Faiss库是由 Facebook 开发的适用于稠密向量匹配的开源库,支持 c++ 与 python 调用。
通过实验证实,128维的125W向量,在 CPU 下检索耗时约70ms,经过 GPU 加速后检索耗时仅5ms。
一、安装
Faiss 支持直接通过 conda 安装 python 接口,以及通过源码编译方式安装 c++ 和 python 接口,以下我会分别进行说明。
Conda 安装
Conda 下可以分别安装 cpu 与 gpu 两种版本
# CPU version only
conda install faiss-cpu -c pytorch
# GPU version
conda install faiss-gpu cudatoolkit=8.0 -c pytorch # For CUDA8
conda install faiss-gpu cudatoolkit=9.0 -c pytorch # For CUDA9
conda install faiss-gpu cudatoolkit=10.0 -c pytorch # For CUDA10二、源码编译
Faiss 在编译前需要预先完成依赖项的配置,这里的依赖项仅包括 openblas 与 lapack ,关于这两个依赖项的安装说明本文就不叙述了。
在安装完上述两个数学库之后,需执行 BLAS 的测试用例,若无报错即代表数学库安装成功。
# 进入Faiss源码目录
cd faiss
# 根据系统配置选取makefile配置文件
cp example_makefiles/makefile.inc.Linux ./makefile.inc
# 检查环境是否符合编译条件
./configure
# 编译测试用例,运行无报错则表明数学库安装成功
make misc/test_blas
./misc/test_blas在测试完成后即可执行 make 进行算法库的生成。需要说明的是,如果通过源码编译的方式安装 python 接口,需预先安装 swig,并修改 makefile.inc 中相关设置。
# 修改makefile.inc
SWIG = /usr/local/bin/swig
prefix ?= /usr/local/share/swig/3.0.12
PYTHONCFLAGS = -I/usr/include/python2.7
-I/usr/local/lib/python2.7/dist-packages/numpy/core/include三、使用
Faiss 支持多种向量检索方式,包括内积、欧氏距离等,同时支持精确检索与模糊搜索,篇幅有限嘛,我就先简单介绍精确检索相关内容。
一般来说,Faiss 的使用涉及两个概念:data — 包含了被检索的所有向量,即数据库;query — 索引值,Faiss 据此查找到对应向量在数据库 data 中的所在位置。
精确检索
精确检索不需要对数据进行训练操作,通过提供的索引方式来遍历数据库,精确计算查询向量与被查询向量之间距离,这里的距离可以是欧氏距离 (IndexFlatL2) 或内积 (IndexFlatIP) 等。
Faiss 的使用是围绕着 index 这一对象进行的,index 中包含了被索引的数据库向量以及对应的索引值。在构建 index 时,需预先提供数据库中每个向量的维度 d,随后通过 add() 的方式将被检索向量存入 index 中,最终通过 search() 接口获取与检索向量最邻近 topk 的距离及索引。
Python接口
# 创建index对象
index = faiss.IndexFlatIP(feature_dim)
# 将数据集加载入index中
index.add(np.ascontiguousarray(Datasets['feature']))
# 获取index中向量的个数
print(index.ntotal)
# 获取与检索向量最邻近的topk的距离distance与索引值match_idx
distance, match_idx = index.search(feature.reshape(1,-1), topk)c++接口与 python 接口基本一致,大家看着来就行。
GPU加速
Faiss 可以通过 GPU 进行硬件加速,极大的提升检索速度。
Python 接口
# 采用单卡GPU
res = faiss.StandardGpuResources()
# 创建index
index_flat = faiss.IndexFlatL2(d)
# 将index置入GPU下
gpu_index_flat = faiss.index_cpu_to_gpu(res, 0, index_flat)
四、Faiss结合Sentence_Bert
双语原文链接:Billion-scale semantic similarity search with FAISS+SBERT
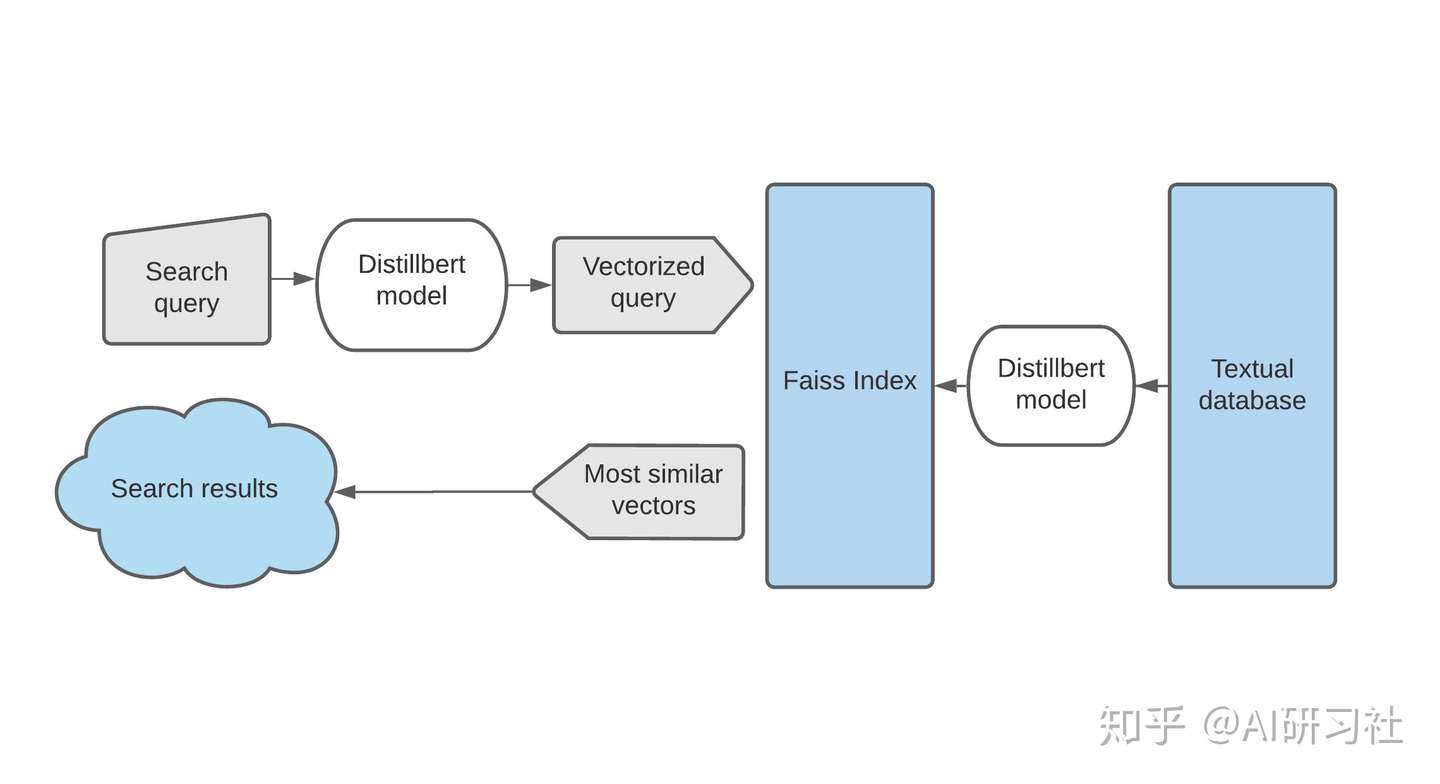
介绍
语义搜索是一种关注句子意义而不是传统的关键词匹配的信息检索系统。尽管有许多文本嵌入可用于此目的,但将其扩展到构建低延迟api以从大量数据集合中获取数据是很少讨论的。在本文中,我将讨论如何使用SOTA语句嵌入(语句转换器)和FAISS来实现最小语义搜索引擎。
句子Transformers
它是一个框架或一组模型,给出句子或段落的密集向量表示。这些模型是transformer网络(BERT、RoBERTa等),它们专门针对语义文本相似性的任务进行了微调,因为BERT在这些任务中执行得不是很好。下面给出了不同模型在STS基准测试中的性能。
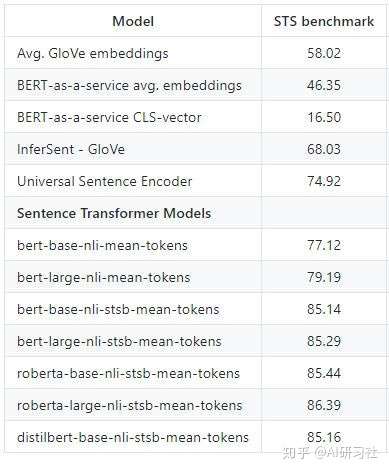
图片来源:句子 transformers
我们可以看到句子transformer模型比其他模型有很大的优势。
但是如果你用代码和GLUE来看看排行榜,你会看到很多的模型超过90。为什么我们需要句子transformers?
在这些模型中,语义文本相似度被视为一个回归任务。这意味着,每当我们需要计算两个句子之间的相似度得分时,我们需要将它们一起传递到模型中,然后模型输出它们之间的数值分数。虽然这对于基准测试很有效,但是对于实际的用例来说,它的伸缩性很差,原因如下。
1.当你需要搜索大约10k个文档时,你需要进行10k个独立的推理计算,不可能单独计算嵌入量而只计算余弦相似度。见作者的解释。
2.最大序列长度(模型一次可以接受的单词/标记的总数)在两个文档之间共享,这会导致的表示的含义由于分块而被稀释
FAISS
Faiss是一个基于C++的库,由FacebookAI构建,在Python中有完整的包装器,用于索引矢量化数据并对其进行有效的搜索。Faiss基于以下因素提供了不同的索引。
- 搜索时间
- 搜索质量
- 每个索引向量使用的内存
- 训练时间
- 无监训练需要外部数据
因此,选择合适的指数将是这些因素之间的权衡。
加载模型并对数据集执行推理
首先,让我们安装并加载所需的库
| !pip install faiss-cpu !pip install -U sentence-transformersimport numpy as npimport torchimport osimport pandas as pdimport faissimport timefrom sentence_transformers import SentenceTransformer |
加载一个包含一百万个数据点的数据集
我使用了一个来自Kaggle的数据集,其中包含了17年来出版的新闻标题。
| df=pd.read_csv("abcnews-date-text.csv") data=df.headline_text.to_list() |
加载预训练模型并且进行推断
| model = SentenceTransformer('distilbert-base-nli-mean-tokens')encoded_data = model.encode(data) |
为数据集编制索引
我们可以根据我们的用例通过参考指南来选择不同的索引选项。
让我们定义索引并向其添加数据
| index = faiss.IndexIDMap(faiss.IndexFlatIP(768))index.add_with_ids(encoded_data, np.array(range(0, len(data)))) |
序列化索引
| faiss.write_index(index, 'abc_news') |
将序列化的索引导出到托管搜索引擎的任何计算机中
反序列化索引
| index = faiss.read_index('abc_news') |
执行语义相似性搜索
让我们首先为搜索构建一个包装函数
| def search(query): t=time.time() query_vector = model.encode([query]) k = 5 top_k = index.search(query_vector, k) print('totaltime: {}'.format(time.time()-t)) return [data[_id] for _id in top_k[1].tolist()[0]] |
执行搜索
| query=str(input()) results=search(query)print('results :')for result in results: print(' ' |
CPU中的结果
现在让我们看看搜索结果和响应时间
只需1.5秒,就可以在仅使用CPU后端的百万文本文档的数据集上执行基于意义的智能搜索。
GPU中的结果
首先让我们关闭CPU版本的Faiss并重启GPU版本
| !pip uninstall faiss-cpu !pip install faiss-gpu |
之后执行相同步骤,但是最后将索引移到GPU上。
| res = faiss.StandardGpuResources() gpu_index = faiss.index_cpu_to_gpu(res, 0, index) |
现在让我们转移这个搜索方法并用GPU执行这个搜索
很好,你可以在0.02秒内得到结果,使用GPU(在这个实验中使用了Tesla T4),它比CPU后端快75倍
但是为什么我不能仅仅序列化编码数据的NumPy数组而不是索引它们呢?如果我能等几秒钟的话,使用余弦相似性呢?
因为NumPy没有序列化函数,因此唯一的方法是将其转换为JSON,然后保存JSON对象,但是大小将增加五倍。例如,在768维向量空间中编码的一百万个数据点具有正常的索引,大约为3GB,将其转换为JSON将使其成为15GB,而普通机器无法保存它的RAM。因此,每次执行搜索时,我们都要运行一百万次计算推理,这是不实际的。
最后的想法
这是一个基本的实现,在语言模型部分和索引部分仍然需要做很多工作。有不同的索引选项,应该根据用例、数据大小和可用的计算能力选择正确的索引选项。另外,这里使用的句子嵌入只是对一些公共数据集进行了微调,在特定领域的数据集上对它们进行微调可以改进,从而提高搜索结果。
五、参考文献
[1] Nils Reimers and Iryna Gurevych. “Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation.” arXiv (2020): 2004.09813.
[2]Johnson, Jeff and Douze, Matthijs and J{’e}gou, Herv{’e}. “Billion-scale similarity search with GPUs” arXiv preprint arXiv:1702.08734.
六、实战
import numpy as np import torch import os import pandas as pd import faiss import time from sentence_transformers import SentenceTransformer class SemanticMatch(object): def __init__(self): parent_path = os.path.split(os.path.realpath(__file__))[0] self.root = parent_path[:parent_path.find("models")] #E:personassemantics data_path = os.path.join(self.root, "datas", "finally_data", "train_data.csv") df = pd.read_csv(data_path, sep=" ") self.data = df["sentence"].to_list() self.y = df["y"].to_list() self.bert_model_path = os.path.join(self.root, "checkpoints", "two_albert_similarity_model") self.bert_model = SentenceTransformer(self.bert_model_path) self.match_path = os.path.join(self.root,"datas", "match_data", "match.csv") self.match_data = pd.read_csv(self.match_path, sep=" ") self.key_yuyin = ["calling", "SUBSCRIBER", "SORRY", "小飞", "小智", "呼叫", "智能", "小爱"] self.key_xiexie = ["谢谢", "好的", "知道", "收到"] self.key_zhuanda = ["转达", "我爸爸", "帮你带着话", "我是他女儿", "帮你转"] self.name_list = ["yuyin", "xiexie", "zhuanda"] self.dict_key = { "yuyin": self.key_yuyin, "xiexie": self.key_xiexie, "zhuanda": self.key_zhuanda } def bert(self, query): encoded_data = self.bert_model.encode(self.data) encoded_data = np.array(encoded_data) print(encoded_data.shape) print("开始创建索引") index = faiss.IndexFlatL2(512) index.add(encoded_data) #序列化持久存储 faiss.write_index(index, 'abc_news') #反序列化index = faiss.read_index('abc_news') t = time.time() print("开始查询") query_vector = self.bert_model.encode([query]) k = 10 top_k = index.search(query_vector, k) print('totaltime: {}'.format(time.time() - t)) print(top_k) return [self.data[_id] for _id in top_k[1].tolist()[0]] def main(self): print("开始执行") results = self.bert("你好") print('results :') for result in results: print(' ', result) def get_index(self, query): print("选择了所有faiss") index = faiss.read_index('abc_news') t = time.time() print("开始查询") query_vector = self.bert_model.encode([query]) k = 20 top_k = index.search(query_vector, k) print('查询耗费了多少秒: {}'.format(time.time() - t)) print(top_k) result = [self.data[_id] for _id in top_k[1].tolist()[0]] y = [self.y[_id] for _id in top_k[1].tolist()[0]] return result, y def get_index_from_sub(self, query, faiss_n): data_path = os.path.join(self.root, "datas", "match_data", faiss_n + ".csv") df = pd.read_csv(data_path, sep=" ") data = df["sentence"].to_list() y = df["y"].to_list() index = faiss.read_index(faiss_n + ".faiss") t = time.time() print("开始查询") query_vector = self.bert_model.encode([query]) k = 20 top_k = index.search(query_vector, k) print('查询耗费了多少秒: {}'.format(time.time() - t)) print(top_k) result = [data[_id] for _id in top_k[1].tolist()[0]] y = [y[_id] for _id in top_k[1].tolist()[0]] return result, y def bert_match(self): s = self.match_data["sentence"] y = self.match_data["y"] i = 0 j = 0 for s1, y1 in zip(s, y): i = i + 1 print("=============================开始新一轮查询===============================") result, y = self.search_key(s1) print("查询值:", s1) print("相似度最高的20的类别:", y) print("标注的类别:", y1) print("相似度最高的语句:", result) maxlabel = max(y, key=y.count) if maxlabel == y1: j = j+ 1 print(j/i) def write_faiss(self, _data, faiss_name): encoded_data = self.bert_model.encode(_data) encoded_data = np.array(encoded_data) print("开始创建索引") index = faiss.IndexFlatL2(512) index.add(encoded_data) #序列化持久存储 faiss.write_index(index, faiss_name + ".faiss") def creat_faiss_file(self): for name in self.name_list: file_path = os.path.join(self.root, "datas", "match_data", name + ".csv") df = pd.read_csv(file_path, sep=" ") data_list = df["sentence"].to_list() faiss_name = name self.write_faiss(data_list, faiss_name) def search_key(self, query): faiss_name = [] for k,v in self.dict_key.items(): for key in v: if key in query: faiss_name.append(k) faiss_name = set(faiss_name) print("选择faiss:", faiss_name) if len(faiss_name) > 0: r, label = [], [] for faiss_n in faiss_name: result, y = self.get_index_from_sub(query, faiss_n) r.extend(result) label.extend(y) return r, label else: r, label = self.get_index(query) return r, label def main(self): s = self.match_data["sentence"] y = self.match_data["y"] i = 0 j = 0 for s1, y1 in zip(s, y): i = i + 1 print("=============================开始新一轮查询===============================") result, y = self.search_key(s1) print("查询值:", s1) print("相似度最高的20的类别:", y) print("标注的类别:", y1) print("相似度最高的语句:", result) maxlabel = max(y, key=y.count) if maxlabel == y1: j = j+ 1 print(j/i) if __name__ == '__main__': SemanticMatch().main()