今天学习了第三讲:分类。
首先引入了初中知识,点到直线的距离,之后进一步上升到点到空间的距离,还给出了距离公式。

随后引入了最重要的梯度下降法,这种方法在下面被反复使用:

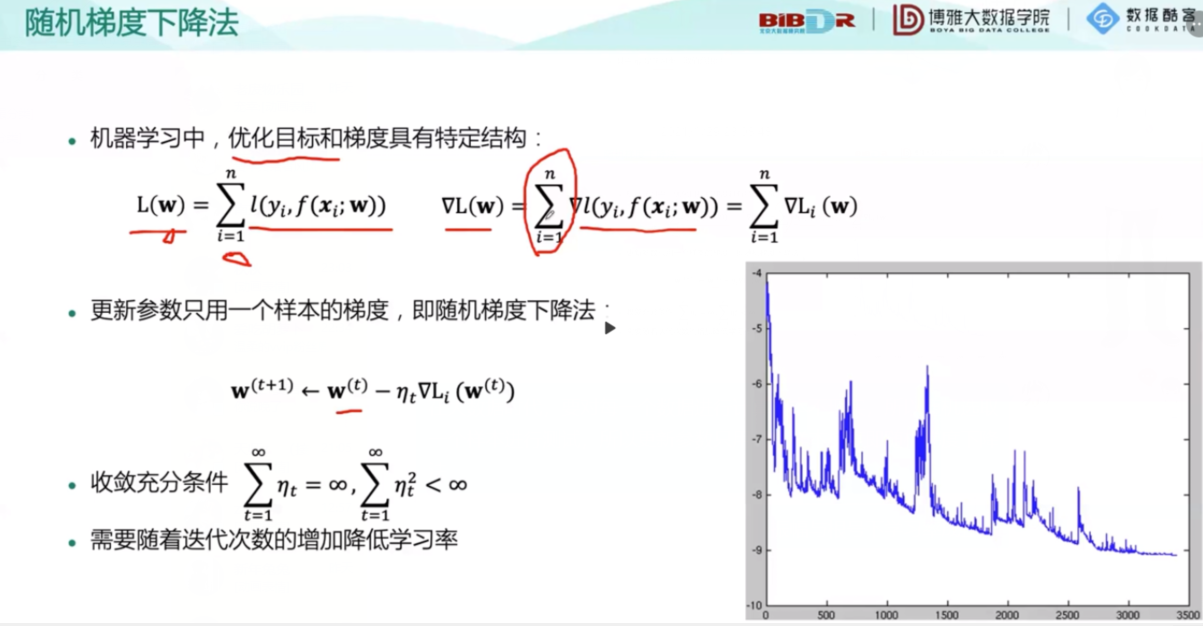
在大数据时代,要对每一个数据进行计算根本不现实,所以随机选取一个样本进行测试,所以更新参数只用一个样本梯度即随机梯度下降法,经过大佬们的证明这是科学的!而振幅与根号下学习率成正比
下面是概率论中学过的极大似然值的知识回归,有点忘了回头还要看一看:

随后提问什么是分类,对分类进行了定义,那么,如何分类呢?


介绍完三种算法,开始引入新概念,相互结合。

概率与上面式子中的f有关,还和图中的点有关,离得越近,概率越接近1。
这是训练集的矩阵表示:
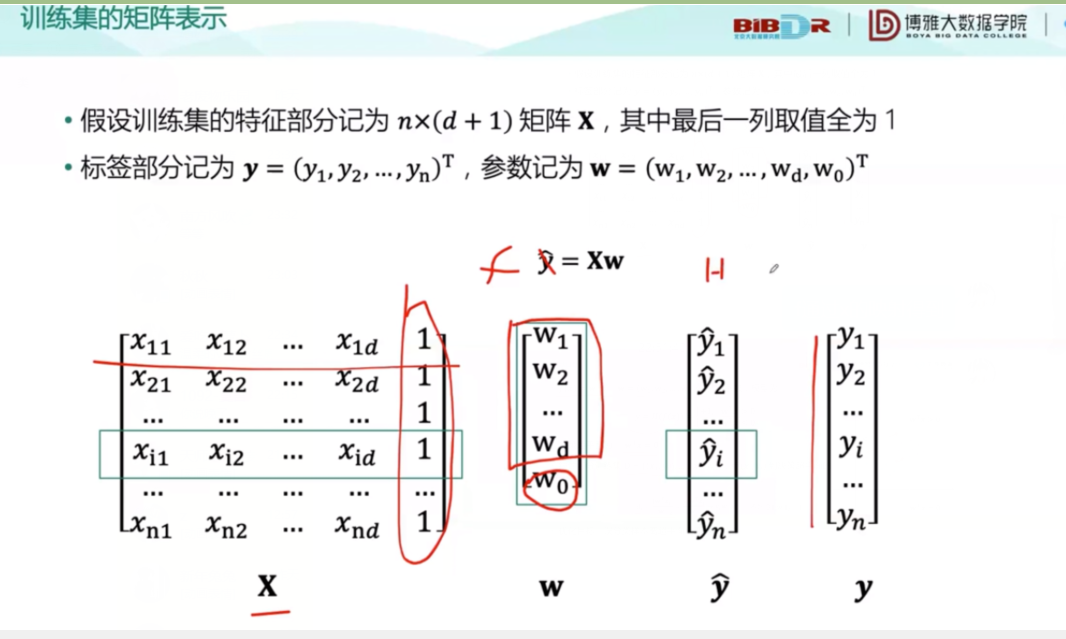
其中,f通过x的映射得到。

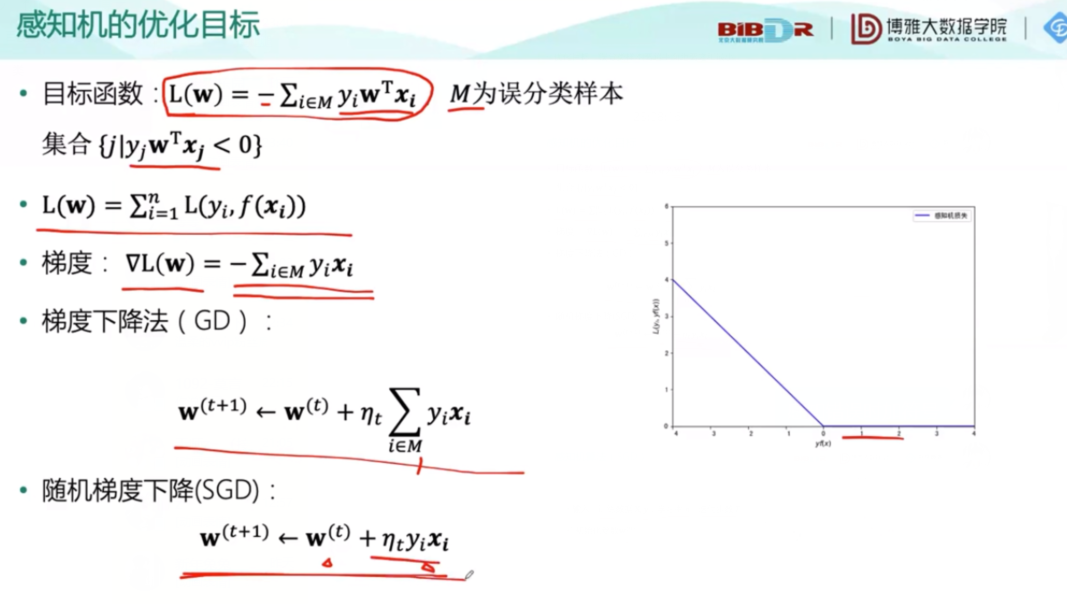
关于感知机和优化中,感知错误时在式子前面加一个负号。
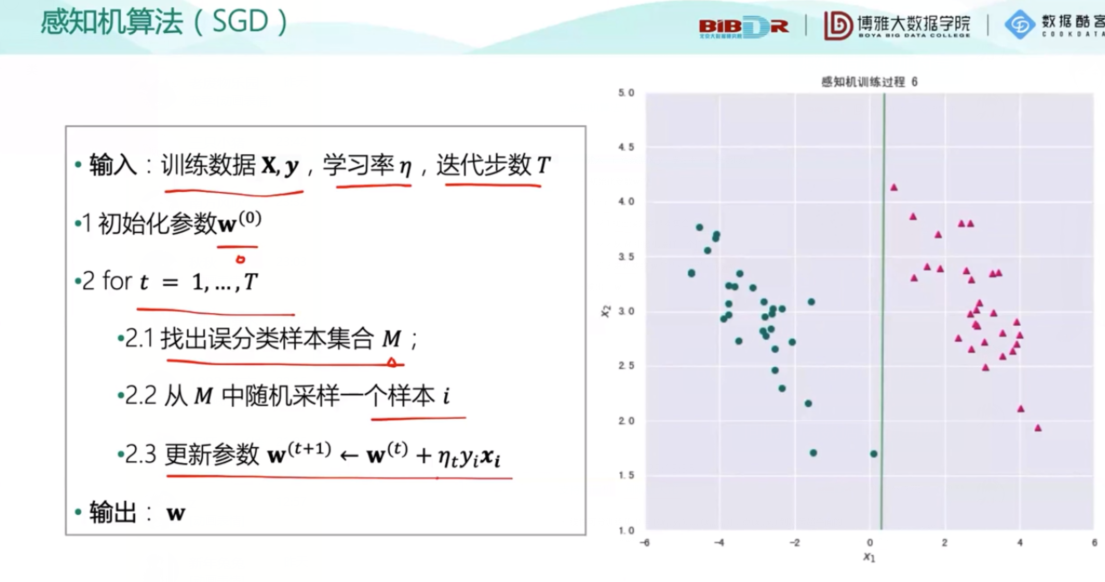
下面是一个小例子,6次成功,成功将两种数据分开,但是并不太好,因为离数据集太近了,间隔,离数据集越远越好


在这里面有两个优化目标,一个是第一个是让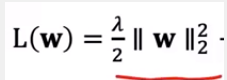 的平方和最小,第二个是让惩罚函数
的平方和最小,第二个是让惩罚函数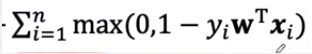 最小。
最小。

核技巧是低纬向高纬的映射,它的好处是映射之后计算量还是低纬的计算量。

之后又引入一些公式:
用梯度下降法去更新函数:

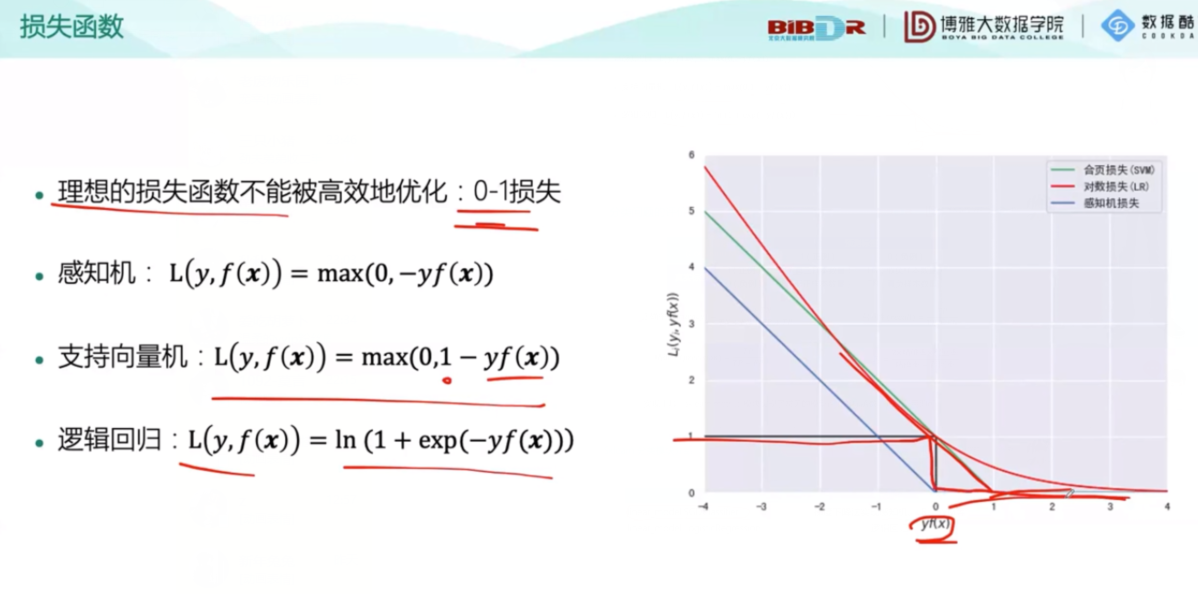
下面是损失函数的对比:
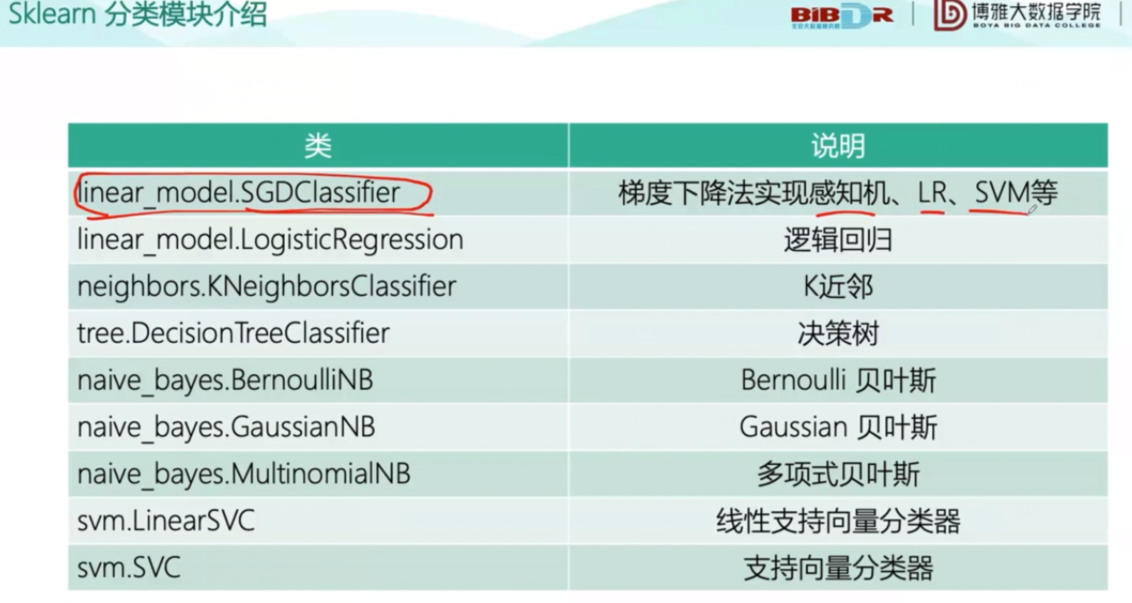
然后是分类问题的评价指标和一些Python中的常用函数、工具:


之后开始了实例环节,又让我见识了很多Python的函数,比如生成二分类数据集的make_classification()和接受用户输入的perception()等等!课程结束。