些服务器又没有什么压力,
这时候网卡的带宽就会成为一个瓶颈;
我们使用轮询或者最小负载均衡的策略,第一次访问把session信息保存到A服务器,再次访问的时候有可能访问B服务器,这时B服务器是没有session信息的,那我们就需要解决一个session管理的问题
session管理的方案:
第一种:使用session sticky(粘滞会话)
对于同一个连接中的数据包,负载均衡会将其进行NAT转换后,转发至后端固定的服务器进行处理
Browser1通过1这个路径,走到负载均衡服务器,然后走1的路径,到达aPPLICATION中,也就是说Browser1每次都会回访问到1这个aPPLICATION中
解决了session共享问题,缺点:1、1的服务器重启了,上面的session会全部消失,2、负载均衡服务器成了一个有状态的服务器,要实现容载会有麻烦
第二种:session复制

Browser1通过负载均衡,把session存到Application中的时候,会把这个用户的session复制到第二个服务器上,也就是这俩个服务器都保存了Browser1的信息
缺点:1、应用服务器带宽键的问题,这俩个服务器要不断地同步session信息 2、当大量用户在线的时候,服务器会占用大量内存,不适合做大规模集群,适合用户不多的情况
第三种:基于Cookie

我们使用带着携带session的cookie去访问服务器
缺点:1、cookie的长度有限制;2、session保存在cookie上,安全性也有问题
第四种:把session做成了session服务器
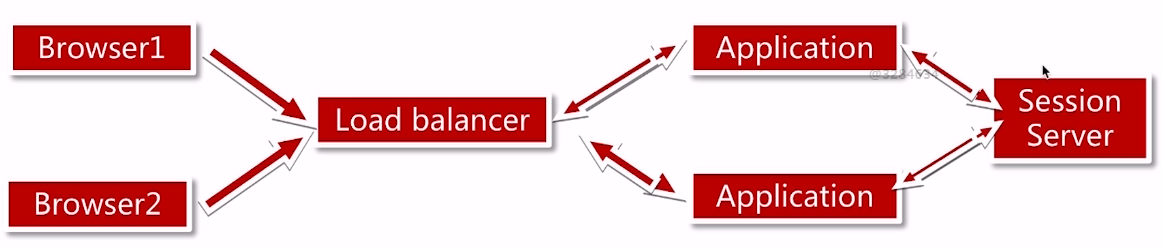
请求路径:Browser1通过负载均衡请求到Application中,然后把Browser1的信息存到Session Server中,当想获取的时候,箭头就往回指,应用从session服务器获取session,我们所有用户的信息都保存到Session Server中
缺点:在当前架构中,Session Server是单点的,要如何解决这个单点,保证它的可用性,可以把Session Server也做成一个集群
这种架构适用于session数量和web服务器数量大的情况。同时在改成这种架构的时候,我们也要调整session存储的业务逻辑
上面是解决横向服务器业务扩展。先解决数据库
数据库的读与写都会经过数据库,当数据量大的时候,就会成为一个瓶颈

我们使用了数据库的读写分离,Master是主库,Slave是从(分)库,同时应用要介入多数据源,并且通过统一的数据访问模型(data access modele)进行访问
数据库读写分离把所有的读引入到Slave,把所有的写引入到Master
这样我们的应用程序也要做出相应的变化,我们在这里就实现了一个数据访问模块,使上层写代码的人不知道读写分离的存在,这样多数据源的读写,就对业务代码没有了侵入
这就引出了代码层次的演变,如何支持对数据源,如何封装对业务没有侵入,如何使用目前业务使用的orm框架完成普通的读写分离,是否需要更换ORM,各有什么优缺点
当数据量非常大的时候,主库和分库在复制的时候,有没有延时;当我们把主库和从库在分机房部署的时候,跨地方分机部署也是个问题;应用对数据源的问题
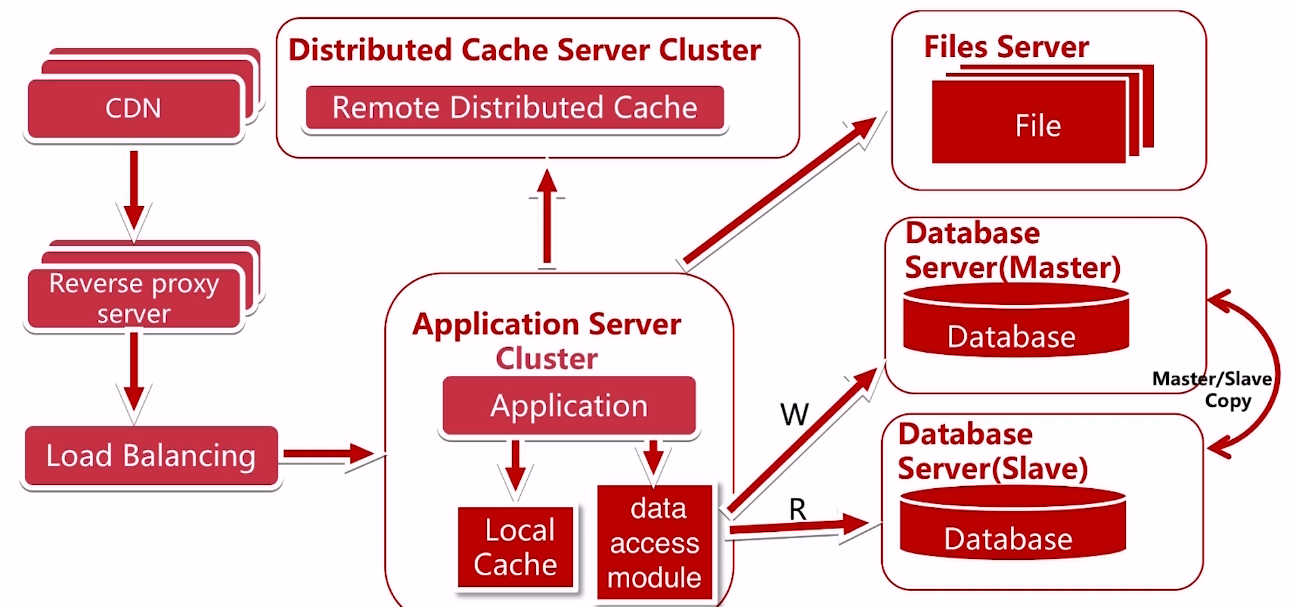
为了提高服务器能力,我们又增加了CDN和反向代理
使用CDN可以很好的解决不同地区访问速度问题
反向代理则可以在服务器机房中缓存用户资源
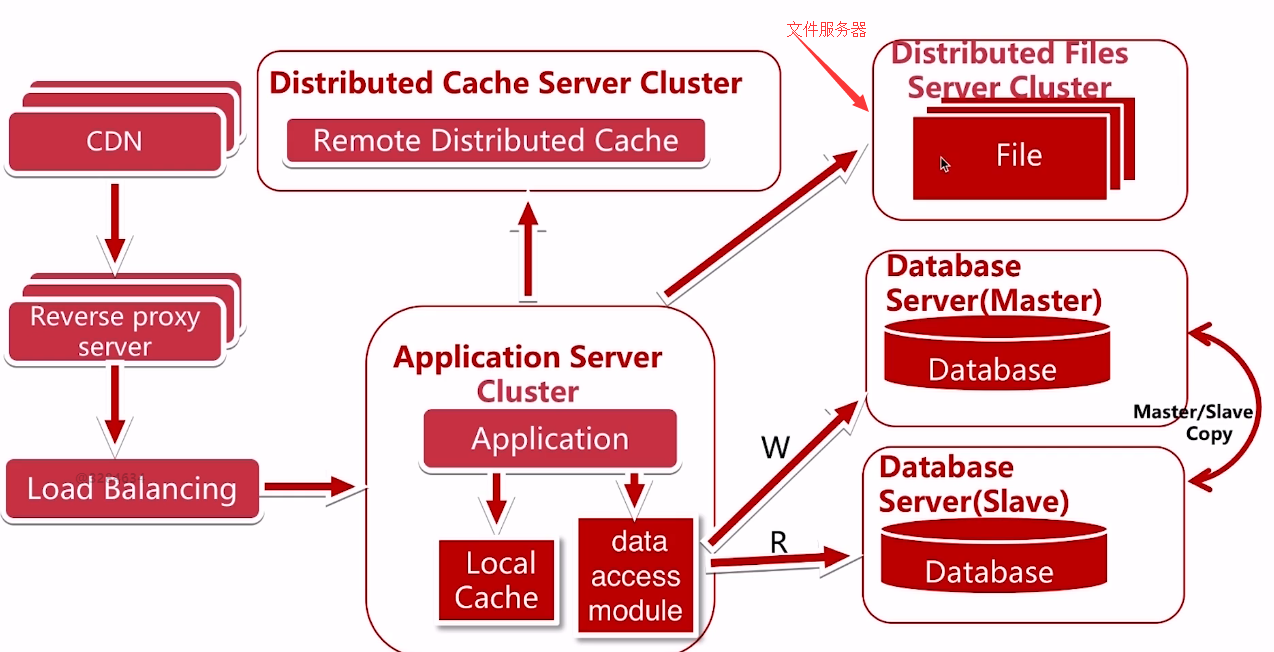
这时候文件服务器又出现了瓶颈
把文件服务器改成了分布式文件服务器集群
要考虑的问题:如何不影响已经部署在线上的访问

现在服务器又出现瓶颈了,我们选择专库专用的方式,进行数据的垂直拆分,相关的业务都有自己的一个库,解决写数据并发量大的问题
当我们把这些表拆分成不同的库又会带来哪些新问题呢?
跨业务、跨库的事务,我们该如何解决?分布式事务、去掉事务、不追求强事务
随着业务量的增加,单个库又出现了瓶颈,我们就把单个库进行水平拆分
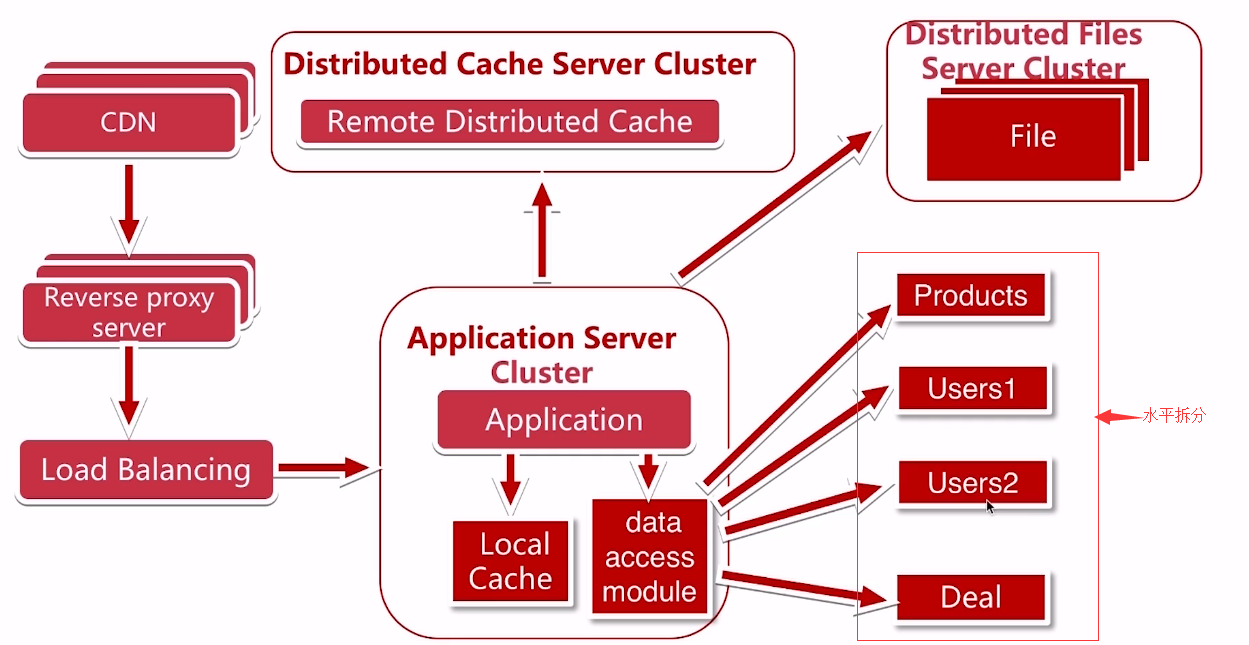
SQL路由的问题:某个用户,我们要知道是在user1还是user2中;因为分库了,主键的策略也有有所不同;同时也面临分页的问题,当我们要查询2018年的数据,数据分布在1和2中,要想展示,就需要分页
我们发现应用服务器上的搜索量又飙升
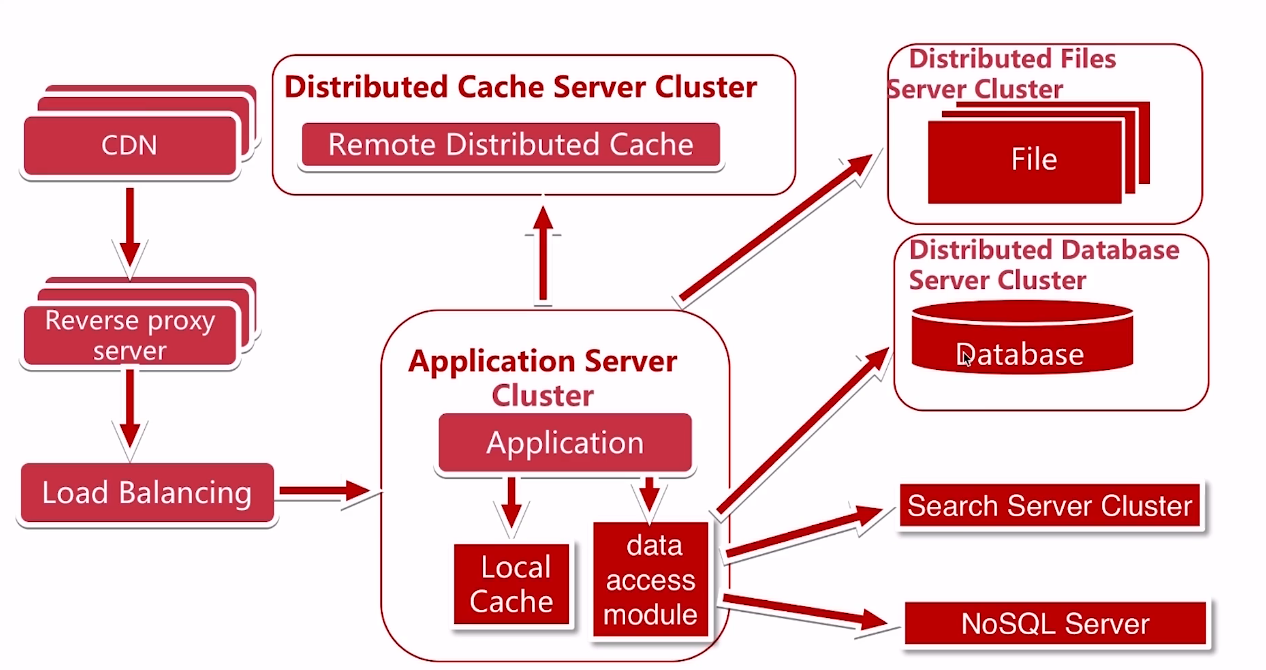
我们把应用服务器中的搜索功能单独抽取出来(Search Server Cluster)做了一个搜索引擎,同时部分场景可以使用NoSQL提高性能
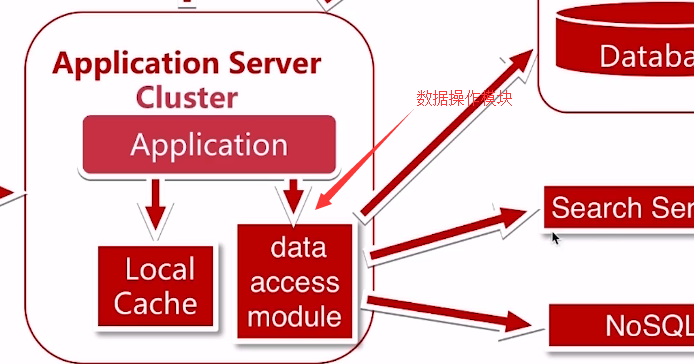
数据统一的访问模块(data access module),解决上层数据开发的数据源问题
