一、架构图
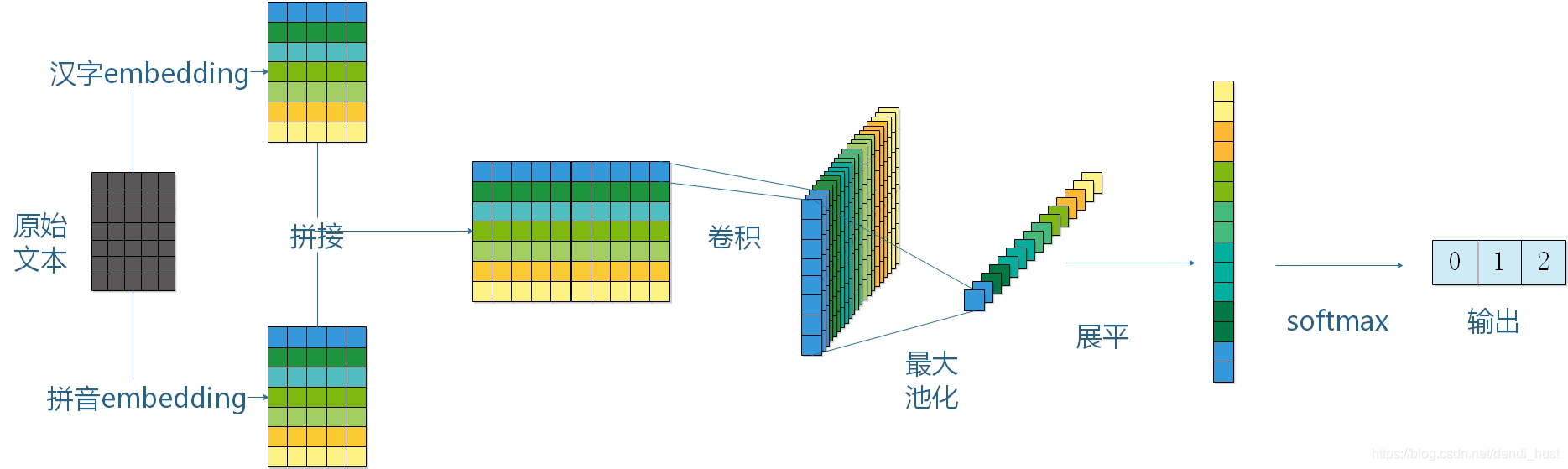
二、代码实现
class TextCNN(nn.Module): def __init__(self, config:TCNNConfig, char_size = 5000, pinyin_size=5000): super(TextCNN, self).__init__() self.learning_rate = config.learning_rate self.keep_dropout = config.keep_dropout self.sequence_length = config.sequence_length self.char_embedding_size = config.char_embedding_size self.pinyin_embedding_size = config.pinyin_embedding_size self.filter_list = config.filter_list self.out_channels = config.out_channels self.l2_reg_lambda = config.l2_reg_lambda self.model_dir = config.model_dir self.data_save_frequency = config.data_save_frequency self.model_save_frequency = config.model_save_frequency self.char_size = char_size self.pinyin_size = pinyin_size self.embedding_size = self.char_embedding_size self.total_filters_size = self.out_channels * len(self.filter_list) self.build_model() def build_model(self): # 初始化字向量 self.char_embeddings = nn.Embedding(self.char_size, self.char_embedding_size) # 字向量参与更新 self.char_embeddings.weight.requires_grad = True # 初始化拼音向量 self.pinyin_embeddings = nn.Embedding(self.pinyin_size, self.pinyin_embedding_size) self.pinyin_embeddings.weight.requires_grad = True self.conv_list = nn.ModuleList() conv_list = [nn.Sequential( nn.Conv1d(self.embedding_size, self.out_channels, filter_size), nn.BatchNorm1d(self.out_channels), nn.ReLU(inplace=True) ) for filter_size in self.filter_list] # 卷积列表 self.conv_lists_layer = nn.ModuleList(conv_list) self.output_layer = nn.Sequential( nn.Dropout(self.keep_dropout), nn.Linear(self.total_filters_size, self.total_filters_size), nn.ReLU(inplace=True), nn.Linear(self.total_filters_size, 2) ) def forward(self, char_id, pinyin_id): # char_id = torch.from_numpy(np.array(input[0])).long() # pinyin_id = torch.from_numpy(np.array(input[1])).long() pooled_outputs = [] sen_char = self.char_embeddings(char_id) sen_pinyin = self.pinyin_embeddings(pinyin_id) sen_embed = torch.cat((sen_char, sen_pinyin), dim=1) # 转换成 (N C SEN_LEN) 的形式 sen_embed = sen_embed.permute(0, 2, 1) for conv in self.conv_lists_layer: # print(sen_embed.shape) conv_output = conv(sen_embed) max_polling_output = torch.max(conv_output, dim=2) pooled_outputs.append(max_polling_output[0]) total_pool = torch.cat(pooled_outputs, 1) flatten_pool = total_pool.view(-1, self.total_filters_size) fc_output = self.output_layer(flatten_pool) return fc_output
三、经验值
- TextCNN优点是模型简单、训练和预测的速度快;缺点是超参(主要是卷积核列表)不易确定,效果不如BiLSTM+Attention;
- https://blog.csdn.net/dendi_hust/article/details/98211144