1、并行和强制走索引的用法
SELECT/*+parallel(T 16) parallel(B 16) parallel(D 16)*/
T.POLICY_NO,
T.DEPARTMENT_CODE,
T.PLAN_CODE,
FROM EPCIS_AUTO_POLICY_BASE_INFO T ,
EPCIS_AUTO_POLICY_VEHICLE_INFO B,
EPCIS_AUTO_A_PRE_MID_RESULT D
WHERE T.POLICY_NO = B.POLICY_NO
AND T.APPLY_POLICY_NO = D.APPLY_POLICY_NO(+)
AND T.LAST_BEGIN_DATE >=
ADD_MONTHS(TRUNC(TO_DATE('20151101', 'YYYYMMDD'), 'YYYY'), 9)
AND T.LAST_BEGIN_DATE <
LEAST(TO_DATE('20151201', 'YYYYMMDD'),
ADD_MONTHS(TRUNC(TO_DATE('20151101', 'YYYYMMDD'), 'YYYY'), 12))
AND T.UNDERWRITE_TIME < TO_DATE('20151201', 'YYYYMMDD')
--强制走索引
seg是表的别名
/*+INDEX(SEG IDX_T_RES_ALLOSEG_ALLOID)*/
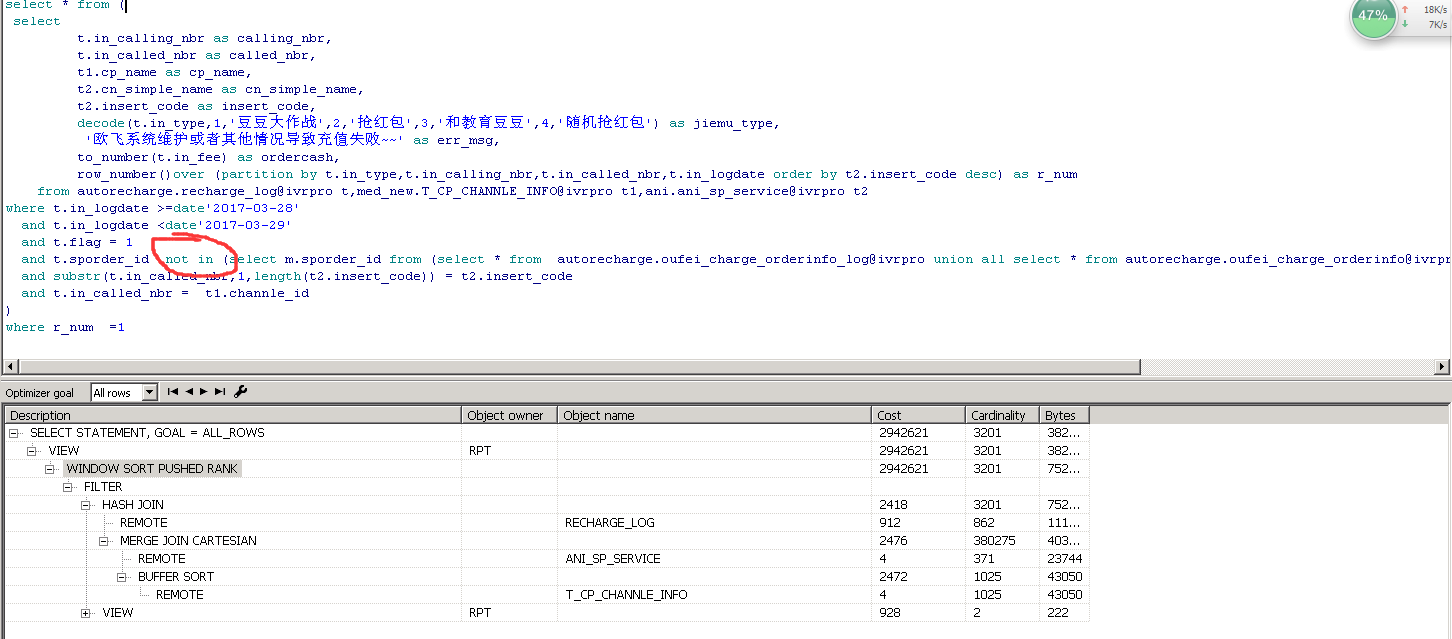
2、在用分析函数的时候一定要注意,再外面嵌套子查询的时候,会导致执行计划改变
虽然里层的sql单独查询很快,但是一旦套嵌上了子查询后,执行计划就会变化,并不是说只是的单纯的将里面的结果集外面再查询,否则也不会一直查不出来、、、
这种情况的原因是里层的where条件中某些条件需要查较大的表;可考虑优化里层的where条件;
结论:
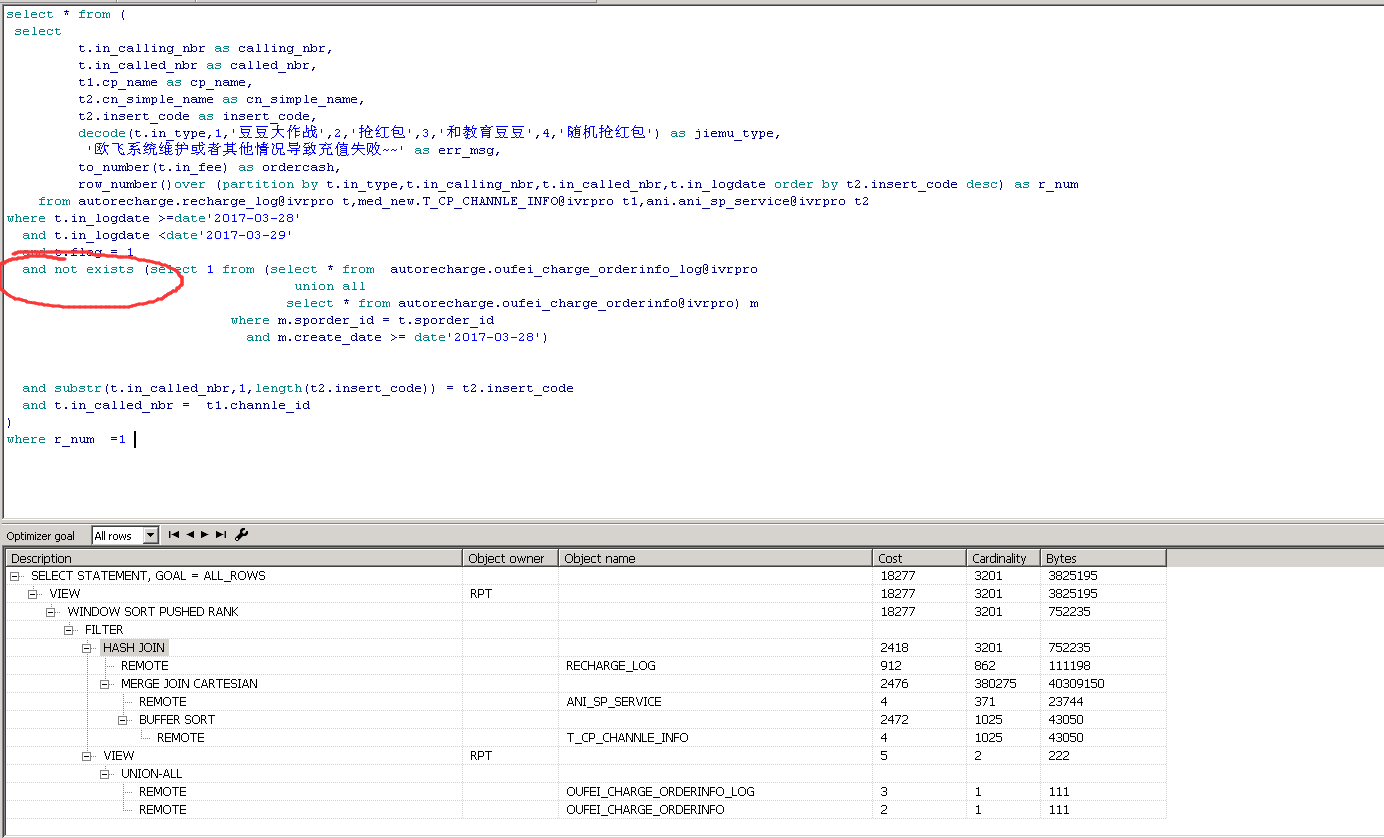
只要以后用到分析函数的,where子句的的 in 或者not in 都换成 exists;
select * from ( select t.in_calling_nbr as calling_nbr, t.in_called_nbr as called_nbr, t1.cp_name as cp_name, t2.cn_simple_name as cn_simple_name, t2.insert_code as insert_code, decode(t.in_type,1,'豆豆大作战',2,'抢红包',3,'和教育豆豆',4,'随机抢红包') as jiemu_type, '欧飞系统维护或者其他情况导致充值失败~~' as err_msg, to_number(t.in_fee) as ordercash, row_number()over (partition by t.in_type,t.in_calling_nbr,t.in_called_nbr,t.in_logdate order by t2.insert_code desc) as r_num from autorecharge.recharge_log@ivrpro t,med_new.T_CP_CHANNLE_INFO@ivrpro t1,ani.ani_sp_service@ivrpro t2 where t.in_logdate >=date'2017-03-28' and t.in_logdate <date'2017-03-29' and t.flag = 1 and not exists (select 1 from (select * from autorecharge.oufei_charge_orderinfo_log@ivrpro union all select * from autorecharge.oufei_charge_orderinfo@ivrpro) m where m.sporder_id = t.sporder_id and m.create_date >= date'2017-03-28') and substr(t.in_called_nbr,1,length(t2.insert_code)) = t2.insert_code and t.in_called_nbr = t1.channle_id ) where r_num =1 ;
优化后:
Oracle中用一个表的数据更新另一个表的数据
①、普通的数据量较小时:
update tab1 set val=(select val from tab2 where tab1.id=tab2.id) [where exists (select 1 from tab2 where tab1.id=tab2.id)];
②、数据量比较多的话:
merge终极版:
merge into tab1 using (select * from tab2 x where x.rowid = (select max(y.rowid) from tab2 y where x.id = y.id)) tab2 on(tab1.id=tab2.id) when
matched then update set tab1.val = tab2.val