其他
1. 在html中导入static文件时,自定义的往后放,减小其效果被覆盖风险
2. 若执行makemigrations/ migrate命令出现问题,推荐检查下migrations文件(app下的migrations和External Libraries中的migrations);如果删库或者删了表,一定要记得清空对应migrations下的py文件
3.备注很重要
4. 初学Django项目可能会遇到的问题:https://www.cnblogs.com/liwenzhou/p/9255813.html
5. 重要的操作(与数据库相关的)放在前面
def balabala(request):
if request.method == 'POST':
pass
return render(request,'asas.html')
6.取a的布尔值!!a
7. console时以下设置,可保证调试时缓存对测试结果零干扰

day1 (2 Jul 18)
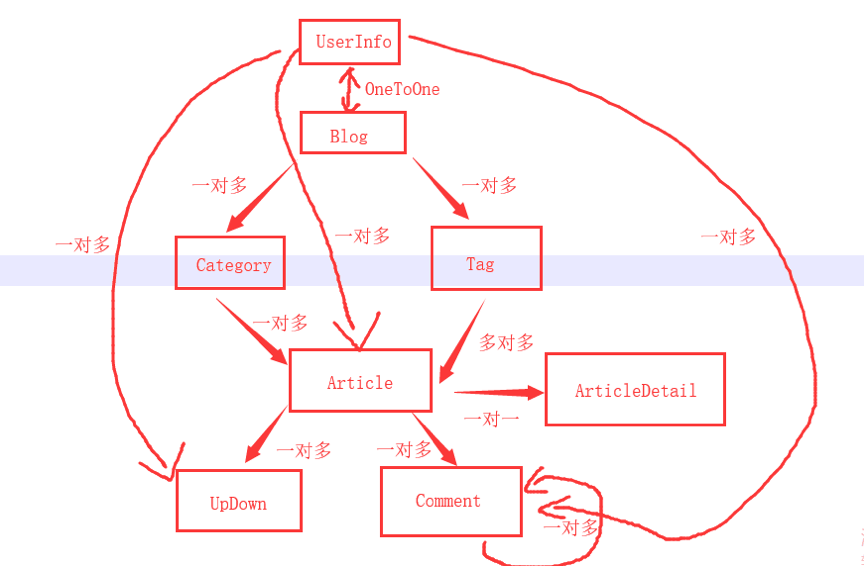
一、表结构的设计
1. models.py
2. settings.py
3. __init__.py
# blog(app) -> models.py
1. category和blog/user多对一
#不要将category和article绑定,有可能存在用户新建一个category,里面还没有绑定任何文章
2. tag和blog多对一
# 原因同上
3. 将文章分为两个表:Article和ArticleDetail
# article的标题,描述等的被搜索概率远远大于article的内容.将两部分分开一对一关联,可以提高搜索性能
4. comment: parent_comment = models.ForeignKey("self", null=True)
# 如果是评论文章,null为True,如果是评论评论,参数为所评论的评论
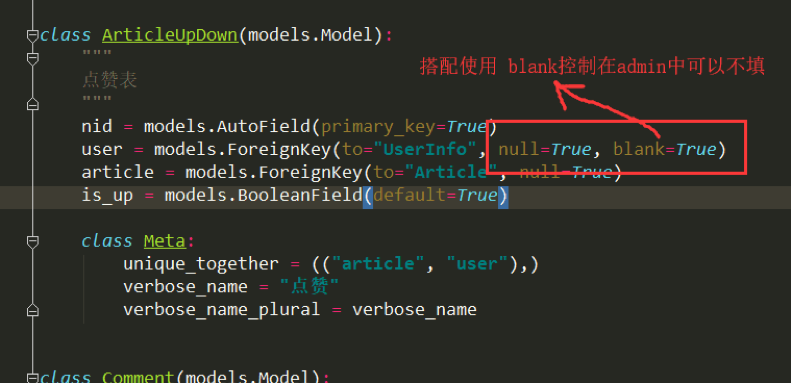
5. ArticleUpDown: unique_together = (("article", "user"),)
# 在点赞/踩表中,文章和用户联合唯一
6. Article表中加入comment_count, up_count, down_count字段。方便直接正向查询
7. 为用到django提供的auth认证,UserInfo要继承AbstractUser
from django.contrib.auth.models import AbstractUser
8. 共九张表(八张主表,一张关系表ArticleToTag)
9. parent_comment = models.ForeignKey("self", null=True, blank=True)
# null=True, 数据库中该字段可以为空;blank=True,用django的admin时,该字段可以不传值
from django.db import models
from django.contrib.auth.models import AbstractUser
class UserInfo(AbstractUser):
"""
用户信息表
"""
nid = models.AutoField(primary_key=True)
phone = models.CharField(max_length=11, null=True, unique=True)
avatar = models.FileField(upload_to="avatars/", default="avatars/default.png")
blog = models.OneToOneField(to="Blog", to_field="nid", null=True)
def __str__(self):
return self.username
class Meta:
verbose_name = "用户信息"
verbose_name_plural = verbose_name
class Blog(models.Model):
"""
博客信息
"""
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=64) # 个人博客标题
theme = models.CharField(max_length=32) # 博客主题
def __str__(self):
return self.title
class Meta:
verbose_name = "博客"
verbose_name_plural = verbose_name
class Category(models.Model):
"""
个人博客文章分类
"""
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=32) # 分类标题
blog = models.ForeignKey(to="Blog", to_field="nid") # 外键关联博客,一个博客站点可以有多个分类
def __str__(self):
return "{}-{}".format(self.blog.title, self.title)
class Meta:
verbose_name = "文章分类"
verbose_name_plural = verbose_name
class Tag(models.Model):
"""
标签
"""
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=32) # 标签名
blog = models.ForeignKey(to="Blog", to_field="nid") # 所属博客
def __str__(self):
return self.title
class Meta:
verbose_name = "标签"
verbose_name_plural = verbose_name
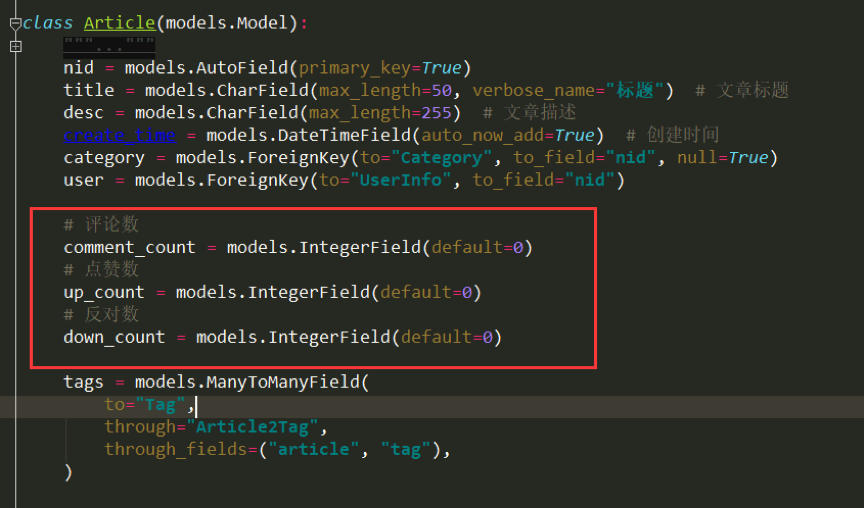
class Article(models.Model):
"""
文章
"""
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=50, verbose_name="标题") # 文章标题
desc = models.CharField(max_length=255) # 文章描述
create_time = models.DateTimeField(auto_now_add=True) # 创建时间
category = models.ForeignKey(to="Category", to_field="nid", null=True)
user = models.ForeignKey(to="UserInfo", to_field="nid")
# 评论数
comment_count = models.IntegerField(default=0)
# 点赞数
up_count = models.IntegerField(default=0)
# 反对数
down_count = models.IntegerField(default=0)
tags = models.ManyToManyField(
to="Tag",
through="Article2Tag",
through_fields=("article", "tag"),
)
def __str__(self):
return self.title
class Meta:
verbose_name = "文章"
verbose_name_plural = verbose_name
class ArticleDetail(models.Model):
"""
文章详情表
"""
nid = models.AutoField(primary_key=True)
content = models.TextField()
article = models.OneToOneField(to="Article", to_field="nid")
class Meta:
verbose_name = "文章详情"
verbose_name_plural = verbose_name
class Article2Tag(models.Model):
"""
文章和标签的多对多关系表
"""
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(to="Article", to_field="nid")
tag = models.ForeignKey(to="Tag", to_field="nid")
def __str__(self):
return "{}-{}".format(self.article, self.tag)
class Meta:
unique_together = (("article", "tag"),)
verbose_name = "文章-标签"
verbose_name_plural = verbose_name
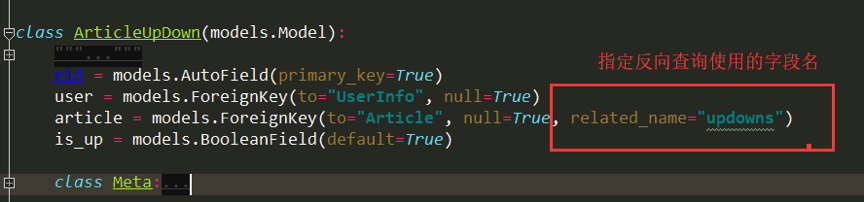
class ArticleUpDown(models.Model):
"""
点赞表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey(to="UserInfo", null=True)
article = models.ForeignKey(to="Article", null=True)
is_up = models.BooleanField(default=True)
class Meta:
unique_together = (("article", "user"),)
verbose_name = "点赞"
verbose_name_plural = verbose_name
class Comment(models.Model):
"""
评论表
"""
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(to="Article", to_field="nid")
user = models.ForeignKey(to="UserInfo", to_field="nid")
content = models.CharField(max_length=255) # 评论内容
create_time = models.DateTimeField(auto_now_add=True)
parent_comment = models.ForeignKey("self", null=True, blank=True)
def __str__(self):
return self.content
class Meta:
verbose_name = "评论"
verbose_name_plural = verbose_name
# verbase_name 设置翻译名

# bbs -> settings.py
1. AUTH_USER_MODEL = "blog.UserInfo" # 指定一下认证使用 自定义的UserInfo表
2. 注册static, 并将常用static文件拷到本地
STATICFILES_DIRS = [os.path.join(BASE_DIR,'static']
3. 配置database (先建一个database,然后指定用该数据库)
# 执行manage.py Task 命令
1. makemigrations
2. migrate
3. createsuperuser
# bbs -> __init__.py (settings.py同目录下)
import pymysql
pymysql.install_as_MySQLdb()
二、登陆功能实现
1. urls.py
2. forms.py
3. login.html, index.html
4. views.py (login, v_code, index)
# bbs -> urls.py
1. 添加以下路由
url(r'^login/',views.login),
url(r'^v_code/',views.v_code),
url(r'^index/',views.index),
# blog -> forms.py
1. 注册表格(class LoginForm)
# templates -> login.html
1. $(document).ready(function(){})的使用
2. 给提交按钮绑定动作(ajax)
3. 出现错误后,input框获取光标后,提示错误信息隐藏
4. 点击二维码,生成另一个随机数 (注意,要和views.py中的never_cache装饰器配合使用,以屏蔽浏览器缓存导致的在两个随机验证码之间来回切换的不良效果)
a. JS正则的两种方式
1)var r1 = new RegExp("[?]$")
2)/[?]$/
if (/[?]$/.test(OUrl)){}
# blog -> views.py
1. auth功能的使用
from django.contrib import auth
user = auth.authenticate(username = username, password =password)
auth.login(request,user)
2. 判断v_code是否一致
v_code = request.POST.get('v_code','')
if v_code.upper() == request.session.get('v_code',''):
3. never_cache 装饰器
from django.views.decorations.cache import never_cache
@never_cache
def v_code(request):
pass
4. pillow模块from PIL import Image, ImageDraw, ImageFont(详见下def v_code(request): )
# 使用前先安装
pip3 install pillow
pip3 install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
from PIL import Image,ImageDraw,ImageFont
5. BytesIO模块(详见下def v_code(request): )
from io import BytesIO
6. choice([a,b,c])
7. 基本款随机验证码的生成
@never_cache
def v_code(request):
from PIL import Image,ImageDraw,ImageFont
import random
def get_color():
return random.randint(0,255),random.randint(0,255),random.randint(0,255)
image_obj = Image.new(
'RGB',
(250,35),
color=get_color(),
)
draw_obj = ImageDraw.Draw(image_obj)
font_obj = ImageFont.truetype(font='static/font/kumo.ttf',size=28)
tmp_list = []
for i in range(5):
n = str(random.randint(0,9))
u = chr(random.randint(65,90))
l = chr(random.randint(97,122))
a = random.choice([n,u,l]) # choice([a,b,c]) 列表!
draw_obj.text(
(i*48+20,0),
a,
get_color(),
font=font_obj
)
tmp_list.append(a)
v_code_string =''.join(tmp_list)
request.session['v_code'] = v_code_string.upper()
from io import BytesIO
tmp = BytesIO() # 相当于一个句柄
image_obj.save(tmp,'png')
data = tmp.getvalue()
return HttpResponse(data,content_type='image/png')
# content_type = 'image/png'
8. 升级版随机二维码(加干扰线,滑动二维码)(扩展内容;见演示代码)
day2 (3 Jul 18)
一、注册功能
1. settings.py
2. urls.py
3. forms.py
4. reg.html
5. views.py (reg)
# bbs -> settings.py
1. 配置media: 用户上传的文件等
MEDIA_URL = "/media/"
MEDIA_ROOT = os.path.join(BASE_DIR, "media")
# bbs -> urls.py
1. 配置路由reg
url(r'^reg/',views.reg),
2. 配置media路由
from django.conf import settings
from django.views.static import serve
url(r'^media/(?P<path>.*)$', serve, {"document_root": settings.MEDIA_ROOT})
# blog -> forms.py
1. 手机号正则
from django.core.validators import RegexValidator
validators=[RegexValidator(r'1[356789][0-9]{9}','invalid phone number')],
2. 局部钩子(用户名校验)def clean_username(self):
from django.core.exceptions import ValidationError
def clean_username(self):
value = self.cleaned_data.get('username','')
if 'jpm' in value:
raise ValidationError('invalid username')
elif models.UserInfo.objects.filter(username=value):
raise ValidationError('the username has been occupied')
else:
return value
3. 全局钩子(两次密码输入一致)def clean(self):
def clean(self):
pwd = self.cleaned_data.get('password','')
re_pwd = self.cleaned_data.get('re_password','')
if pwd != re_pwd:
self.add_error('re_password','variances between these two attempts')
raise ValidationError('variances between these two attempts')
else:
return self.cleaned_data
# templates -> reg.html
1. avatar html设计
<div class="form-group">
<label class="col-sm-2 control-label">AVATAR</label>
<div class="col-sm-10">
<input accept="image/*"type="file"class="form-control" id="id_avatar" name="avatar"style="display: none">
<label for="id_avatar"><img src="/static/img/default.png" id="show-avatar"></label>
</div>
</div>
# 注意label的用法: 点显示图标,关联隐藏的input框
accept默认为*/*, 这里accept="image/*"
2. form表单提交文件,且注意$.each(obj, function(k,v){})的用法
$('#reg-button').click(function(){
obj = new FormData();
obj.append('username', $('#id_username').val());
obj.append('password', $('#id_password').val());
obj.append('re_password', $('#id_re_password').val());
obj.append('phone', $('#id_phone').val());
obj.append('avatar', $('#id_avatar')[0].files[0]);
$.ajax({
url: '/reg/',
type: 'POST',
contentType: false,
processData: false,
data: obj,
success: function(data){
if (data.code){
var errObj = data.data;
$.each(errObj,function(k,v){
$('#id_'+k).next('.help-block').text(v[0]).parent().parent().addClass('has-error')
})
} else {
location.href = data.data
}
}
})
});
#注意ajax提交文件的用法,以及如何选中文件
注意$.each(obj, function(k,v){})的用法: 循环显示错误字段即显示错误页面
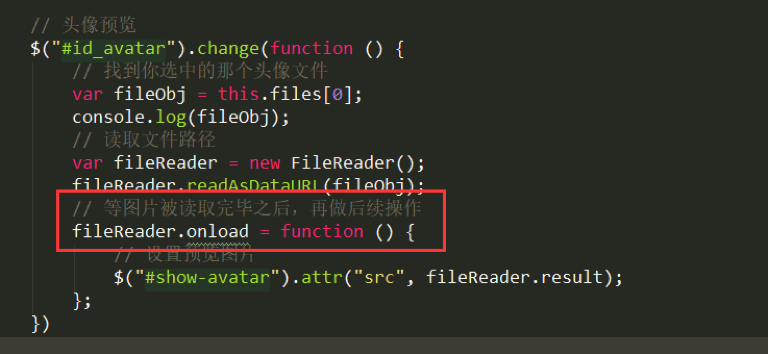
3. 头像预览(背)
$('#id_avatar').change(function(){
var fileObj = this.files[0];
fileReader = new FileReader();
fileReader.readAsDataURL(fileObj);
fileReader.onload = function(){
$('#show-avatar').attr('src',fileReader.result)
}
})
# 注意django为异步,上传文件后需要等图像读完,才能进行下一步操作fileReader.onload = function(){}
4. 出现错误后,input框获取光标后,提示错误信息隐藏
# blog -> views.py
1. bug: django中新产生的用户密码没有加密: 查看是否用了create_user()
2. def reg(request):
def reg(request):
form_obj = forms.RegForm()
if request.method == 'POST':
ret ={'code': 0}
form_obj = forms.RegForm(request.POST)
if form_obj.is_valid():
avatar_obj = request.FILES.get('avatar')
form_obj.cleaned_data.pop('re_password','')
models.UserInfo.objects.create_user(
avatar=avatar_obj,
**form_obj.cleaned_data
)
ret['data'] = '/login/'
else:
ret['code'] = 1
ret['data'] = form_obj.errors
return JsonResponse(ret)
return render(request,'reg.html',{'form_obj': form_obj})
# 注意从request中取文件的用法: avatar_obj = request.FILES.get('avatar')
注意form_obj.is_valid()验证以后,可以对form_obj.cleaned_data进行进一步操作
注意form_obj.is_valid()验证以后,可以从form_obj.errors中取出所有错误从而进行下一步操作
注意UserInfo表中无re_password字段,需要先将其弹出,才能用其他字段及avatar生成对象
注意用django的auth,一定要用create_user或create_superuser生成对象!
二、Django中logging的使用(详见代码)
# bbs -> settings.py
1.配置settings.py
BASE_LOG_DIR = os.path.join(BASE_DIR, "log")
LOGGING = {
'version': 1,
# 禁用已经存在的logger实例
'disable_existing_loggers': False,
# 定义日志 格式化的 工具
'formatters': {
'standard': {
'format': '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]'
},
'simple': {
'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
},
'collect': {
'format': '%(message)s'
}
},
# 过滤
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
# 日志处理器
'handlers': {
'console': {
'level': 'DEBUG',
'filters': ['require_debug_true'], # 只有在Django debug为True时才在屏幕打印日志
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
'default': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "info.log"), # 日志文件
'maxBytes': 1024 * 1024 * 50, # 日志大小50M
'backupCount': 3,
'formatter': 'standard',
'encoding': 'utf-8',
},
'error': {
'level': 'ERROR',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "err.log"), # 日志文件
'maxBytes': 1024 * 1024 * 50, # 日志大小50M
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
'collect': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "collect.log"),
'maxBytes': 1024 * 1024 * 50, # 日志大小50M
'backupCount': 5,
'formatter': 'collect',
'encoding': "utf-8"
}
},
# logger实例
'loggers': {
# 默认的logger应用如下配置
'': {
'handlers': ['default', 'console', 'error'], # 上线之后可以把'console'移除
'level': 'DEBUG',
'propagate': True,
},
# 名为'collect'的logger还单独处理
'collect': {
'handlers': ['console', 'collect'],
'level': 'INFO',
}
},
}
# blog -> views.py
1. 实例化logger收集信息
logger = logging.getLogger(__name__)
collect_logger = logging.getLogger('collect')
logger.info('hello,world')
collect_logger.info('hello from collect')
三、Django debug_tool_bar(详见代码)
https://www.cnblogs.com/liwenzhou/p/9245507.html
day3 (4 Jul 18)
1. admin.py
2. urls.py(两级)
3. index.html
4. left_tag.html
5. mytag.py
6. base.html
7. home.html
8. views.py
9. jxtz.css 0000.css
一、django admin的简单用法
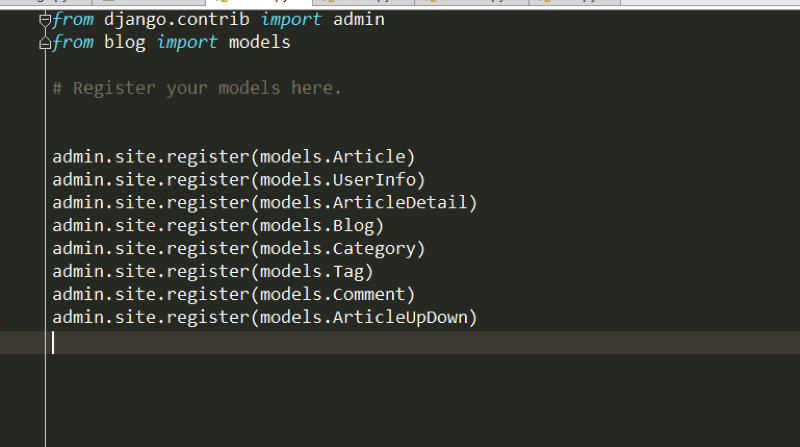
# blog -> admin.py
1. 注册需要admin操作的表
from django.contrib import admin
from blog import models
admin.site.register(models.Article)
...
# http://127.0.0.1:8000/admin/ (只有superuser可以登陆)

二、BBS首页(index)
# blog -> views.py
1. def index(request):
# templates -> index.html
1. 登陆用户和未登陆用于导航条中显示信息不同

2. 媒体对象(左头像,右简介)
# Bootstrap的组件

3. {{ request.user }}
# auth登录的逻辑
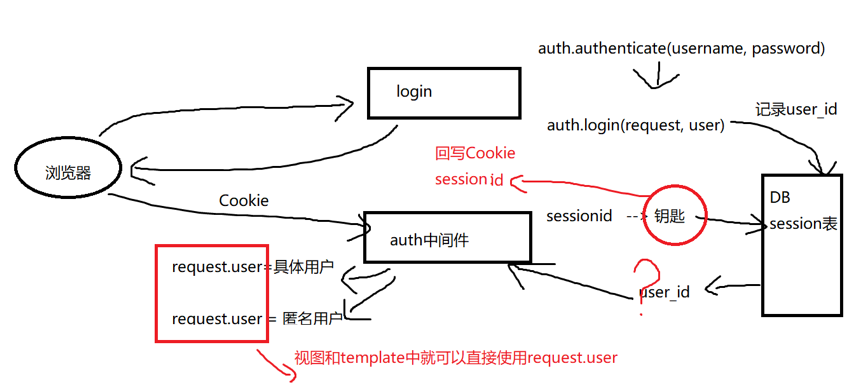
三、BBS个人主页(home)
# bbs -> urls.py (一级路由)
1. 配置一级路由
from django.conf.urls import url,include
from blog import urls as blog_urls
url(r'^logout/',views.logout),
url(r'^blog/',include(blog_urls)),
# blog -> urls.py (二级路由)
1. 配置二级路由
from django.conf.urls import url
from blog import views
urlpatterns = [url(r'^(.*)/$',views.home),]
#模糊分组匹配,得到的结果作为参数传给views中的home函数
# media -> themes -> jxtz.css / 0000.css
1. 让用户自行定义blog主题
.header { color: white;}
# templates -> base.html
1. 制定母版(home和article_derails共享): 上面header,左侧分类栏,右侧文章列表/文章详情
{% block page-main %}
{% endblock page-main %}
{% block page-js %}
{% endblock page-js %}
# templates -> home.html
1. 应用母版
{% extends 'base.html' %}
{% block page-main %}
{% endblock page-main %}
2. 文章列表同index
# blog -> views.py
1. def home(request, username): 该阶段,home函数接受两个参数
2. 因为是模糊匹配,如果模糊匹配的分组结果在数据库中无数据,返回404

day4 (5 Jul 18)
1. settings.py
2. urls.py (二级)
3. left_tag.html
4. mytag.py
5. base.html
6. article_details.html
7. views.py
一、 分类信息展示(左侧分类栏,inclusion tag)
# templates -> left_tag.html
1. orm的使用
# blog -> templatetags -> mytag.py
1. 在blog下新建一个package templatetags, 在其下建立一个py文件(mytag.py)
2. inclusion_tag的使用规范
3. orm的使用;如何获得archive_list
# 聚合和分组; 双下滑线的跨表
from django import template
from blog import models
register = template.Library()
@register.inclusion_tag('left_tag.html')
def left_panel(username):
user = models.UserInfo.objects.filter(username=username).first()
blog = user.blog
category_list = models.Category.objects.filter(blog=blog)
tag_list = models.Tag.objects.filter(blog=blog)
from django.db.models import Count
archive_list = models.Article.objects.filter(user__username=username).extra(
select={"z": "DATE_FORMAT(create_time, '%%Y-%%m')"}).values(
"z").annotate(num=Count("nid")).values("z", "num")
return {'username':username,'category_list': category_list,'tag_list':tag_list,'archive_list':archive_list}
# templates -> base.html
1. 母版中应用该inclusion_tag
{% load mytag %}
{% left_panel username %}
# 总结自定义inclusion_tag
1. app/templatetags --> (必须叫这个文件名<python package>)
2. 在上面的目录下新建py文件
3. 在上面的py文件中:
from django import template
# 生成一个注册实例,必须叫register
register = template.Library()
@register.inclusion_tag("xx.html")
def do_something(arg):
...
return {k:v, ...}
4. 在html中先导入再使用(定义完上面的 要先重启Django项目再使用)
1. 导入 --> {% load 'py文件的名字' %}
2. 使用 --> {% 函数名'参数' %}
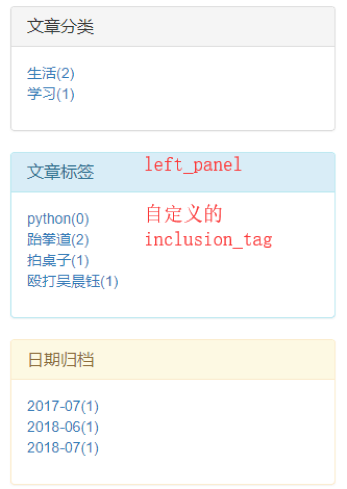

二、查看具体分类信息对应的文章
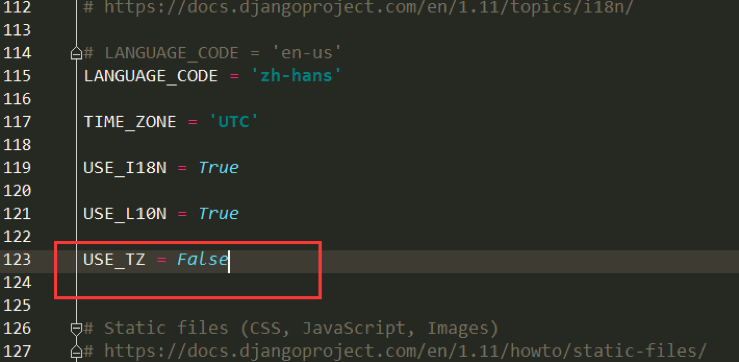
# bbs -> settings.py
1. USE_TZ = False!!!
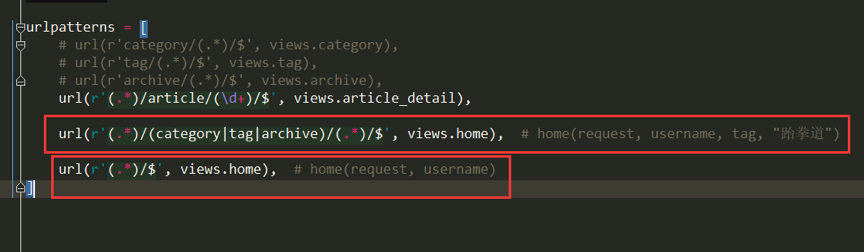
# blog -> urls.py
1. 通过URL(配置二级路由)的巧妙设计实现视图函数home的复用
url(r'^(.*)/(category|tag|archive)/(.*)/$',views.home),
# 注意要放在url(r'^(.*)/$',views.home),前
注意分组,后续home要接收三个参数
# blog -> views.py
1. home函数
def home(request,username,*args):
user = models.UserInfo.objects.filter(username=username).first()
if not user:
return HttpResponse(404)
else:
blog = user.blog
if not args:
article_list = models.Article.objects.filter(user=user)
else:
if args[0] == 'category':
article_list = models.Article.objects.filter(user=user).filter(category__title=args[1])
elif args[0] == 'tag':
article_list = models.Article.objects.filter(user=user).filter(tags__title=args[1])
else:
y,m = args[1].split('-')
article_list = models.Article.objects.filter(user=user).filter(create_time__year=y,create_time__month=m)
return render(request,'home.html',{'username': username,'blog':blog,'article_list':article_list})
# templates -> left_tag.html
1.设置a标签的href,实现跳转
三、文章详情页
# blog -> urls.py
1. 配置二级路由
url(r'^(.*)/article/(d+)/$',views.article_details),
# blog -> views.py
1. 注意做到这一步,要传{'username':username,'blog':blog, 'article_obj':article_obj}
# username 对应左侧菜单,blog对应head主题,article_obj为article_details.html所需
# templates -> article_details.html
1.使用母版
{% extends 'base.html' %}
{% block page-main %}
{% endblock page-main %}
2. 数据库中保存富文本(文本+样式)内容时,保存的是完整的html代码。
{{ article_obj.articledetail.content|safe }}
# 注意入库前要检验信息,防止xss攻击
day5 (6 Jul 18)
1. mypage.py
2. views.py
3. index.html
4. home.html
5. urls.py (一级)
6. mybss.css
7. article_details.html
一、分页(home个人主页和index首页面)
# utils -> mypage.py
1. 在工具包utils中加入mypage.py
class Page(object):
"""
这是我带上海全栈一期写的一个自定义分页类
可以实现Django ORM数据的分页展示
使用说明:
from utils import mypage
page_obj = mypage.Page(total_num, current_page, 'publisher_list')
publisher_list = data[page_obj.data_start:page_obj.data_end]
page_html = page_obj.page_html()
为了显示效果,show_page_num最好使用奇数
"""
def __init__(self, total_num, current_page, url_prefix, per_page=10, show_page_num=11):
"""
:param total_num: 数据的总条数
:param current_page: 当前访问的页码
:param url_prefix: 分页代码里a标签的前缀
:param per_page: 每一页显示多少条数据
:param show_page_num: 页面上最多显示多少个页码
"""
self.total_num = total_num
self.url_prefix = url_prefix
self.per_page = per_page
self.show_page_num = show_page_num
# 通过初始化传入的值计算得到的值
self.half_show_page_num = self.show_page_num // 2
# 当前数据总共需要多少页码
total_page, more = divmod(self.total_num, self.per_page)
# 如果有余数,就把页码数+1
if more:
total_page += 1
self.total_page = total_page
# 对传进来的当前页码数做有效性校验
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
# 如果当前页码数大于总页码数,默认展示最后一页的数据
# current_page = total_page if current_page > total_page else current_page
if current_page > self.total_page:
current_page = self.total_page
# 如果当前页码数小于1,默认展示第一页的数据
if current_page < 1:
current_page = 1
self.current_page = current_page
# 求 页面上 需要展示的页码范围
if self.current_page - self.half_show_page_num <= 1:
page_start = 1
page_end = show_page_num
elif self.current_page + self.half_show_page_num >= self.total_page:
page_end = self.total_page
page_start = self.total_page - self.show_page_num + 1
else:
page_start = self.current_page - self.half_show_page_num
page_end = self.current_page + self.half_show_page_num
self.page_start = page_start
self.page_end = page_end # 我上面一通计算得到的页面显示的页码结束
# 如果你一通计算的得到的页码数比我总共的页码数还多,我就把页码结束指定成我总共有的页码数
if self.page_end > self.total_page:
self.page_end = self.total_page
@property
def data_start(self):
# 返回当前页应该从哪儿开始切数据
return (self.current_page-1)*self.per_page
@property
def data_end(self):
# 返回当前页应该切到哪里为止
return self.current_page*self.per_page
def page_html(self):
li_list = []
# 添加前面的nav和ul标签
li_list.append("""
<nav aria-label="Page navigation">
<ul class="pagination">
""")
# 添加首页
li_list.append('<li><a href="/{}/?page=1">首页</a></li>'.format(self.url_prefix))
# 添加上一页
if self.current_page <= 1: # 没有上一页
prev_html = '<li class="disabled"><a aria-label="Previous"><span aria-hidden="true">«</span></a></li>'
else:
prev_html = '<li><a href="/{}/?page={}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format(self.url_prefix,
self.current_page - 1)
li_list.append(prev_html)
for i in range(self.page_start, self.page_end + 1):
if i == self.current_page:
tmp = '<li class="active"><a href="/{0}/?page={1}">{1}</a></li>'.format(self.url_prefix, i)
else:
tmp = '<li><a href="/{0}/?page={1}">{1}</a></li>'.format(self.url_prefix, i)
li_list.append(tmp)
# 添加下一页
if self.current_page >= self.total_page: # 表示没有下一页
next_html = '<li class="disabled"><a aria-label="Previous"><span aria-hidden="true">»</span></a></li>'
else:
next_html = '<li><a href="/{}/?page={}" aria-label="Previous"><span aria-hidden="true">»</span></a></li>'.format(
self.url_prefix, self.current_page + 1)
li_list.append(next_html)
# 添加尾页
li_list.append('<li><a href="/{}/?page={}">尾页</a></li>'.format(self.url_prefix, self.total_page))
# 添加nav和ul的结尾
li_list.append("""
</ul>
</nav>
""")
# 将生成的li标签 拼接成一个大的字符串
page_html = "".join(li_list)
return page_html
# blog -> views.py
1. home函数
2. index函数
from utils import mypage
total_num = article_list.count()
current_page = request.GET.get('page')
url_prefix = request.path_info.strip('/')
page_obj = mypage.Page(total_num, current_page, url_prefix, per_page=2)
article_list = article_list[page_obj.data_start:page_obj.data_end]
page_html = page_obj.page_html()
# templates -> index.html
1. {{ page_html|safe }}
# templates -> home.html
1. {{ page_html|safe }}


二、点赞
# 点赞的逻辑
1. 自己不能给自己点赞
2. 一个人只能点一次赞/反对
3. 不能取消
4. 要登录才能点赞/反对
5. 点赞和反对二选一
# blog -> urls.py
1. url(r'^updown/',views.updown),
# static -> mybss.css
1. copy网页上的点赞踩灭样式
# templates -> article_details.html
1. copy网页上的点赞踩灭html
2. 设计动作,发ajax请求
3. 在js中+'5' 为parseInt('5')
$up_count.text(+$up_count.text() + 1)
# blog -> views.py
1. 事务
from django.db import transaction
2. F查询
from django.db.models import F
3. updown函数
def updown(request):
ret = {'code': 0}
is_up = request.POST.get('is_up')
article_id = request.POST.get('article_id')
user_id = request.POST.get('user_id')
is_up = True if is_up.upper() == 'TRUE' else False
if models.Article.objects.filter(nid = article_id, user_id = user_id):
ret['code'] = 1
ret['data'] = '不能给自己点赞' if is_up else '不能给自己反对'
else:
is_exist = models.ArticleUpDown.objects.filter(article_id=article_id,user_id=user_id).first()
if is_exist:
ret['code'] = 1
ret['data'] = '已经点赞过' if is_exist.is_up else '已经反对过'
else:
with transaction.atomic():
models.ArticleUpDown.objects.create(is_up=is_up,article_id=article_id,user_id=user_id)
if is_up:
models.Article.objects.filter(nid=article_id).update(up_count = F('up_count') + 1)
else:
models.Article.objects.filter(nid=article_id).update(down_count=F('down_count') + 1)
ret['data'] = '点赞成功' if is_up else '反对成功'
return JsonResponse(ret)
三、评论样式设计
# blog -> views.py
1. article_details函数
comment_list = models.Comment.objects.filter(article_id=article_nid)
# templates -> article_detail.html
1. 评论列表展示
2. 发表评论区
day6 (9 Jul 18)
一、评论
1. bug:当新建一个评论时,为了让其立马显示在页面中(不刷新页面),我们通过利用js加一段html代码在评论显示页面尾部。但如果不做以下操作,会导致不刷新的情况下,点新增的的comment的回复按钮,所产生的子评论被当作根评论。
原因:在不刷新页面的情况下,新建的根评论的代码中没有嵌入id,导致其下建立的子评论找不到根评论id,默认没有根评论。刷新页面后,该子评论被当成根评论显示。
解决方法: 用事件委托& 为新嵌入的html代码中的li标签加上my_id属性(其中存放它的id,该id由后端传入)。
解释:这样,当新建一个根评论时,加入的那段html中有存放其id。在创建其子评论时,子评论可以取到新建根评论的id作为其parent_comment_id,并传至后端,而后后端会将其看作时子评论,刷新时正常按照子评论的方式显示出来。
2. 模板语言的使用(用js加一段html代码在评论显示页面尾部时)

3. 评论楼及评论树(如下图)

day7 (10 Jul 18)
一、管理后台
1. kindeditor使用
1. 下载:http://kindeditor.net/down.php
2. 使用:http://kindeditor.net/docs/usage.html
1. 将下载的内容放到项目目录下(static下)
2. 在页面导入两个js文件(kindeditor-all-min.js, lang -> zh-CN.js)
3. 按要求初始化
<script>
KindEditor.ready(function (K) {
window.editor = K.create('#article-content', {
'800px', // 宽
height: '500px', // 高
uploadJson: '/upload_img/', // 上传文件的URL
extraFileUploadParams: {csrfmiddlewaretoken: $("[name='csrfmiddlewaretoken']").val()} // 给上传文件添加csrftoken
});
});
</script>
2. BeautifulSoup4模块的使用(校验入库前的数据(文章内容中)是否有危险数据(script标签))
1. 安装
pip3 install beautifulsoup4
2. 使用
from bs4 import BeautifulSoup
obj = BeautifulSoup("HTML内容", "html.parser")
obj.标签名 #查找第一个该标签
obj.find_all("标签名") # 查找所有该标签
tag_obj.decompose() # 销毁具体的标签对象
obj.text # 获取html中的文本内容
obj.prettify() # 获得格式化的HTML文档的(reformat code)
总结:

官方总结:
1. 建表 --> 项目开始先分析需求建表结构
2. 登录
1. form组件
1. form类
1. html
form_obj.字段 --> 生成html代码
2. views.py
form_obj = formClass(request.POST)
form_obj.is_valid() --> 返回布尔值
1. 如果返回True,就能拿到校验后的数据
form_obj.cleaned_data
3. 看源码分析得到钩子函数
1. 局部钩子
def clean_字段名():
1. return value
2. raise ValidationError('错误信息')
2. 全局钩子
def clean():
1. return self.cleaned_data
2. raise ValidationError('错误信息')
2. Django auth模块
1. 校验用户名密码对不对
user_obj = auth.authenticate(username, password)
2. 登录操作
auth.login(request, user_obj)
1. 生成session数据,保存了用户的user_id
auth中间件中:
拿到user_id去数据库找到当前请求对应的用户对象
找不到就是匿名用户
request.user = 用户对象
3. 注销操作
auth.logout(request)
清空session数据, 也就是清空了user_id
3. 验证码
1. 自己生成验证码
1. Pillow模块的使用 (PIL)
2. from io import BytesIO
2. 滑动验证码
1. 根据SDK写代码
3. 注册
1. 注册的form类
2. 上传文件
1. 表单上传
form标签两个属性
1. method='POST'
2. enctype="multipart/form-data"
2. AJAX上传
1. 创建一个FormData对象,使用对象的append()方法填充数据
2. AJAX需要设置两个参数
1. processData: false
2. contentType: false
3. Django 关于上传文件的几个配置
1. 上传文件存在哪儿?
1. settings.py中 配置MEDIA_ROOT = os.path.join(BASE_DIR, "media")
2. 我用户怎么访问我刚上传的文件
1. settings.py中 配置MEDIA_URL = "/media/"
2. 在urls.py中 配置media开头的访问请求交给谁来处理
url(r'^media/(?P<path>.*)$', serve, {"document_root": settings.MEDIA_ROOT})
4. 浏览器图片预览
1. FileReader对象
整理好笔记就行
4. BBS首页
1. 发送请求,返回响应(ORM查询)
5. 个人主页
1. 文章分类信息
1. 文章分类
外键的分组聚合查询 --> 每个分类对应的文章数
2. 标签分类
多对多的分组聚合查询 --> 每个标签对应的文章数
3. 日期归档
extra执行原生SQL语句
DATA_FORMAT函数,将日期格式化成%Y-%m --> 每个年月对应的文章数
2, 因为很多个页面都用到了分类功能,所以我们就写了一个inclusion_tag
1. 定义阶段
2. 使用
3. 分页功能的优化和使用
4. admin的简单使用
6. 文章详情
1. 数据库中保存的是具体的html内容
- 注意XSS攻击
2. 点赞
1. 分析业务逻辑
事务
1. 先在点赞表里创建一条点赞的记录
2. 更新文章表里的相应字段(up_count/down_count)的数据
2. AJAX实现
7. 评论
django里面用到的那些模块:
1. 路由:
1. from django.conf.urls import url, include
2. from django.views.static import serve 上传文件用到的内置视图
3. from django.conf import settings 当前项目用到的配置
2. 视图
1. from django.shortcuts import render, HttpResponse, redirect 三件套
2. from django.http import JsonResponse JSON格式的响应
3. from django.contrib import auth 认证
4. from django.views.decorators.cache import never_cache 缓存相关
5. from django.views.decorators.csrf import csrf_exempt, csrf_protect
6. from django.contrib.auth.decorators import login_required 登录
7. from django.utils.decorators import method_decorator 方法装饰器工具
3. ORM
1. from django.db.models import F, Q
2. from django.db import transaction
3. from django.db.models import Avg, Max, Min, Count, Sum
4. from django.contrib.auth.models import AbstractUser 内置auth model 类
4. form
1. from django import forms
2. from django.core.exceptions import ValidationError 检验异常
3. from django.core.validators import RegexValidator 校验方式
5. template
1. from django import template
6. admin
1. from django.contrib import admi