hystrix不仅用作工程可靠性还可以用来运维。
这里将会分享一个拥有100+Hystrix命令,40+线程池,每天有100亿次线程请求,2000亿次信号量请求的系统是如何使用hystrix运维的。这里的截图和问题分析都是来自于netflix api系统的真实环境。
如何配置和调优依赖调用
通常部署和配置一个依赖调用,需要根据它在生成环境情况下不断调优期配置。实践过程如下:
1.使用默认1000ms的timeout时间,除非有必要修改它。
2.使用默认10个线程池,除非有必要修改它。
3.使用灰度发布,如果运行正常,继续发布。
4.在生产环境运行24小时。
5.观察监控和报警。
6.在运行24小时后,根据流量和延时计算最严格的熔断器配置
7.改变配置并且持续观察
8.如果系统性能发生改变,则继续调整配置。
下面的图表展示了如何选择线程池大小,队列大小,timeout时间。
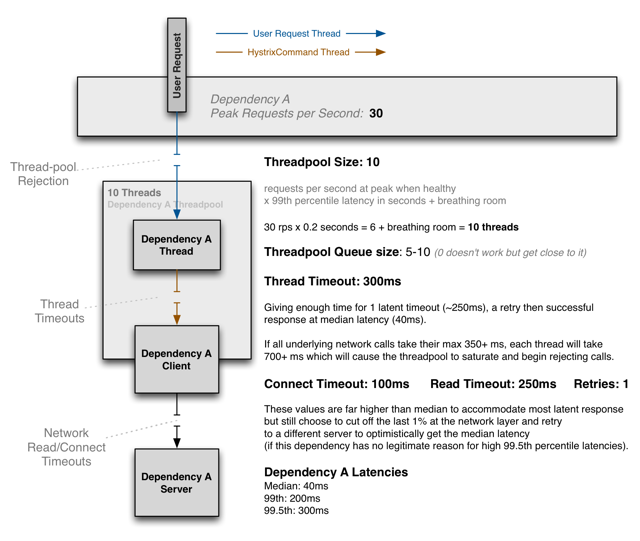
对大多数的熔断器来说,应该设置timeout的值接近99.5%的系统请求延时,这样可以保证异常请求不会耗尽系统资源。也需要调整线程池和队列大小,避免资源被耗尽。
配置和调优依赖调用的原则:
- 根据实际的流量调整
- 根据监控不断调整设置
合理的抖动和失败
Hystrix使用毫秒级的粒度来测量和报告监控数据。在大型的集群中,超时、线程池拒绝、延时等问题在任何时刻都可能出现。
下面的图显示了netflix api 监控的命令报表。黄色的和紫色的数字分别代表243台机器10秒内超时和线程池拒绝的个数。
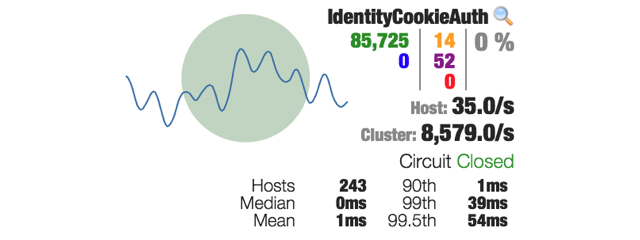
大多数的系统有很多的异常抖动,甚至会突破延时比率。 在Hystrix中,你能清晰的看到系统的表现。你会看到很多延时数据,是没有用Hystrix执行无法看到的。 有以下几类原因:
- 本机进行垃圾回收。
- 依赖服务进行垃圾回收。
- 网络问题。
- 不同请求的负载不同。
- 缓存失效。
- 突发的大量请求。
- 部署发布。
延时
如果发现有延时,并不需要马上更改配置。如果配置正确,Hystrix会正确执行降级。
在Netflix使用Hystrix初期,当系统出现延时或异常时,我们共同的反应是动态更改配置来提高线程池大小,timeout时间,来让他恢复工作。但这是错误的,如果你的系统配置是合理的,当出现timeout,拒绝,熔断时,首先应该解决问题的根本原因。
不要设置过大的配置,这样会导致资源被耗尽。
举一个例子,假设现在有一个100台机器组成的集群,每个机器设置10个并发连接。那么总的机器可以处理1000个并发链接。正常情况下一般有200~300个并发连接,现在因为系统延时的原因,连接数变成了1000个。如果我们把并发数调成每个机器20个,我们会发现并发数会上升到2000。这样只会使情况更加糟糕。这也是熔断器存在的一个原因,在系统性能变成时,减少系统的压力来给系统一段时间进行恢复。
举一个例子,有一个被依赖的服务出现了很高的延时并且引起了熔断,但整个系统只有这一个服务被熔断了,其他的服务依然可以正常运行。
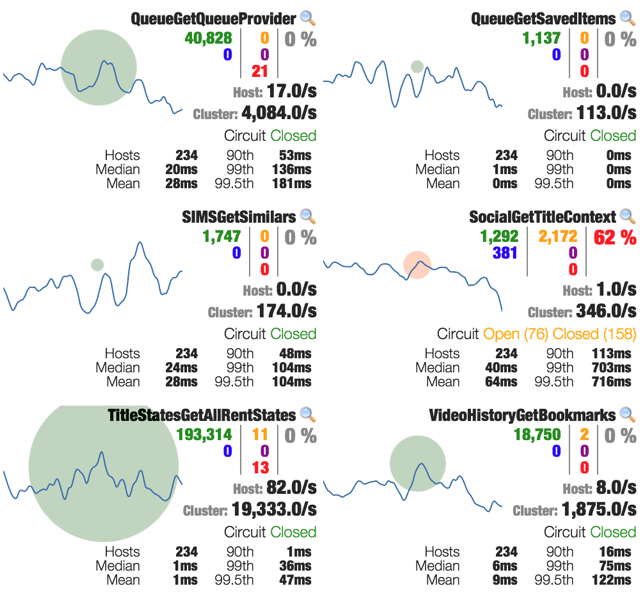
总而言之,当服务被熔断、超时、线程池拒绝时,在Hystrix层面需要服务自己恢复到正常状态而不是更改Hystrix配置。Hystrix就是用来隔离延时的服务,让他们可以快速恢复的工具。
依赖的失败
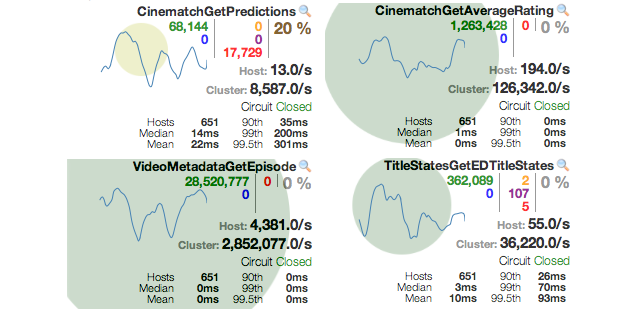
上面的图表显示了有一个服务有20%的异常,有严重的影响,但还没有被熔断。但其他几个服务都没有受到影响。这个例子中我们会发现,这服务大部分是异常而非延迟,因为黄色的数字0代表延时,而红色的数字17729代表异常。
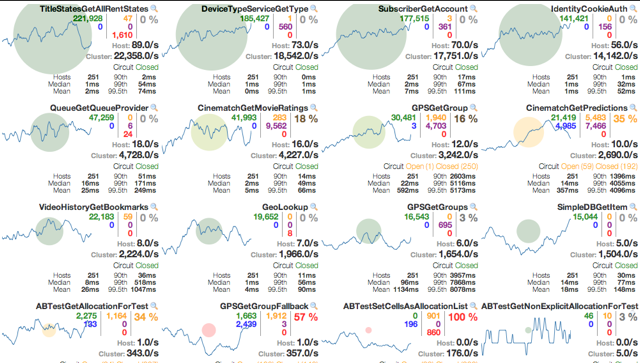
下面的一张表显示了有这种类型的异常的服务的趋势
依赖失败降级
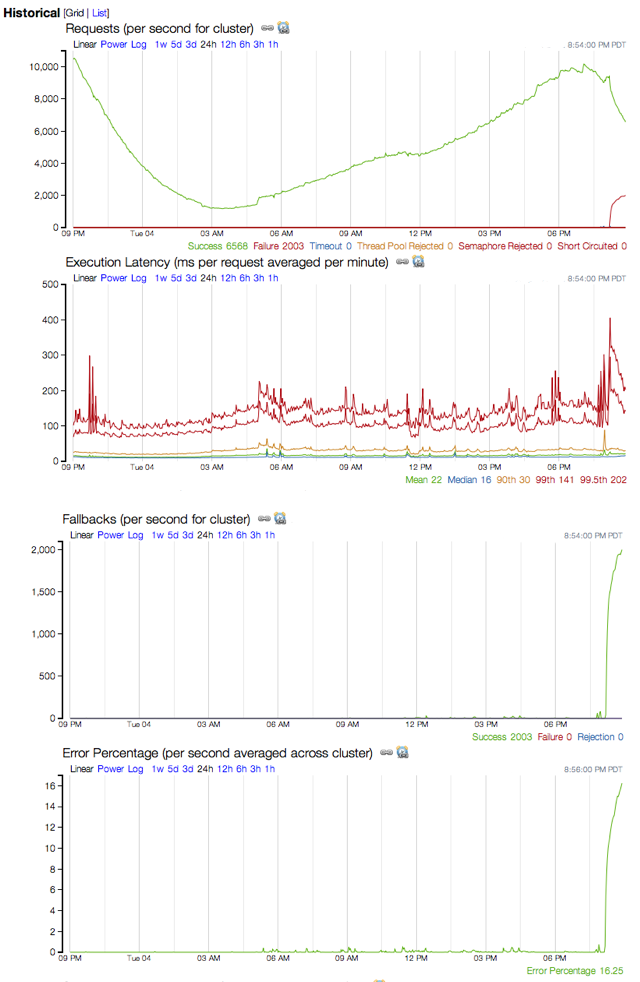
下面的截图显示了一个因为异常而出现的熔断。有99.5的请求延迟了。依赖服务执行过程将导致线程池耗尽和timeout异常。但是整个系统只有一个服务出现了熔断,蓝色的数字表示熔断而拒绝的请求数,黄色的数字表示timeout的请求数。

因为熔断服务执行了降级操作,返回了降级结果,所以其他的服务都正常。
连级失败
下面的图表显示了因为一个服务的性能延时,导致了整个系统的性能延时。
下图解释了防止连级错误的方法:
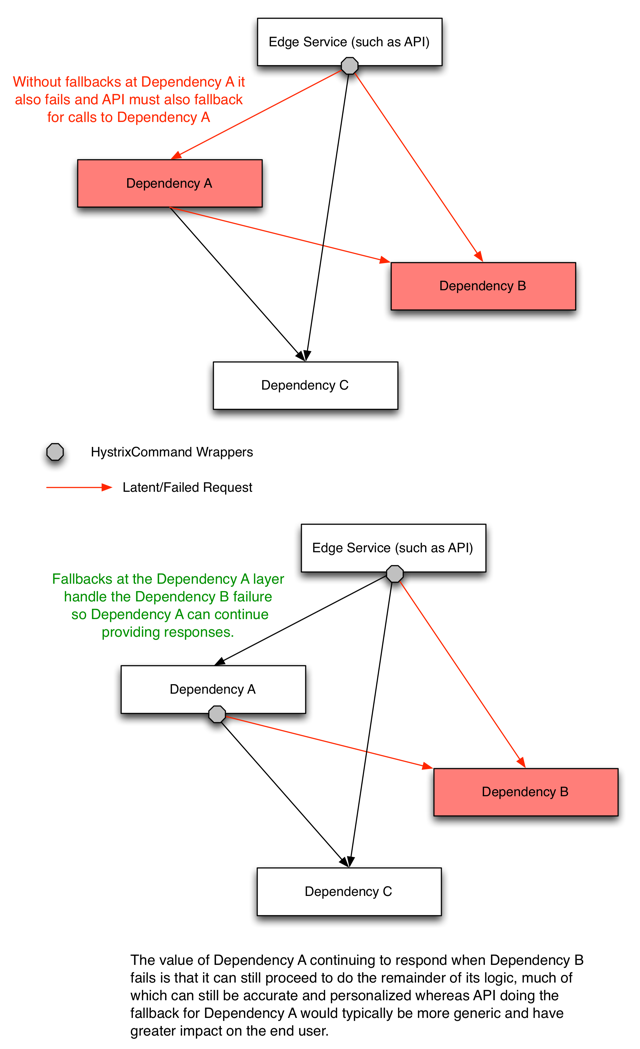
如果所有的服务都变坏了,也可能是你的系统出现了问题,而不是依赖服务。

有一下两种出现系统异常的例子
系统性能出现问题,价值过高,cup使用率过高。
内存泄漏导致gc引发延时。