从HashMap源码中,可以看到求容器下标值的方法,有两步,首先通过key值计算hash,然后用hash计算下标:
计算hash:
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
计算下标,其下标值为:(n-1) & hash
n = (tab = resize()).length;
p = tab[i = (n - 1) & hash]
即,是通过key的hash值和容器的大小减1,两者进行与运算,获取容器数组下标。这里使用与运算,其实蕴含了一个隐藏条件,即数组的大小n,必须是2的n次方,否则,计算出来的下标值i是无法覆盖这个范围[0, n-1]的。
举个例子,假设两种情况,一种容器大小为10,不是2的幂,另外一种容器大小为16,刚好是2的4次方。
则,对于第一种,n-1= 9, 二进制表示为 1001,任何值与该值进行与运算,都无法改变中间的两个0,只能改变首尾的两个1,因此结果范围就缩小了一倍
而,对于第二种,n-1=15,二进制表示为 1111,该值与其他值与运算后,可以覆盖范围[0, 15],而这个范围刚好是数组的大小,因此只要hash值均匀分布,结果也是均匀的。
实际上,只要数组大小是2的幂,则 (n-1) & hash 的结果等效于: hash % (n-1);即与运算、求余运算通过这个前提,实现了等效。
而计算机中,与运算和求余运算,两个计算的效率肯定是前者更好。因为与运算,是直接对位进行逻辑与操作,属于cpu的底层支持的基础逻辑操作,但是求余运算可不是,应该是需要额外的算术运算单元支持的。可能这就是把数组大小规定为2的幂的原因之一,提高运算效率。
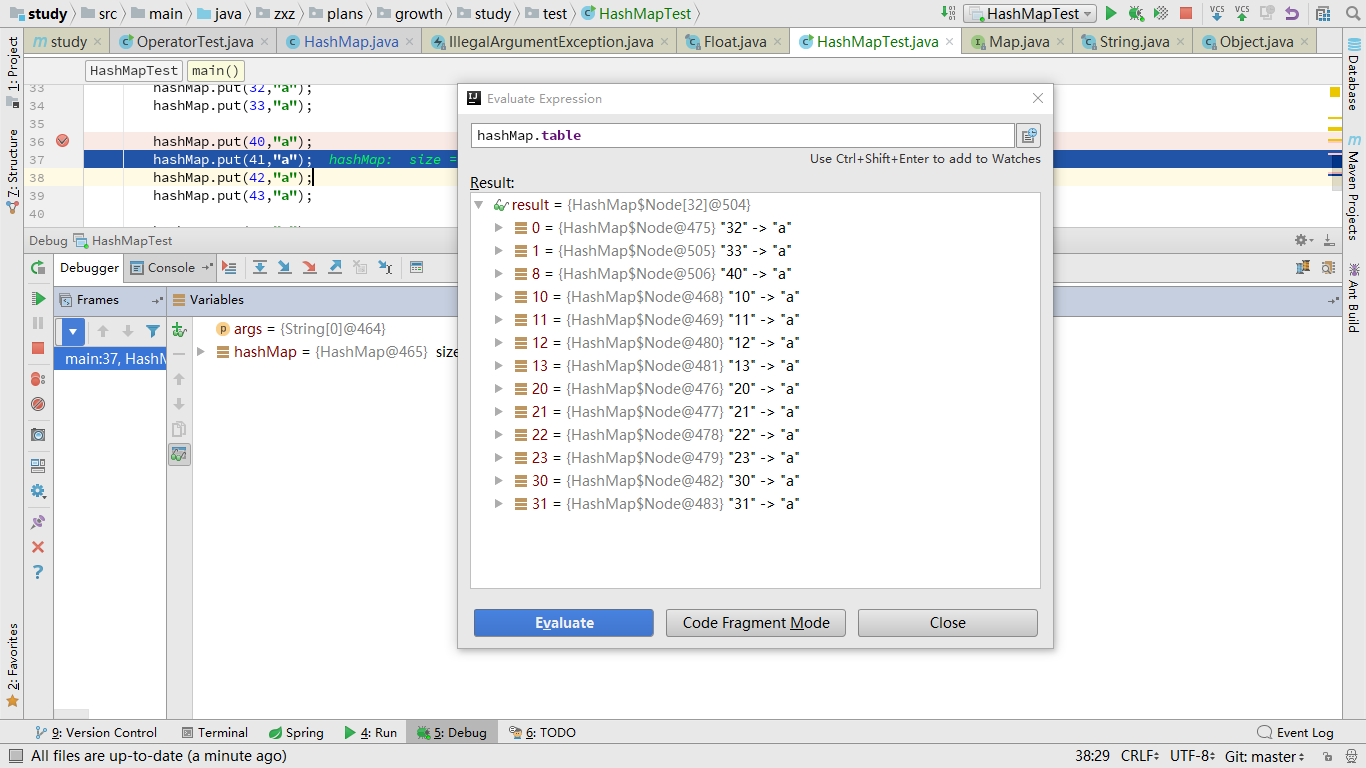
附注:这里额外补充一点,即HashMap的扩容机制,涉及到的参数有容器大小,负载因子,当实际数据的数量,超过两者的乘积时,就触发扩容,直接放大一倍。比如原本容器大小为16,负载因子为0.75(默认的),当放入的数据个数从12变为13时,则容器大小扩大为32. 扩容时,原本元素的位置也会发生改变,但是这种改变是有规律的,有一些是不变,而发生改变的,则刚好都是在原来数组索引的基础上,加上扩大的数量值(在该例子中就是加上16)。
这个我没有看源码,是直接根据上面的索引计算方式推断出来的,试验结果也证明确实如此。
扩容前:
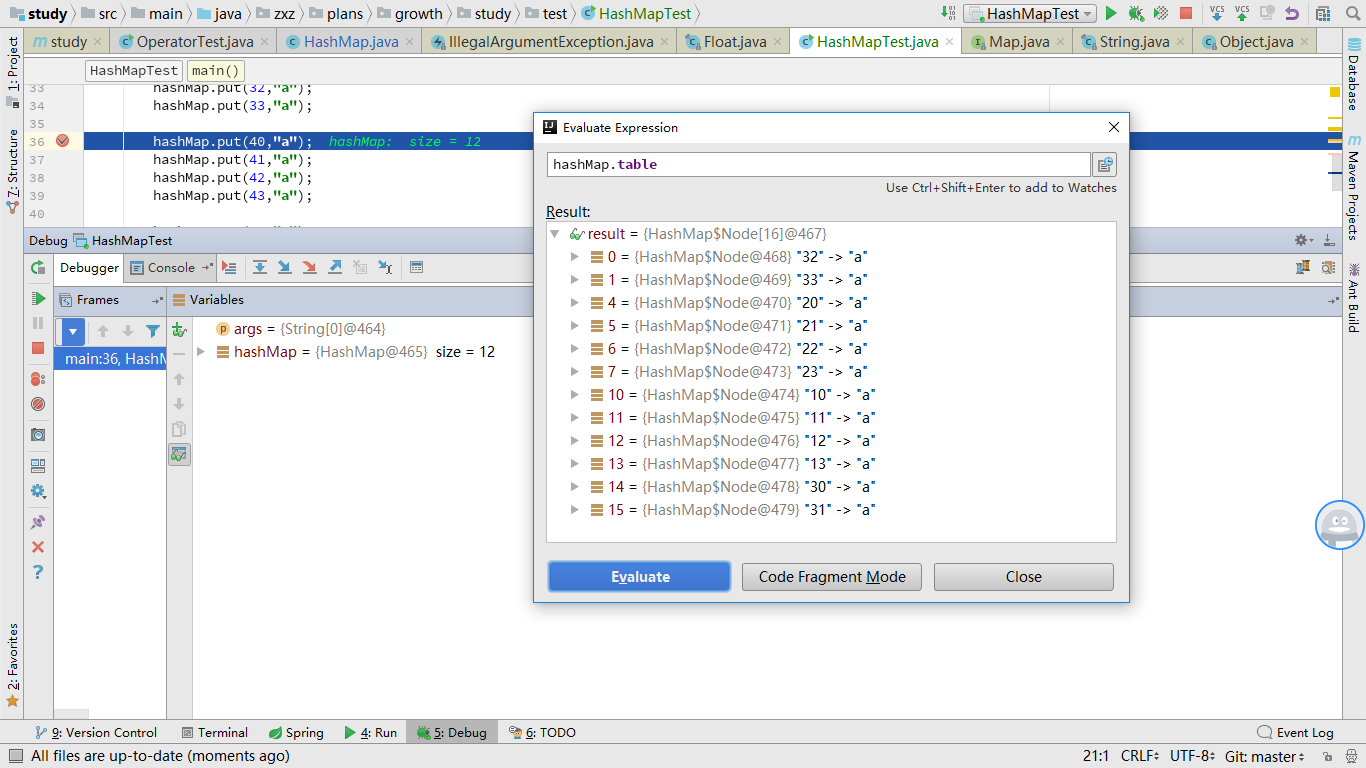
扩容后: