今天学习了数据酷客的《机器学习十讲》中的第一讲,老师提出了很多概念,我做了截图,也写了一些自己的理解:
首先是引言:学习机器学习的理由,它的应用。

之后是关于大数据,人工智能等一些现在热词的定义的阐释:

这里面提到一个函数Y=F(X),F是由多层的神经网络来表示。人工智能,从Y的角度看:能解决什么问题。

在有监督学习中,学习x与y之间的对应关系,y=f(x)
但是不管是无监督学习还是有监督学习都需要有数据,而强化学习可以一开始没有数据,从0开始,通过学习慢慢收集数据。


之后讲述了机器学习的基本概念:


优化目标很明显,是让损失函数最小化,从而是函数更贴切,更契合。
以有监督学习为例,提出了机器学习的一般流程的图示:
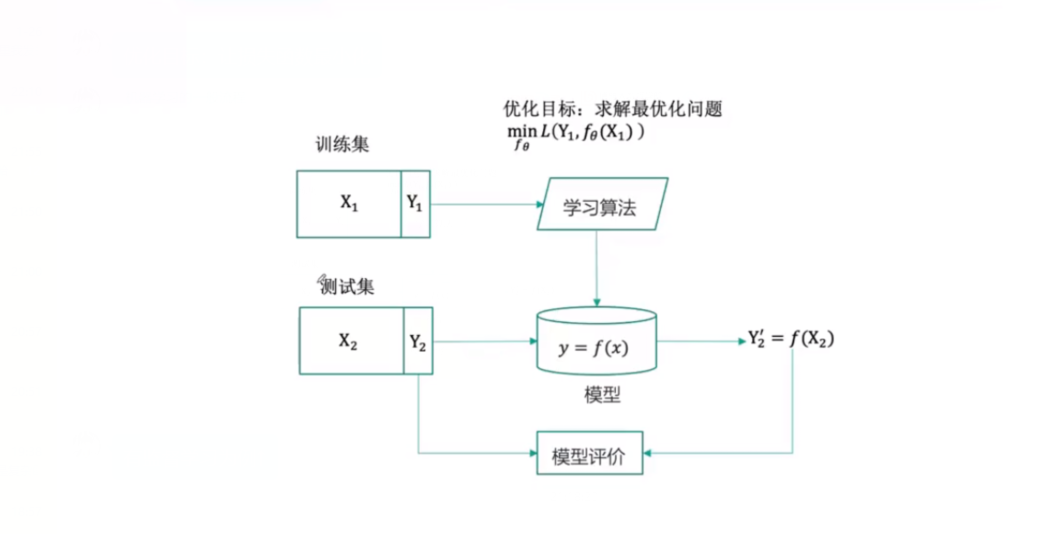
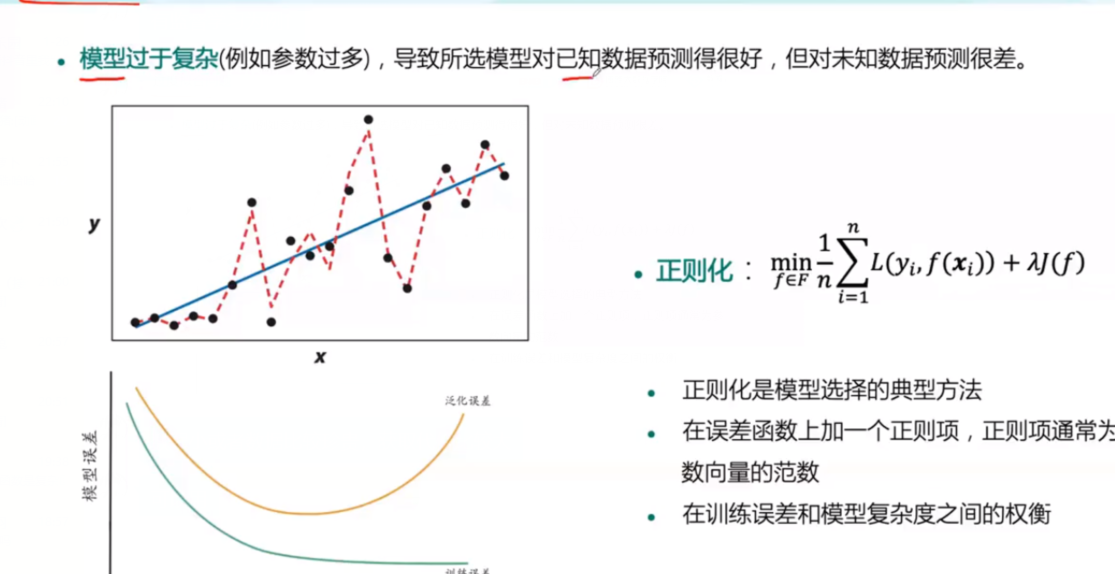
但是机器在学习过程中会有一些问题,比如过度拟合问题,过度拟合的优点是对已知数据预测得很准确,但是对未知数据的预测效果很差,因此提出了正则化的概念:
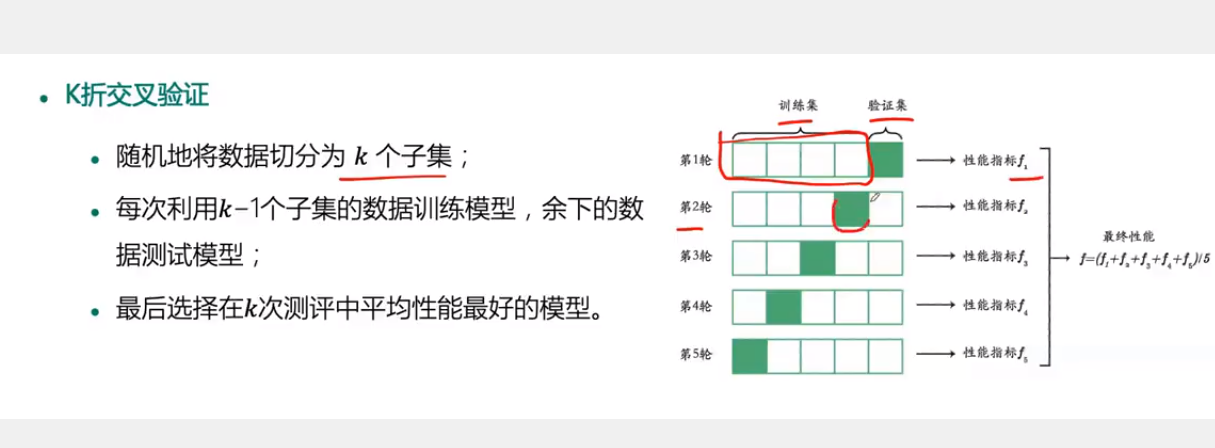
但是当数据很小或者数据采集成本很高,获取代价较大时,可以选用交叉验证:

机器学习具有数学结构,我们处理数据也是基于数学结构:

之后便提到了关于数学方面的知识,终于来到了计算环节:

以文章为例,通过计算余弦相似度来计算两个文章的“距离”。除了余弦相似度,还提到了三种计算方式,我分别做了如下理解:
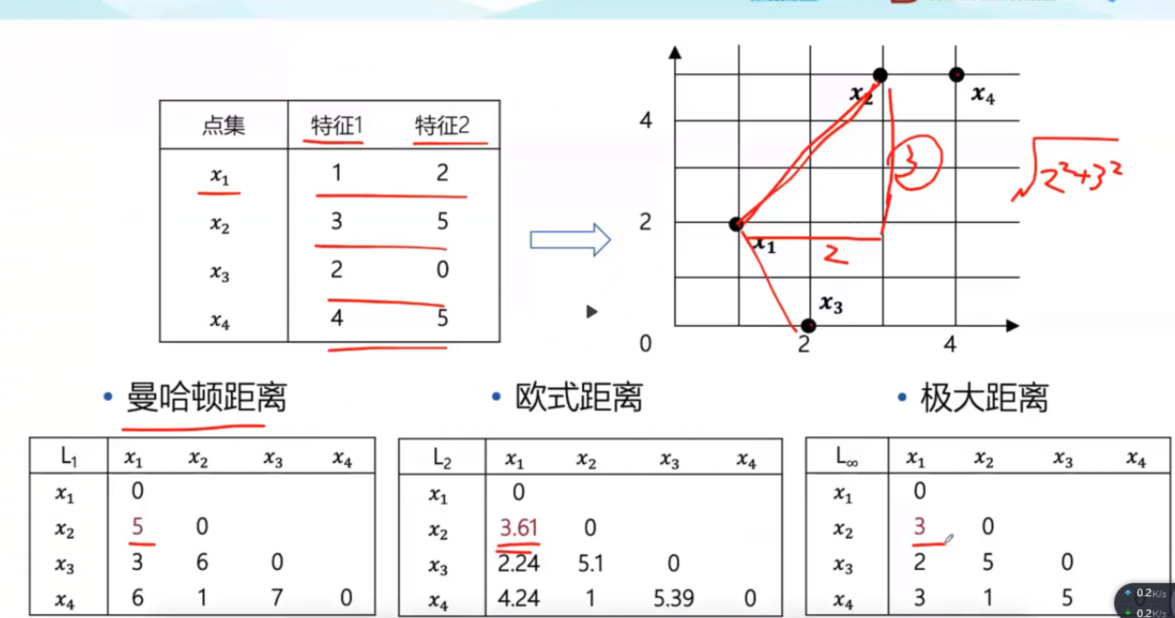
曼哈顿距离:两点连线为斜边,另外两个直角边相加为距离。
欧氏距离,斜边长度为距离
极大距离:两个直角边中较长的为距离
之后提出了K近邻的概念,对样本进行分类时,找到训练集中与该样本最相似的K个样本,根据K样本的标签确定测试样本的标签。 最简单的模型:
随后介绍了谷歌退出的一个名为PageRank的算法,他是一个网页之间排优先的算法,如图:
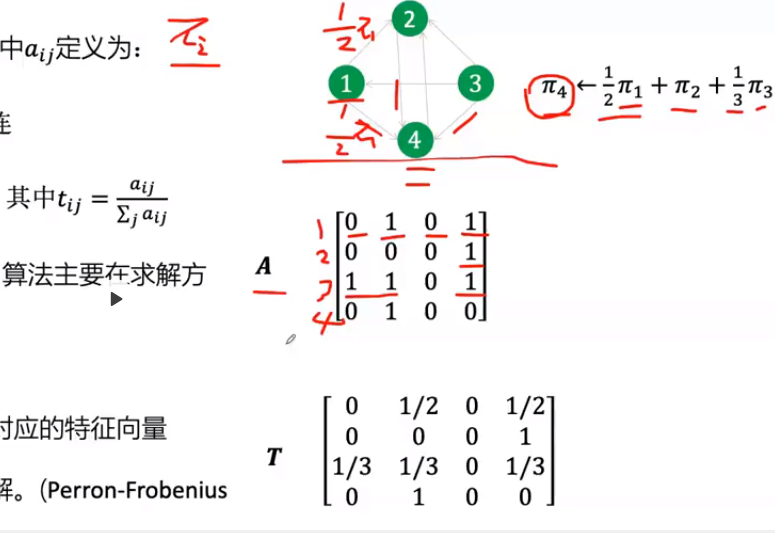
用矩阵表示,例如1指向2 4,将π分为两等份,分别分给2和4,第三个矩阵的每一行相加都为1。
其他数学结构例如:
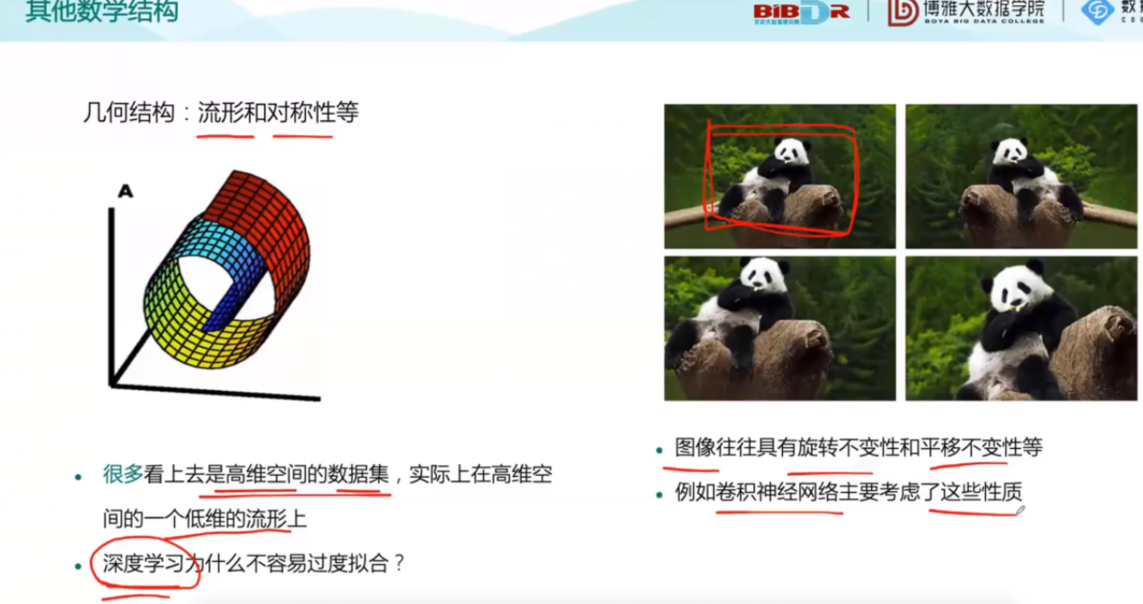
最后,讲了之后操作需要用的软件和下载地址以及两个代码案例。但是下面的两个实例的链接已经无法打开,只能看到视频中的部分伪代码,所以没有数据,没有进行实践操作。