ceph简介
不管你是想为云平台提供Ceph 对象存储和/或 Ceph 块设备,还是想部署一个 Ceph 文件系统或者把 Ceph 作为他用,所有 Ceph 存储集群的部署都始于部署一个个 Ceph 节点、网络和 Ceph 存储集群。 Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。
- Ceph OSDs: Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数)。
- Monitors: Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
- MDSs: Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令
Ceph组件:osd
- OSD 守护进程,至少两个
- 用于存储数据、处理数据拷贝、恢复、回滚、均衡
- 通过心跳程序向monitor提供部分监控信息
- 一个ceph集群中至少需要两个OSD守护进程
Ceph组件:mon
- 维护集群的状态映射信息
- 包括monitor、OSD、placement Group(PG)
- 还维护了monitor、OSD和PG的状态改变历史信息
Ceph组件:mgr(新功能)
- 负责ceph集群管理,如pg map
- 对外提供集群性能指标(如cpeh -s 下IO信息)
- 具有web界面的监控系统(dashboard)
ceph逻辑结构
数据通过ceph的object存储到PG,PG在存储到osd daemon,osd对应disk
object只能对应一个pg
一个raid可以对应一个osd
一整块硬盘可以对应一个osd
一个分区可以对应一个osd
monitor:奇数个 osd : 几十到上万,osd越多性能越好
pg概念
- 副本数
- crush规则(pg怎么找到osd acting set)
- 用户及权限
- epoach:单调递增的版本号
- acting set: osd列表,第一个为primary osd,replicated osd
- up set :acting set过去的版本
- pg tmp:临时pg组
osd状态:默认每2秒汇报自己给mon(同时监控组内osd,如300秒没有给mon汇报状态,则会把这个osd踢出pg组)
- up 可以提供io
- down 挂掉了
- in 有数据
- out 没数据了
ceph应用场景:通过tgt支持iscsi挂载
- 公司内部文件共享
- 海量文件,大流量,高并发
- 需要高可用、高性能文件系统
- 传统单服务器及NAS共享难以满足需求,如存储容量,高可用
ceph生产环境推荐
- 存储集群采用全万兆网络
- 集群网络(不对外)与公共网络分离(使用不同网卡)
- mon、mds与osd分离部署在不同机器上
- journal推荐使用PCI SSD,一般企业级IOPS可达40万以上
- OSD使用SATA亦可
- 根据容量规划集群
- 至强E5 2620 V3或以上cpu,64GB或更高内存
- 最后,集群主机分散部署,避免机柜故障(电源、网络)
ceph安装环境
由于机器较少,使用3台机器,充当mon与osd,生产环境不建议,生产环境至少3个mon独立
| 主机 | IP | 角色 | 配置 |
| ceph-0 |
eth0:192.168.0.150(Public) eth1:172.16.1.100(Cluster) |
mon、osd、mgr | DISK 0 15G(OS) DISK 1 10G(Journal) DISK 2 10G(OSD) DISK 3 10G(OSD) |
| ceph-1 |
eth0:192.168.0.151(Public) eth1:172.16.1.101(Cluster) |
mon、osd、mgr | DISK 0 15G(OS) DISK 1 10G(Journal) DISK 2 10G(OSD) DISK 3 10G(OSD) |
| ceph-2 |
eth0:192.168.0.152(Public) eth1:172.16.1.102(Cluster) |
mon、osd、mgr | DISK 0 15G(OS) DISK 1 10G(Journal) DISK 2 10G(OSD) DISK 3 10G(OSD) |
一、系统设置
1.绑定主机名
由于后续安装及配置都涉及到主机名,故此需先绑定
依次在三个节点上执行以下命令完成hosts绑定
[root@ceph-node0 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.0.150 ceph-node0 192.168.0.151 ceph-node1 192.168.0.152 ceph-node2
2.ssh-keygen信任
3. 每台关闭防火墙
systemctl stop firewalld
4.时间同步
yum install -y ntpdate // ntpdate cn.pool.ntp.org
5.安装epel源与ceph-deploy
本步骤要在每一个节点上执行
- 安装epel源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
- 安装ceph-deploy
rpm -ivh https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-luminous/el7/noarch/ceph-release-1-1.el7.noarch.rpm
-
替换 ceph.repo 服务器
sed -i 's#htt.*://download.ceph.com#https://mirrors.tuna.tsinghua.edu.cn/ceph#g' /etc/yum.repos.d/ceph.repo
或直接复制下方文本内容替换 /etc/yum.repos.d/ceph.repo
[Ceph] name=Ceph packages for $basearch baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-luminous/el7/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc [Ceph-noarch] name=Ceph noarch packages baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-luminous/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-luminous/el7/SRPMS enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
6.安装ceph
-
使用 yum 安装 ceph-deploy
[root@ceph-node0 ~]# yum install -y ceph-deploy
-
创建 ceph-install 目录并进入,安装时产生的文件都将在这个目录
[root@ceph-node0 ~]# mkdir ceph-install && cd ceph-install [root@ceph-node0 ceph-install]#
二、准备硬盘
1.Journal磁盘
本步骤要在每一个节点上执行
在每个节点上为Journal磁盘分区, 分别为 sdb1, sdb2, 各自对应本机的2个OSD, journal磁盘对应osd的大小为25%
-
使用 parted 命令进行创建分区操作
[root@ceph-node0 ~]# parted /dev/sdb mklabel gpt mkpart primary xfs 0% 50% mkpart primary xfs 50% 100% q
2.OSD磁盘
-
对于OSD磁盘我们不做处理,交由ceph-deploy进行操作
三、安装ceph
1.使用ceph-deploy安装ceph,以下步骤只在ceph-depoly管理节点执行
-
创建一个ceph集群,也就是Mon,三台都充当mon
[root@ceph-node0 ceph-install]# ceph-deploy new ceph-node0 ceph-node1 ceph-node2
-
在全部节点上安装ceph
[root@ceph-node0 ceph-install]# ceph-deploy install ceph-node0 ceph-node1 ceph-node2 或在每个节点上手动执行 yum install -y ceph
-
创建和初始化监控节点并收集所有的秘钥
[root@ceph-node0 ceph-install]# ceph-deploy mon create-initial
此时可以在osd节点查看mon端口

-
创建OSD存储节点
[root@ceph-node0 ceph-install]# ceph-deploy osd create ceph-node0 --data /dev/sdc --journal /dev/sdb1 [root@ceph-node0 ceph-install]# ceph-deploy osd create ceph-node0 --data /dev/sdd --journal /dev/sdb2 [root@ceph-node0 ceph-install]# ceph-deploy osd create ceph-node1 --data /dev/sdc --journal /dev/sdb1 [root@ceph-node0 ceph-install]# ceph-deploy osd create ceph-node1 --data /dev/sdd --journal /dev/sdb2 [root@ceph-node0 ceph-install]# ceph-deploy osd create ceph-node2 --data /dev/sdc --journal /dev/sdb1 [root@ceph-node0 ceph-install]# ceph-deploy osd create ceph-node2 --data /dev/sdd --journal /dev/sdb2
-
把配置文件和admin 秘钥到管理节点和ceph节点
[root@ceph-0 ceph-install]# ceph-deploy --overwrite-conf admin ceph-node0 ceph-node1 ceph-node2
-
使用 ceph -s 命令查看集群状态
[root@ceph-node0 ceph-install]# ceph -s cluster: id: e103fb71-c0a9-488e-ba42-98746a55778a health: HEALTH_WARN no active mgr services: mon: 3 daemons, quorum ceph-node0,ceph-node1,ceph-node2 mgr: no daemons active osd: 6 osds: 6 up, 6 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0B usage: 0B used, 0B / 0B avail pgs:
如集群正常则显示 health HEALTH_OK
如OSD未全部启动,则使用下方命令重启相应节点, @ 后面为 OSD ID
systemctl start ceph-osd@0
2. 部署mgr
-
luminous 版本需要启动 mgr, 否则 ceph -s 会有 no active mgr 提示
-
官方文档建议在每个 monitor 上都启动一个 mgr
[root@ceph-node0 ceph-install]# ceph-deploy mgr create ceph-node0:ceph-node0 ceph-node1:ceph-node1 ceph-node2:ceph-node2
-
再次查看ceph状态
[root@ceph-node0 ceph-install]# ceph -s cluster: id: e103fb71-c0a9-488e-ba42-98746a55778a health: HEALTH_OK services: mon: 3 daemons, quorum ceph-node0,ceph-node1,ceph-node2 mgr: ceph-node0(active), standbys: ceph-node1, ceph-node2 osd: 6 osds: 6 up, 6 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0B usage: 6.02GiB used, 54.0GiB / 60.0GiB avail pgs:
3.清除操作
-
安装过程中如遇到奇怪的错误,可以通过以下步骤清除操作从头再来
[root@ceph-node0 ceph-install]# ceph-deploy purge ceph-node0 ceph-node1 ceph-node2 [root@ceph-node0 ceph-install]# ceph-deploy purgedata ceph-node0 ceph-node1 ceph-node2 [root@ceph-node0 ceph-install]# ceph-deploy forgetkeys
四、配置
1. 为何要分离网络
-
性能
OSD 为客户端处理数据复制,复制多份时 OSD 间的网络负载势必会影响到客户端和 ceph 集群 的通讯,包括延时增加、产生性能问题;恢复和重均衡也会显著增加公共网延时。
-
安全
很少的一撮人喜欢折腾拒绝服务攻击(DoS)。当 OSD 间的流量瓦解时, 归置组再也不能达到 active+clean 状态,这样用户就不能读写数据了。挫败此类攻击的一种好方法是 维护一个完全独立的集群网,使之不能直连互联网;另外,请考虑用签名防止欺骗攻击。
2.分离公共网络和集群网络(推荐、可选)
-
按下方所列修改配置文件 ceph.conf (在目录 ~/ceph-install 下操作,注意替换 fsid )
[global] # 注意替换 fsid fsid = dca70270-3292-4078-91c3-1fbefcd3bd62 mon_initial_members = ceph-node0, ceph-node1, ceph-node2 mon_host = 192.168.0.150,192.168.0.151,192.168.0.152 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx public network = 192.168.0.0/24 cluster network = 172.16.1.0/24 [mon.a] host = ceph-node0 mon addr = 192.168.0.150:6789 [mon.b] host = ceph-node1 mon addr = 192.168.0.151:6789 [mon.c] host = ceph-node2 mon addr = 192.168.0.152:6789 [osd] osd data = /var/lib/ceph/osd/ceph-$id osd journal size = 20000 osd mkfs type = xfs osd mkfs options xfs = -f filestore xattr use omap = true filestore min sync interval = 10 filestore max sync interval = 15 filestore queue max ops = 25000 filestore queue max bytes = 10485760 filestore queue committing max ops = 5000 filestore queue committing max bytes = 10485760000 journal max write bytes = 1073714824 journal max write entries = 10000 journal queue max ops = 50000 journal queue max bytes = 10485760000 osd max write size = 512 osd client message size cap = 2147483648 osd deep scrub stride = 131072 osd op threads = 8 osd disk threads = 4 osd map cache size = 1024 osd map cache bl size = 128 osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier" osd recovery op priority = 4 osd recovery max active = 10 osd max backfills = 4 [client] rbd cache = true rbd cache size = 268435456 rbd cache max dirty = 134217728 rbd cache max dirty age = 5
-
将配置文件同步到其它节点
[root@ceph-node0 ceph-install]# ceph-deploy --overwrite-conf admin ceph-node0 ceph-node1 ceph-node2
-
逐一重启各个节点
systemctl restart ceph*.service ceph*.target
-
此时
ceph-mon 进程应监听在 192.168.0.0 网段IP上 ceph-osd 应分别监听在 192.168.0.0 和 172.16.1.0 两个网段IP上 172.16.1.0 网段为集群内部复制数据时使用 192.168.0.0 网段为客户端连接时使用
[root@ceph-node2 ~]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 172.16.1.102:6800 0.0.0.0:* LISTEN 55794/ceph-osd
tcp 0 0 192.168.0.152:6800 0.0.0.0:* LISTEN 55794/ceph-osd
tcp 0 0 192.168.0.152:6801 0.0.0.0:* LISTEN 55794/ceph-osd
tcp 0 0 172.16.1.102:6801 0.0.0.0:* LISTEN 55794/ceph-osd
tcp 0 0 172.16.1.102:6802 0.0.0.0:* LISTEN 55792/ceph-osd
tcp 0 0 192.168.0.152:6802 0.0.0.0:* LISTEN 55792/ceph-osd
tcp 0 0 192.168.0.152:6803 0.0.0.0:* LISTEN 55792/ceph-osd
tcp 0 0 172.16.1.102:6803 0.0.0.0:* LISTEN 55792/ceph-osd
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 1981/dnsmasq
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1713/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 1716/cupsd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1814/master
tcp 0 0 192.168.0.152:6789 0.0.0.0:* LISTEN 55663/ceph-mon
tcp6 0 0 :::22 :::* LISTEN 1713/sshd
tcp6 0 0 ::1:631 :::* LISTEN 1716/cupsd
tcp6 0 0 ::1:25 :::* LISTEN 1814/master
- 查看osd与ceph状态
[root@ceph-node0 ceph-install]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.05878 root default -3 0.01959 host ceph-node0 0 hdd 0.00980 osd.0 up 1.00000 1.00000 1 hdd 0.00980 osd.1 up 1.00000 1.00000 -5 0.01959 host ceph-node1 2 hdd 0.00980 osd.2 up 1.00000 1.00000 3 hdd 0.00980 osd.3 up 1.00000 1.00000 -7 0.01959 host ceph-node2 4 hdd 0.00980 osd.4 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 // [root@ceph-node0 ceph-install]# ceph -s cluster: id: e103fb71-c0a9-488e-ba42-98746a55778a health: HEALTH_WARN 1/3 mons down, quorum ceph-node0,ceph-node1 services: mon: 3 daemons, quorum ceph-node0,ceph-node1, out of quorum: ceph-node2 mgr: ceph-node0(active), standbys: ceph-node2, ceph-node1 osd: 6 osds: 6 up, 6 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0B usage: 6.03GiB used, 54.0GiB / 60.0GiB avail pgs:
五、Ceph 存储池与文件系统
1.创建文件系统ceph-fs
ceph-fs需要元数据mds服务
-
创建mds,osd上都创建,高可用性
[root@ceph-node0 ceph-install]# ceph-deploy mds create ceph-node0 ceph-node1 ceph-node2
- 上方命令会在 ceph-node0 和 ceph-node1 上启动MDS
2.pool 存储池
-
查看存储池
root@ceph-node0 ceph-install]# ceph osd pool ls
-
创建存储池
[root@ceph-node0 ceph-install]# ceph osd pool create data_data 32 pool名称:data_data pg数:32
3.创建ceph-fs文件系统
- 查看已有的文件系统
[root@ceph-node0 ceph-install]# ceph fs ls
- 创建一个名称为data的文件系统
[root@ceph-node0 ceph-install]# ceph osd pool create data_data 32 [root@ceph-node0 ceph-install]# ceph osd pool create data_metadata 32 [root@ceph-node0 ceph-install]# ceph fs new data data_metadata data_data
-
使用客户端 ceph-fuse 挂载文件系统
[root@ceph-mon yum.repos.d]# yum install -y ceph-fuse
- 客户端创建目录挂载文件系统
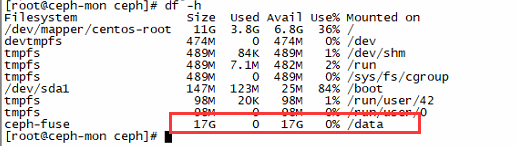
// 创建data录目 [root@ceph-mon ~]# mkdir /data // 挂载 root@ceph-mon ~]# ceph-fuse -m 192.168.0.150,192.168.0.151,192.168.0.152:6789 /data
挂载时出现如下错误:

说明认证配置找不到,把管理节点上的ceph.conf拷到客户端
[root@ceph-node0 ceph-install]# scp ceph.conf 192.168.0.153:/etc/ceph/ //从Ceph集群复制 ceph.conf 与 ceph.client.admin.keyring 文件到客户端 /etc/ceph 目录下 [root@ceph-node0 ceph-install]# cat ceph.client.admin.keyring [client.admin] key = AQB8wL5bnutGMBAAg5+eadh1fNShOG5d8mERIg== // 在客户端创建ceph.keyring,为在管理节点创建的用户 [root@ceph-mon ceph]# cat ceph.keyring [client.admin] key = AQB8wL5bnutGMBAAg5+eadh1fNShOG5d8mERIg==