在这篇文章中,我将概述一些在PyTorch中加速深度学习模型训练时改动最小,影响最大的方法。对于每种方法,我会简要总结其思想,并估算预期的加速度,并讨论一些限制。我将着重于传达最重要的部分,并为每个部分给出额外的一些资源。大多数情况下,我会专注于可以直接在PyTorch中进行的更改,而不需要引入额外的库,并且我将假设你正在使用GPU训练模型。
注1:文末附【PyTorch】学习交流群
注2:整理不易,请点赞支持!
作者:LORENZ KUHN | 编译:ronghuaiyang
原出处:AI公园
原文链接:PyTorch深度学习模型训练加速指南2021
导读
简要介绍在PyTorch中加速深度学习模型训练的一些最小改动、影响最大的方法。我既喜欢效率又喜欢ML,所以我想我也可以把它写下来。
比如说,你正在PyTorch中训练一个深度学习模型。你能做些什么让你的训练更快结束?
在这篇文章中,我将概述一些在PyTorch中加速深度学习模型训练时改动最小,影响最大的方法。对于每种方法,我会简要总结其思想,并估算预期的加速度,并讨论一些限制。我将着重于传达最重要的部分,并为每个部分给出额外的一些资源。大多数情况下,我会专注于可以直接在PyTorch中进行的更改,而不需要引入额外的库,并且我将假设你正在使用GPU训练模型。
1. 考虑使用另外一种学习率策略
你选择的学习率对收敛速度以及模型的泛化性能有很大的影响。
循环学习率和1Cycle学习率策略都是Leslie N. Smith提出的方法,然后由fast.ai推广。本质上,1Cycle学习率策略看起来像这样:
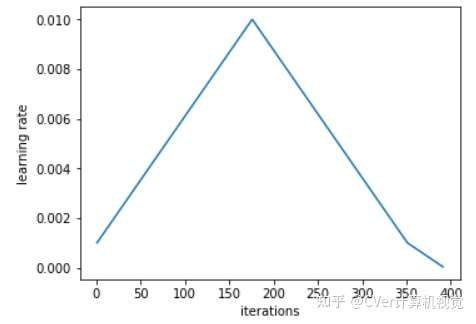
Sylvain写道:
[1cycle由两个相同长度的步骤组成,一个是从较低的学习率到较高的学习率,另一个步骤是回到最低的学习速率。最大值应该是使用Learning Rate Finder选择的值,较低的值可以低十倍。然后,这个周期的长度应该略小于epochs的总数,并且,在训练的最后一部分,我们应该允许学习率减少超过最小值几个数量级。
在最好的情况下,与传统的学习率策略相比,这种策略可以实现巨大的加速 —— Smith称之为“超级收敛”。例如,使用1Cycle策略,在ImageNet上减少了ResNet-56训练迭代数的10倍,就可以匹配原始论文的性能。该策略似乎在通用架构和优化器之间运行得很好。
PyTorch实现了这两个方法,torch.optim.lr_scheduler.CyclicLR和torch.optim.lr_scheduler.OneCycleLR。
这两个策略的一个缺点是它们引入了许多额外的超参数。为什么会这样呢?这似乎并不完全清楚,但一个可能的解释是,定期提高学习率有助于更快的穿越鞍点。
2. 在 DataLoader中使用多个workers和pinned memory
当使用torch.utils.data.DataLoader时,设置num_workers > 0,而不是等于0,设置pin_memory=True而不是默认值False。详细解释:https://pytorch.org/docs/stable/data.html。
Szymon Micacz通过使用4个workers和pinned memory,实现了单个训练epoch的2倍加速。
一个经验法则,选择workers的数量设置为可用GPU数量的4倍,更大或更小的workers数量会变慢。
注意,增加num_workers会增加CPU内存消耗。
3. 最大化batch size
这是一个颇有争议的观点。一般来说,然而,似乎使用GPU允许的最大的batch size可能会加速你的训练。注意,如果你修改了batch大小,你还必须调整其他超参数,例如学习率。这里的一个经验法则是,当你把batch数量翻倍时,学习率也要翻倍。
OpenAI有一篇很好的实证论文关于不同batch size需要的收敛步骤的数量。Daniel Huynh运行一些实验用不同batch大小(使用上面所讨论的1Cycle策略),从batch size 64到512他实现了4倍的加速。
然而,使用大batch的缺点之一是,它们可能会导致泛化能力比使用小batch的模型差。
4. 使用自动混合精度
PyTorch 1.6的发行版包含了对PyTorch进行自动混合精度训练的本地实现。这里的主要思想是,与在所有地方都使用单精度(FP32)相比,某些操作可以在半精度(FP16)下运行得更快,而且不会损失精度。然后,AMP自动决定应该以何种格式执行何种操作。这允许更快的训练和更小的内存占用。
AMP的使用看起来像这样:
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.cuda.amp.autocast():
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()在NVIDIA V100 GPU上对多个NLP和CV的benchmark进行测试,Huang和他的同事们发现使用AMP在FP32训练收益率常规大约2x,但最高可达5.5x。
目前,只有CUDA ops可以通过这种方式自动转换。
5. 考虑使用另外的优化器
AdamW是由fast.ai推广的具有权重衰减(而不是L2正则化)的Adam。现在可以在PyTorch中直接使用,torch.optim.AdamW。无论在误差还是训练时间上,AdamW都比Adam表现更好。
Adam和AdamW都可以很好地使用上面描述的1Cycle策略。
还有一些自带优化器最近受到了很多关注,最著名的是LARS和LAMB。
NVIDA的APEX实现了许多常见优化器的融合版本,如Adam。与Adam的PyTorch实现相比,这种实现避免了大量进出GPU内存的操作,从而使速度提高了5%。
6. 开启cudNN benchmarking
如果你的模型架构保持不变,你的输入大小保持不变,设置torch.backends.cudnn.benchmark = True可能是有益的。这使得cudNN能够测试许多不同的卷积计算方法,然后使用最快的方法。
对于加速的预期有一个粗略的参考,Szymon Migacz达到70%的forward的加速以及27%的forward和backward的加速。
这里需要注意的是,如果你像上面提到的那样将batch size最大化,那么这种自动调优可能会变得非常缓慢。
7. 注意CPU和GPU之间频繁的数据传输
小心使用tensor.cpu()和tensor.cuda()频繁地将张量从GPU和CPU之间相互转换。对于.item()和.numpy()也是一样,用.detach()代替。
如果你正在创建一个新的张量,你也可以使用关键字参数device=torch.device('cuda:0')直接将它分配给你的GPU。
如果你确实需要传输数据,在传输后使用.to(non_blocking=True)可能会很有用,只要你没有任何同步点。
如果你真的需要,你可以试试Santosh Gupta的SpeedTorch,虽然不是很确定在什么情况下可以加速。
8. 使用gradient/activation检查点
直接引用文档中的话:
检查点的工作原理是用计算交换内存,并不是存储整个计算图的所有中间激活用于向后计算,检查点不保存中间的激活,而是在向后传递中重新计算它们。可以应用于模型的任何部分。
具体来说,在向前传递中,function会以torch.no_grad()的方式运行,也就是说,不存储中间激活。相反,正向传递保存输入和function的参数。在向后传递中,将检索保存的输入和function,并再次根据function计算向前传递,然后跟踪中间的激活,再使用这些激活值计算梯度。
因此,虽然这可能会略微增加给定batch大小的运行时间,但会显著减少内存占用。这反过来会允许你进一步增加你正在使用的batch大小,从而更好地利用GPU。
检查点的pytorch实现为torch.utils.checkpoint,需要想点办法才能实现的很好。
9. 使用梯度累加
增加batch大小的另一种方法是在调用optimizer.step()之前,在多个.backward()中累积梯度。
在Hugging Face的实现中,梯度累加可以实现如下:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated
这个方法主要是为了避开GPU内存限制。fastai论坛上的这个讨论:https://forums.fast.ai/t/accumulating-gradients/33219/28似乎表明它实际上可以加速训练,所以可能值得一试。
10. 对于多个GPU使用分布式数据并行
对于分布式训练加速,一个简单的方法是使用torch.nn.DistributedDataParallel而不是torch.nn.DataParallel。通过这样做,每个GPU将由一个专用的CPU核心驱动,避免了DataParallel的GIL问题。
11. 将梯度设为None而不是0
使用.zero_grad(set_to_none=True)而不是.zero_grad()。这样做会让内存分配器去处理梯度,而不是主动将它们设置为0。正如在文档中所说的那样,这会导致产生一个适度的加速,所以不要期待任何奇迹。
注意,这样做并不是没有副作用的!关于这一点的详细信息请查看文档。
12. 使用.as_tensor() 而不是 .tensor()
torch.tensor() 会拷贝数据,如果你有一个numpy数组,你想转为tensor,使用 torch.as_tensor() 或是 torch.from_numpy() 来避免拷贝数据。
13. 需要的时候打开调试工具
Pytorch提供了大量的有用的调试工具,如autograd.profiler,autograd.grad_check和autograd.anomaly_detection。在需要的时候使用它们,在不需要它们的时候关闭它们,因为它们会减慢你的训练。
14. 使用梯度剪裁
最初是用于RNNs避免爆炸梯度,有一些经验证据和一些理论支持认为剪裁梯度(粗略地说:gradient = min(gradient, threshold))可以加速收敛。Hugging Face的Transformer实现是关于如何使用梯度剪裁以及其他的一些方法如AMP的一个非常干净的例子。
在PyTorch中,这可以通过使用torch.nn.utils.clip_grad_norm_实现。我并不完全清楚哪个模型从梯度裁剪中获益多少,但它似乎对RNN、基于Transformer和ResNets架构以及一系列不同的优化器都非常有用。
15. 在BatchNorm之前不使用bias
这是一个非常简单的方法:在BatchNormalization 层之前不使用bias。对于二维卷积层,可以将关键字bias设为False: torch.nn.Conv2d(..., bias=False, ...)。
你会保存一些参数,然而,与这里提到的其他一些方法相比,我对这个方法的加速期望相对较小。
16. 在验证的时候关闭梯度计算
这个很直接:在验证的时候使用 torch.no_grad() 。
17. 对输入和batch使用归一化
你可能已经这么做了,但你可能想再检查一下:
- 你的输入归一化了吗?
- 你是否在使用batch-normalization
来自评论的额外的技巧:使用 JIT融合point-wise的操作
如果你有point-wise的操作,你可以使用PyTorch JIT将它们合并成一个FusionGroup,这样就可以在单个核上启动,而不是像默认情况下那样在多个核上启动。你还可以节省一些内存的读写。
Szymon Migacz展示了如何使用@torch.jit脚本装饰器来融合GELU中的操作,例如:
@torch.jit.script
def fused_gelu(x):
return x * 0.5 * (1.0 + torch.erf(x / 1.41421))
在本例中,与未融合的版本相比,融合操作将导致fused_gelu的执行速度提高5倍。
一些相关的资源
上面列出的许多技巧来自Szymon Migacz的谈话,并发表在:https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html。
PyTorch Lightning的William Falcon有两篇文章:
https://towardsdatascience.com/7-tips-for-squeezing-maximum-performance-from-pytorch-ca4a40951259
其中有加速训练的技巧。PyTorch Lightning已经处理了上面默认的一些点。
Hugging Face的Thomas Wolf有很多关于加速深度学习的有趣文章,其中特别关注语言模型。
Sylvain Gugger和Jeremy Howard也有一些文章:
关于学习率策略的:https://sgugger.github.io/the-1cycle-policy.html,
关于找最佳学习率的:https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html
AdamW相关的:https://www.fast.ai/2018/07/02/adam-weight-decay/。
—END—
英文原文:https://efficientdl.com/faster-
导读
简要介绍在PyTorch中加速深度学习模型训练的一些最小改动、影响最大的方法。我既喜欢效率又喜欢ML,所以我想我也可以把它写下来。
比如说,你正在PyTorch中训练一个深度学习模型。你能做些什么让你的训练更快结束?
在这篇文章中,我将概述一些在PyTorch中加速深度学习模型训练时改动最小,影响最大的方法。对于每种方法,我会简要总结其思想,并估算预期的加速度,并讨论一些限制。我将着重于传达最重要的部分,并为每个部分给出额外的一些资源。大多数情况下,我会专注于可以直接在PyTorch中进行的更改,而不需要引入额外的库,并且我将假设你正在使用GPU训练模型。
1. 考虑使用另外一种学习率策略
你选择的学习率对收敛速度以及模型的泛化性能有很大的影响。
循环学习率和1Cycle学习率策略都是Leslie N. Smith提出的方法,然后由fast.ai推广。本质上,1Cycle学习率策略看起来像这样:
Sylvain写道:
[1cycle由两个相同长度的步骤组成,一个是从较低的学习率到较高的学习率,另一个步骤是回到最低的学习速率。最大值应该是使用Learning Rate Finder选择的值,较低的值可以低十倍。然后,这个周期的长度应该略小于epochs的总数,并且,在训练的最后一部分,我们应该允许学习率减少超过最小值几个数量级。
在最好的情况下,与传统的学习率策略相比,这种策略可以实现巨大的加速 —— Smith称之为“超级收敛”。例如,使用1Cycle策略,在ImageNet上减少了ResNet-56训练迭代数的10倍,就可以匹配原始论文的性能。该策略似乎在通用架构和优化器之间运行得很好。
PyTorch实现了这两个方法,torch.optim.lr_scheduler.CyclicLR和torch.optim.lr_scheduler.OneCycleLR。
这两个策略的一个缺点是它们引入了许多额外的超参数。为什么会这样呢?这似乎并不完全清楚,但一个可能的解释是,定期提高学习率有助于更快的穿越鞍点。
2. 在 DataLoader中使用多个workers和pinned memory
当使用torch.utils.data.DataLoader时,设置num_workers > 0,而不是等于0,设置pin_memory=True而不是默认值False。详细解释:https://pytorch.org/docs/stable/data.html。
Szymon Micacz通过使用4个workers和pinned memory,实现了单个训练epoch的2倍加速。
一个经验法则,选择workers的数量设置为可用GPU数量的4倍,更大或更小的workers数量会变慢。
注意,增加num_workers会增加CPU内存消耗。
3. 最大化batch size
这是一个颇有争议的观点。一般来说,然而,似乎使用GPU允许的最大的batch size可能会加速你的训练。注意,如果你修改了batch大小,你还必须调整其他超参数,例如学习率。这里的一个经验法则是,当你把batch数量翻倍时,学习率也要翻倍。
OpenAI有一篇很好的实证论文关于不同batch size需要的收敛步骤的数量。Daniel Huynh运行一些实验用不同batch大小(使用上面所讨论的1Cycle策略),从batch size 64到512他实现了4倍的加速。
然而,使用大batch的缺点之一是,它们可能会导致泛化能力比使用小batch的模型差。
4. 使用自动混合精度
PyTorch 1.6的发行版包含了对PyTorch进行自动混合精度训练的本地实现。这里的主要思想是,与在所有地方都使用单精度(FP32)相比,某些操作可以在半精度(FP16)下运行得更快,而且不会损失精度。然后,AMP自动决定应该以何种格式执行何种操作。这允许更快的训练和更小的内存占用。
AMP的使用看起来像这样:
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.cuda.amp.autocast():
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
在NVIDIA V100 GPU上对多个NLP和CV的benchmark进行测试,Huang和他的同事们发现使用AMP在FP32训练收益率常规大约2x,但最高可达5.5x。
目前,只有CUDA ops可以通过这种方式自动转换。
5. 考虑使用另外的优化器
AdamW是由fast.ai推广的具有权重衰减(而不是L2正则化)的Adam。现在可以在PyTorch中直接使用,torch.optim.AdamW。无论在误差还是训练时间上,AdamW都比Adam表现更好。
Adam和AdamW都可以很好地使用上面描述的1Cycle策略。
还有一些自带优化器最近受到了很多关注,最著名的是LARS和LAMB。
NVIDA的APEX实现了许多常见优化器的融合版本,如Adam。与Adam的PyTorch实现相比,这种实现避免了大量进出GPU内存的操作,从而使速度提高了5%。
6. 开启cudNN benchmarking
如果你的模型架构保持不变,你的输入大小保持不变,设置torch.backends.cudnn.benchmark = True可能是有益的。这使得cudNN能够测试许多不同的卷积计算方法,然后使用最快的方法。
对于加速的预期有一个粗略的参考,Szymon Migacz达到70%的forward的加速以及27%的forward和backward的加速。
这里需要注意的是,如果你像上面提到的那样将batch size最大化,那么这种自动调优可能会变得非常缓慢。
7. 注意CPU和GPU之间频繁的数据传输
小心使用tensor.cpu()和tensor.cuda()频繁地将张量从GPU和CPU之间相互转换。对于.item()和.numpy()也是一样,用.detach()代替。
如果你正在创建一个新的张量,你也可以使用关键字参数device=torch.device('cuda:0')直接将它分配给你的GPU。
如果你确实需要传输数据,在传输后使用.to(non_blocking=True)可能会很有用,只要你没有任何同步点。
如果你真的需要,你可以试试Santosh Gupta的SpeedTorch,虽然不是很确定在什么情况下可以加速。
8. 使用gradient/activation检查点
直接引用文档中的话:
检查点的工作原理是用计算交换内存,并不是存储整个计算图的所有中间激活用于向后计算,检查点不保存中间的激活,而是在向后传递中重新计算它们。可以应用于模型的任何部分。
具体来说,在向前传递中,
function会以torch.no_grad()的方式运行,也就是说,不存储中间激活。相反,正向传递保存输入和function的参数。在向后传递中,将检索保存的输入和function,并再次根据function计算向前传递,然后跟踪中间的激活,再使用这些激活值计算梯度。
因此,虽然这可能会略微增加给定batch大小的运行时间,但会显著减少内存占用。这反过来会允许你进一步增加你正在使用的batch大小,从而更好地利用GPU。
检查点的pytorch实现为torch.utils.checkpoint,需要想点办法才能实现的很好。
9. 使用梯度累加
增加batch大小的另一种方法是在调用optimizer.step()之前,在多个.backward()中累积梯度。
在Hugging Face的实现中,梯度累加可以实现如下:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated
这个方法主要是为了避开GPU内存限制。fastai论坛上的这个讨论:https://forums.fast.ai/t/accumulating-gradients/33219/28似乎表明它实际上可以加速训练,所以可能值得一试。
10. 对于多个GPU使用分布式数据并行
对于分布式训练加速,一个简单的方法是使用torch.nn.DistributedDataParallel而不是torch.nn.DataParallel。通过这样做,每个GPU将由一个专用的CPU核心驱动,避免了DataParallel的GIL问题。
11. 将梯度设为None而不是0
使用.zero_grad(set_to_none=True)而不是.zero_grad()。这样做会让内存分配器去处理梯度,而不是主动将它们设置为0。正如在文档中所说的那样,这会导致产生一个适度的加速,所以不要期待任何奇迹。
注意,这样做并不是没有副作用的!关于这一点的详细信息请查看文档。
12. 使用.as_tensor() 而不是 .tensor()
torch.tensor() 会拷贝数据,如果你有一个numpy数组,你想转为tensor,使用 torch.as_tensor() 或是 torch.from_numpy() 来避免拷贝数据。
13. 需要的时候打开调试工具
Pytorch提供了大量的有用的调试工具,如autograd.profiler,autograd.grad_check和autograd.anomaly_detection。在需要的时候使用它们,在不需要它们的时候关闭它们,因为它们会减慢你的训练。
14. 使用梯度剪裁
最初是用于RNNs避免爆炸梯度,有一些经验证据和一些理论支持认为剪裁梯度(粗略地说:gradient = min(gradient, threshold))可以加速收敛。Hugging Face的Transformer实现是关于如何使用梯度剪裁以及其他的一些方法如AMP的一个非常干净的例子。
在PyTorch中,这可以通过使用torch.nn.utils.clip_grad_norm_实现。我并不完全清楚哪个模型从梯度裁剪中获益多少,但它似乎对RNN、基于Transformer和ResNets架构以及一系列不同的优化器都非常有用。
15. 在BatchNorm之前不使用bias
这是一个非常简单的方法:在BatchNormalization 层之前不使用bias。对于二维卷积层,可以将关键字bias设为False: torch.nn.Conv2d(..., bias=False, ...)。
你会保存一些参数,然而,与这里提到的其他一些方法相比,我对这个方法的加速期望相对较小。
16. 在验证的时候关闭梯度计算
这个很直接:在验证的时候使用 torch.no_grad() 。
17. 对输入和batch使用归一化
你可能已经这么做了,但你可能想再检查一下:
- 你的输入归一化了吗?
- 你是否在使用batch-normalization
来自评论的额外的技巧:使用 JIT融合point-wise的操作
如果你有point-wise的操作,你可以使用PyTorch JIT将它们合并成一个FusionGroup,这样就可以在单个核上启动,而不是像默认情况下那样在多个核上启动。你还可以节省一些内存的读写。
Szymon Migacz展示了如何使用@torch.jit脚本装饰器来融合GELU中的操作,例如:
@torch.jit.script
def fused_gelu(x):
return x * 0.5 * (1.0 + torch.erf(x / 1.41421))
在本例中,与未融合的版本相比,融合操作将导致fused_gelu的执行速度提高5倍。
一些相关的资源
上面列出的许多技巧来自Szymon Migacz的谈话,并发表在:https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html。
PyTorch Lightning的William Falcon有两篇文章:
https://towardsdatascience.com/9-tips-for-training-lightning-fast-neural-networks-in-pytorch-8e63a502f565
https://towardsdatascience.com/7-tips-for-squeezing-maximum-performance-from-pytorch-ca4a40951259
其中有加速训练的技巧。PyTorch Lightning已经处理了上面默认的一些点。
Hugging Face的Thomas Wolf有很多关于加速深度学习的有趣文章,其中特别关注语言模型。
Sylvain Gugger和Jeremy Howard也有一些文章:
关于学习率策略的:https://sgugger.github.io/the-1cycle-policy.html,
关于找最佳学习率的:https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html
AdamW相关的:https://www.fast.ai/2018/07/02/adam-weight-decay/。
—END—
英文原文:https://efficientdl.com/faster-deep-learning-in-pytorch-a-guide/