将最近看过的CV文章做个概要,包括行人检测(pedestrian detection) 和 行人再识别(pedestrian re-identification),按时间来排序:
[1] Rodrigo Benenson, Mohamed Omran, Jan Hosang, Bernt Schiele. Ten Years of Pedestrian Detection, What Have We Learned ? In ECCV, CVRSUAD workshop, 2014. 1,2,3,4,5,6,7,8
这篇文章回顾了过去十年,pedestrian detection 的发展状况: 过去十年提出的算法,几个重要的benchmark。把主流的算法分成三类: DF、DPM、DN。DF就是用decision forests的方法,比如SquaresChnFtrs,DPM就是 Deformable part model,DN就是 deep network。大体算是三种technique吧,虽然里面会有一些算法是杂糅了别的technique的。做了四个实验:
实验一: Reviewing the effect of features
过程: 在这十年间提出来的算法中,挑出若干进行实验(挑出的这些方法,使用的特征越来越复杂,越来越多)。
结论: 说明,这些算法的提升,很大程度上依赖于使用了更好的特征。

实验二: Complementarity of approaches
过程: 以SquaresChnFtrs为基准算法,添加一些techniques得到一些变种: +DCT/SDt/2Ped... 顺带提出了一种新的算法: Katamari-v1 = SquaresChnFtrs + DCT + SDt + 2Ped,该方法也是截止到这篇论文发表的时候,最好的detector了。DCT的处理在论文4.1节第三段详细提及;SDt使用了optical flow;2Ped使用了context。
结论: 把这些techniques杂糅在一个方法上,有较大的提升。而且多techniques的算法相对于原SquareChnFtrs的提升与各technique相对于原SquareChnFtrs的提升之和比较接近。说明这些techniques/approaches的互补性比较强。但是可能还可以进一步提炼出更纯粹的技巧。

实验三: How much capacity is needed ?
过程: 把训练好的模型扩展到测试集上,是非常重要。那么这对训练集有什么要求呢。让一些方法使用 Caltech / INRIA 训练集训练,然后在Caltech 测试集上跑,并比较。
结论: 在Caltech训练集上训练的方法的performance 明显比在 INRIA训练集上训练的方法的performance要好。主要体现在 SquareChnFtrs(I) 和 SquareChnFtrs(C) 的对比上。个人觉得比较的样本太少,存疑。

实验四: Generalisation across datasets
过程: 用不同的训练集训练(INRIA、Caltech、KITTI),然后用不同的测试集测试(INRIA、Caltech、KITTI、ETH),KITTI的performance是用AUC衡量的,越高越好,其他的benchmark的performance是用MR衡量的,越低越好。另外还测试了一个SquareChnFtrs的变种SquareICF方法在KITTI上的performance,还不错。
结论: 使用的INRIA训练的模型,在各个测试集上都表现良好,两个第1(INRIA、ETH),两个第二(Caltech、KITTI);只要方法好,在不同的benchmark上的表现都是稳定的。


结论: 这篇论文倾向于认为,好的特征和技巧对于提升行人检测方法的性能至关重要,而且这些特征大部都是经过人工反复实验(hand-crated with trial and error)得到的。实验大头是使用将多种特征、技巧加在SquaresChnFtrs上,得到performance很好的Katamari-v1方法。对deep networks的方法讨论极少。而下面的论文[3]使用的network以raw pixels作为输入,由网络自行学习特征,不使用人工的特征,实验得到很好的performance !
[2] Ejaz Ahmed, Michael Jones, Tim K.Marks. An Improved Deep Learning Architecture for Person Re-Identification. In CVPR 2015.
改变神经网络的架构,提高在benchmark上的performance 使用dnn来做行人再识别(pedestrian re-identification),引入了两个新的layer—Cross-Input Neighborhood Differences layer、Across Patch Features layer。前者用于比较输入的两幅feature map。并按定义的公式算出两种“differences”,后者用于把两种differences整合起来,变成更高阶的,用于衡量两幅图相似度的特征图。
benchmark: CUHK01、CUHK03、VIPeR。
取得的实验结果:
Our method significantly outperforms the state of the art on both a large data set (CUHK03) and a medium-sized data set (CUHK01), and is resistant to overfitting. We also demonstrate that by initially training on an unrelated large data set before fine-tuning on a small target data set, our network can achieves results comparable to the state of the art even on a small data set (VIPeR).
网络结构图如下:

[3] Jan Hosang, Mohamed Omran, Rodrigo Benenson, Bernt Schiele. Taking a Deeper Look at Pedestrians. In CVPR 2015.
以往用于行人检测(pedestrian detection)的dnn,除了Yann Lecun等人提出的ConvNet之外,大都依赖人工特征(hand-crafted features),如HOG什么的。 这些dnn(除了ConvNet)的提出者,对原始cnn的拓扑进行了修改,以适应他们的模型思想。
这篇paper使用没有修改拓扑的naive的CNN进行实验,发现经过训练后,在测试的时候,其 performance比 1)经过“特化”的CNN(如SDN) 2)以及大多数非CNN方法(如ACF、SCF)要好。
paper里边使用了一大一小的dnn,大的为“AlexNet”,(使用caffe框架自带的R-CNN来实现),小的用CifarNet(caffe里也有)。默认使用的detection proposals来自SquaresChnFtrs (这是Caltech上开放源代码的最好的检测算法了),默认的网络输入是raw RGB image。另外,还对一些参数(如training batch、 model window size、Number and type of layers...)的设置进行讨论,选用较好的参数,用在主要的实验里边。
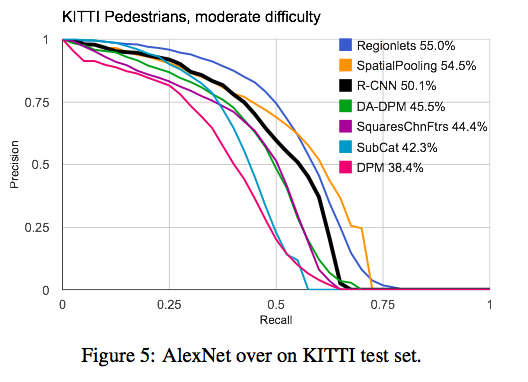
benchmark: Caltech1x、Caltech10x、KITTI。
部分实验结果:
仅使用Caltech1x训练的CifarNet在Caltech1x上的表现仅次于使用decision forests的SpatialPooling,前者的MR是30.7%,后者的MR是29.2%;
仅使用Caltech1x训练的AlexNet的MR是32.4%,不及CifarNet;
在single-frame-detector(不算光流方法)中,仅使用Caltech10x训练的AlexNet在Caltech10x上的表现仅次于LDCF,前者为27.5%,后者为24.8%;
AlexNet是第一个在KITTI上测试的dnn,获得50.1%的AP(average precision),次于Regionlets的55.0%和SpatialPooling的54.5%。
部分图表如下: