几天学习了机器学习十讲的第二讲——回归,首先从大一学的线性代数开始讲起,显示简单复习了线性代数的知识点:

介绍完逆矩阵,老师提出了疑问,什么是回归:

但是听到一半我有些疑问,老师举的例子就是身高的例子,但是现实是后代的身高往往比父母都要高,哈哈,我把他归根于营养好。
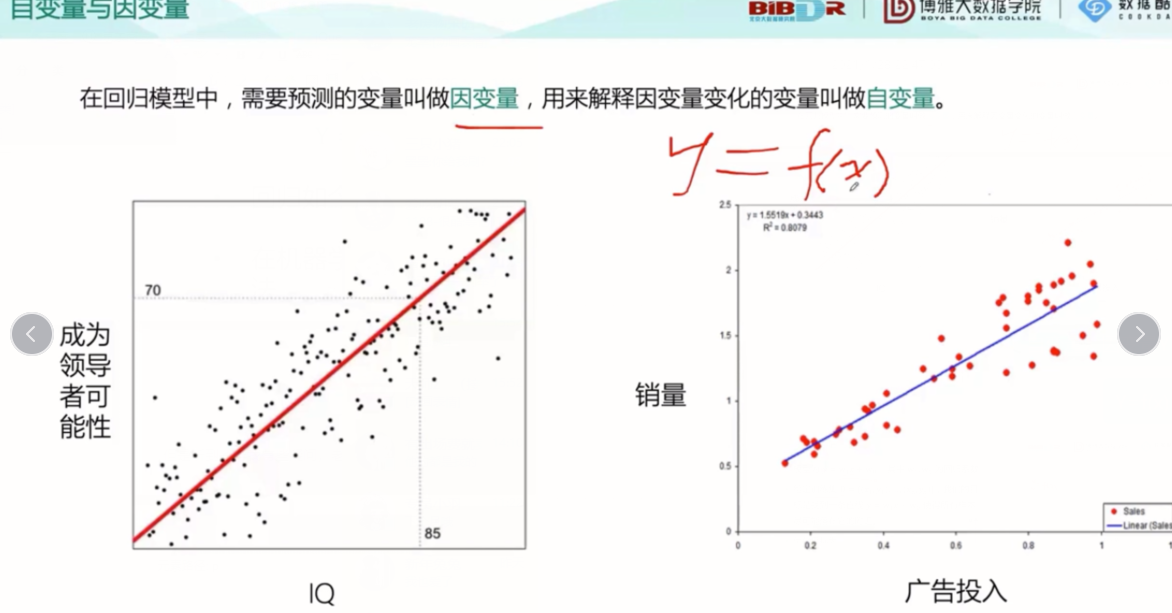
上图用图显示了回归模型预测的实例图,自变量X 因变量Y,Y=f(x)。
典型的回归模型:

优化目的:使均方误差变的最小。之后给出了一元线性回归方程的求解方式,为了方便以后找结论我也直接截图放这里了:

简单的一元说完了,我们来看看多元线性回归,它就不再是一维的线性了,它升级到了体的层面:

多元线性回归用矩阵表示:

求解:


视频提到,奇异问题是因为对角线两边会有重复数据(没听太懂,线代有点忘了嘿嘿)还是什么的,总之,遇到问题,就要解决问题,下面是决绝问题的三种方式:正则化、主成分回归、偏最小二乘回归。
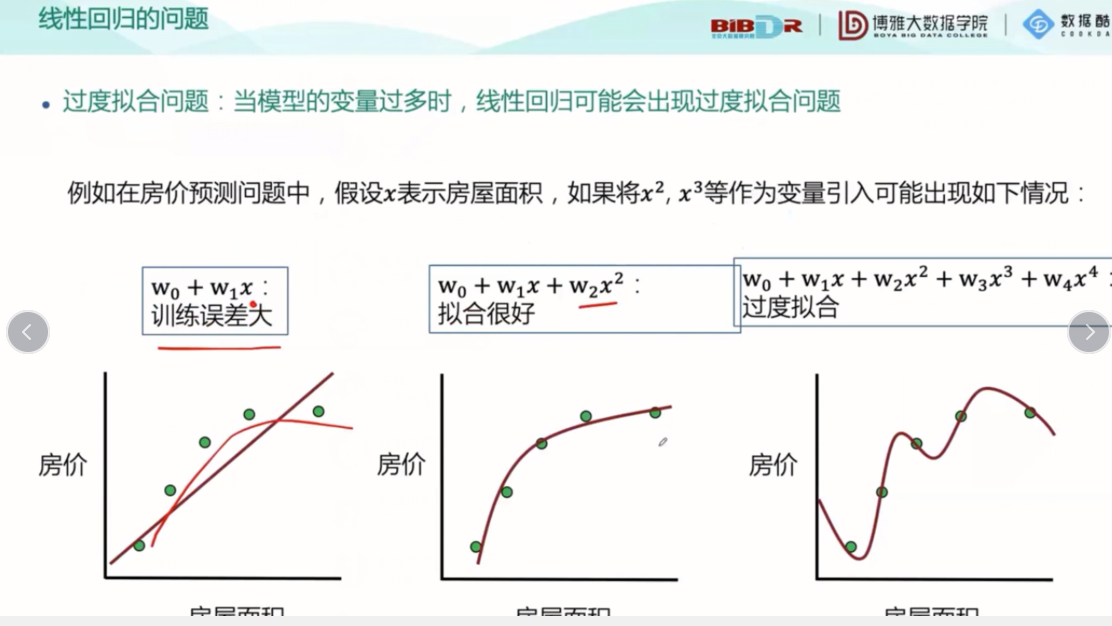
从上图我们能看到,第一个图拟合的不好,数据和回归出来的线性方程有很大偏差,图像走向明显不是线性,第二个图拟合的不错,数据在函数附近而第三个图中的数据几乎全部分布在曲线上,这就形成了过度拟合的问题,就会造成对测试集拟合效果很好,预测效果很差,因此我们要解决过度拟合问题,提出了正则化的概念:
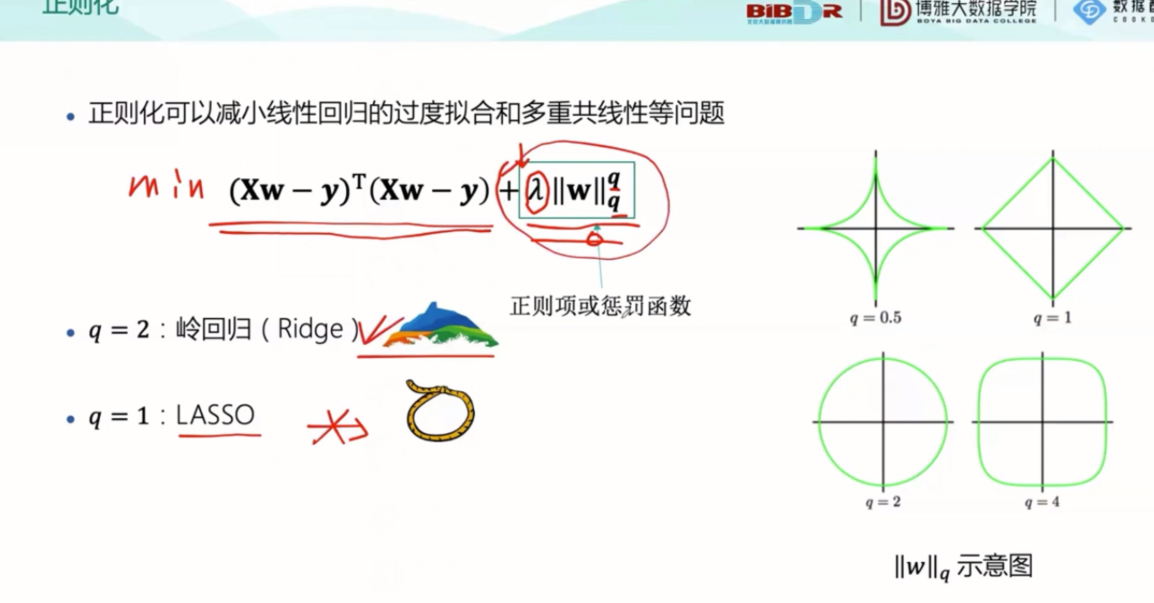
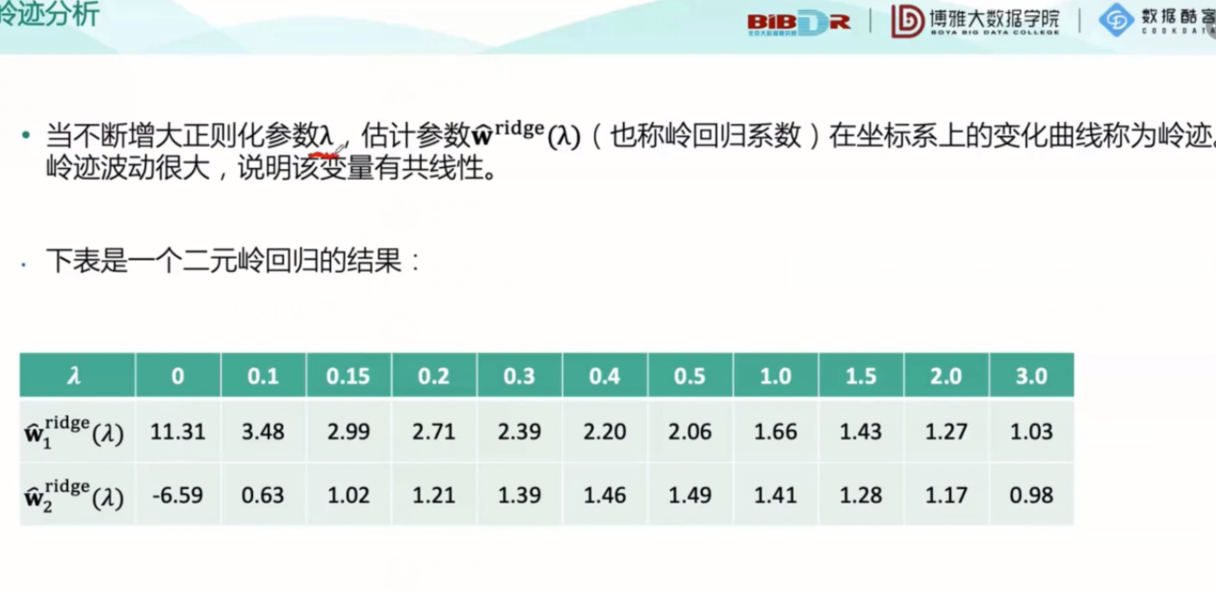
关于岭回归:

PS:实现的时候对单位矩阵的右下角的最后一项为0
另一种方式LASSO:

对系数进行压缩和选择
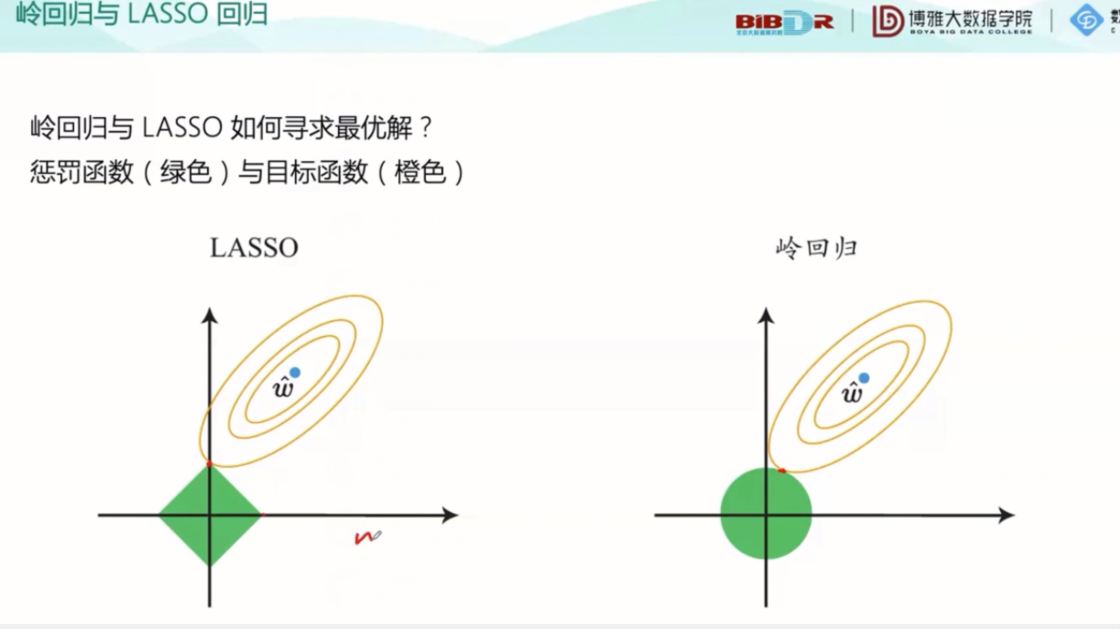
由图可以看出,LASSO的最优点只有四个,而岭回归的在任意一点都能很好地契合。
正规划分析:
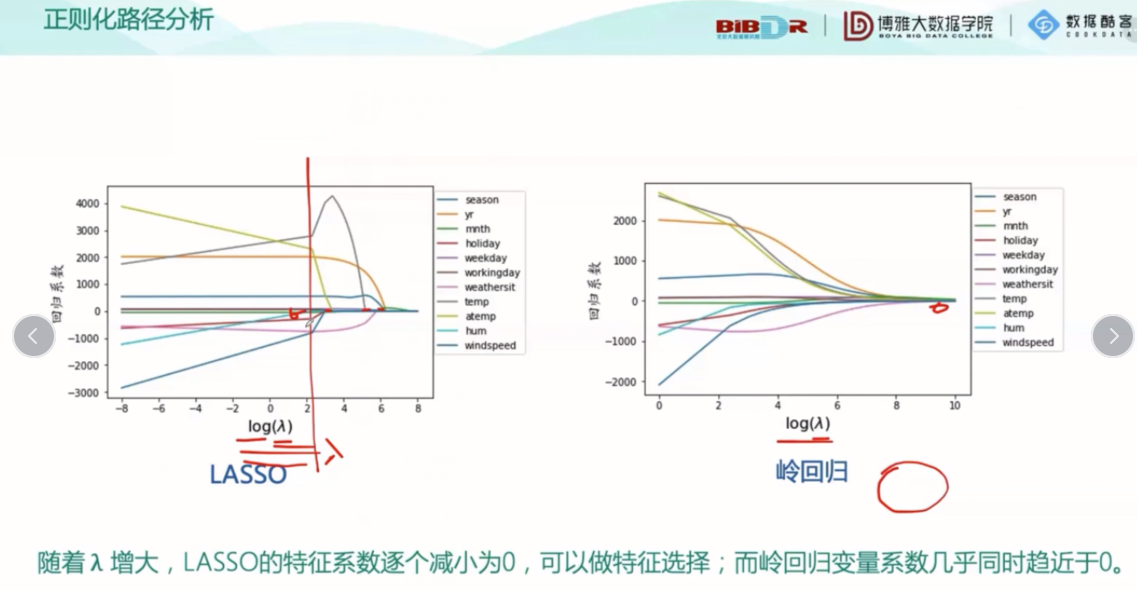
最后给出了回归垄断的几种方式

其中决定系数:R²取值为0~1,越接近于1效果越好,反之则越差。之后讲了一个例子,在例子中有很多Python的方法,Python中算相关性的函数 corr(),相关性取值0~1,数值越大相关性越大。还有很多函数,比如划分训练集,比如构建回归模型等等,就不一一列举了。