一 什么是MongoDB:
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。一个面向文档的数据库系统。
二 MongoDB的作用:
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
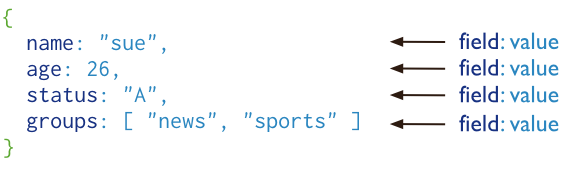
三 主要特点:
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。 MongoDB安装简单。
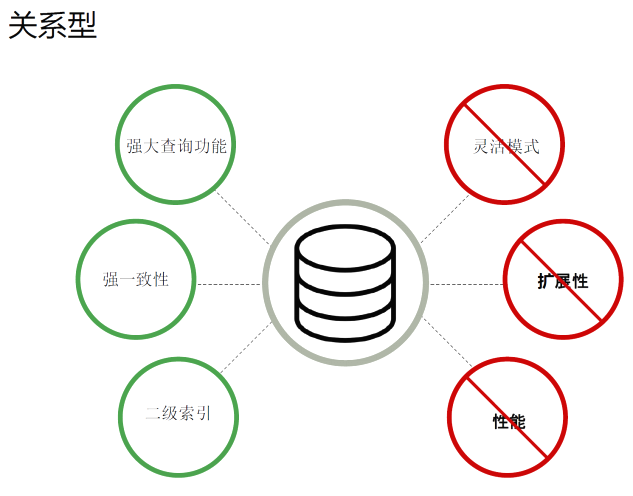
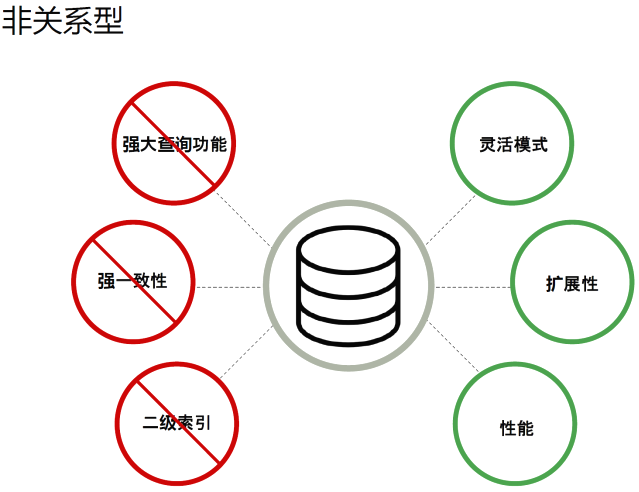
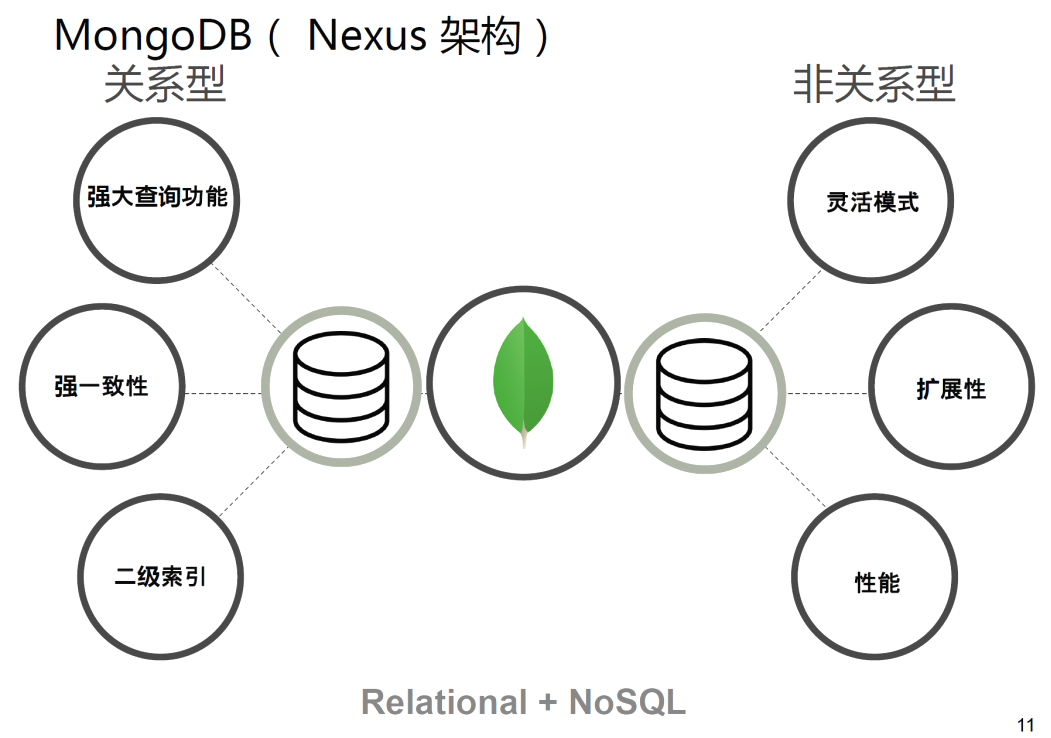
那么MongoDB同时具有关系型和非关系型数据库的优点!!!!
MongoDB与RDBMS最大的区别在于其没有固定的行列组织结构。
四 MongoDB基本的概念是文档、集合、数据库:
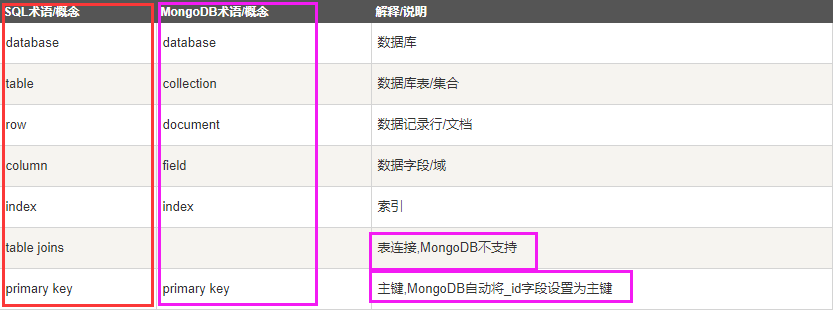
下面我们更直观的了解MongoDB:

五 MongoDB数据库:
一个mongodb中可以建立多个数据库,这一点跟我们的关系型数据库是类似的。 MongoDB的默认数据库为"db",该数据库存储在data目录中。 MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。 "show dbs" 命令可以显示所有数据的列表。
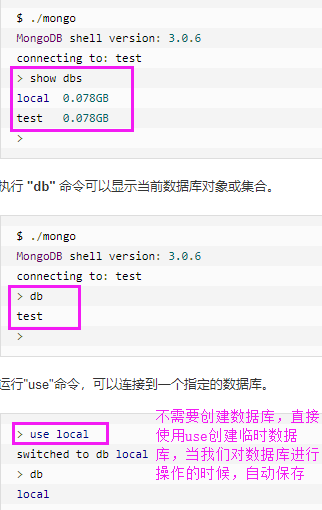

MongoDB中的文档:
文档是一组键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
这句话的意思就是在MongoDB中对于文档的键值的数据类型不做定性的要求:{"site":"www.runoob.com", "name":"MongoDB教程"}
六 MongoDB中的集合:
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
如下实例,我们可以把不同数据结构的文档插入到我们的集合中。
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
{"site":"www.runoob.com","name":"MongoDB教程","num":5}
七 MongoDB中的常用的数据类型:

那么其中比较重要的数据类型:对象id (objectID) ,字符串(String),时间戳(Timestamp),日期(Data)
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytesTimes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId() > newObject.getTimestamp() ISODate("2017-11-25T07:21:10Z")
ObjectId 转为字符串
> newObject.str
5a1919e63df83ce79df8b38f
字符串
BSON 字符串都是 UTF-8 编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
- 后32位是在某秒中操作的一个递增的
序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var mydate1 = new Date() //格林尼治时间 > mydate1 ISODate("2018-03-04T14:58:51.233Z") > typeof mydate1 object > var mydate2 = ISODate() //格林尼治时间 > mydate2 ISODate("2018-03-04T15:00:45.479Z") > typeof mydate2 object
这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。
返回一个时间类型的字符串:
> var mydate1str = mydate1.toString() > mydate1str Sun Mar 04 2018 14:58:51 GMT+0000 (UTC) > typeof mydate1str string 或者 > Date() Sun Mar 04 2018 15:02:59 GMT+0000 (UTC)
八 MongoDB数据库的操作:
1 MongoDB创建集合:MongoDB 中使用 createCollection() 方法来创建集合。
db.createCollection(name, options)
参数说明:
name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
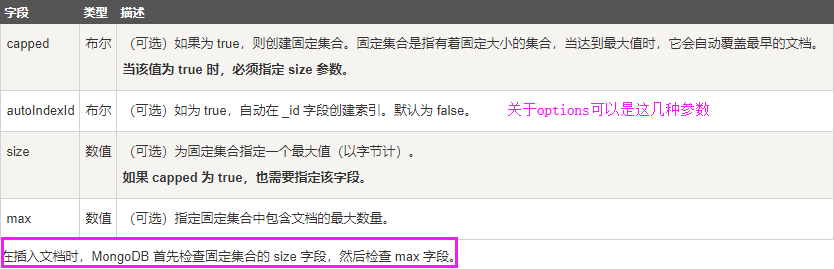
有参数和无参数创建集合
无参: > use test switched to db test > db.createCollection("runoob") { "ok" : 1 } 有参:创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个
> db.createCollection("mycol", { capped : true, autoIndexId : true, size : 6142800, max : 10000 } ) { "ok" : 1 }
可以使用show collections 查看已有的集合。
> show collections
runoob
system.indexes
2 MongoDB删除集合:
MongoDB 中使用 drop() 方法来删除集合
db.collection.drop() 格式为db.集合名.drop()
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false
3 MongoDB插入文档:
所有存储在集合中的数据都是BSON格式。
BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON。
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
如果已经存在集合col >db.col.insert({title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: 'RUNOOB教程', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }) 如果不存在集合col,会新创建一个集合col > db.col.find() { "_id" : ObjectId("56064886ade2f21f36b03134"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "RUNOB教程",
"url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 } >
4 更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
①update()方法:用于更新已经存在的文档
- db.collection.updateOne() 向指定集合更新单个文档
- db.collection.updateMany() 向指定集合更新多个文档
db.collection.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document> } )
其中参数:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
通过update()方法修改标题:
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息 > db.col.find().pretty() { "_id" : ObjectId("56064f89ade2f21f36b03136"), "title" : "MongoDB", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "RUNOOB", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
②save()方法通过传入的文档替换已有文档。
db.collection.save( <document>, { writeConcern: <document> } ) 参数说明: document : 文档数据。 writeConcern :可选,抛出异常的级别。
通过save()方法修改:
>db.col.save({ "_id" : ObjectId("56064f89ade2f21f36b03136"), "title" : "MongoDB", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "Runoob", "url" : "http://www.runoob.com", "tags" : [ "mongodb", "NoSQL" ], "likes" : 110 })
那么我们上述的数据也就变成我们save()方法更新过的。update()中的那个集合中的文档。
>db.col.find().pretty()
{
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Runoob",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 110
}
>
5 删除文档:
MongoDB remove()函数是用来移除集合中的数据。
db.collection.remove( <query>, { justOne: <boolean>, writeConcern: <document> (可选项,就是可有可无) } )
参数说明: query :(可选)删除的文档的条件。 justOne : (可选)如果设为 true 或 1,则只删除一个文档。 writeConcern :(可选)抛出异常的级别。
实例:
>db.col.remove({'title':'MongoDB 教程'})
WriteResult({ "nRemoved" : 2 }) # 删除了两条数据
>db.col.find()
新版本使用的方法:
如删除集合下全部文档:
db.inventory.deleteMany({})
删除 status 等于 A 的全部文档:
db.inventory.deleteMany({ status : "A" })
删除 status 等于 D 的一个文档:
db.inventory.deleteOne( { status: "D" } )
6 查询文档:
MongoDB 查询文档使用 find() 方法。find() 方法以非结构化的方式来显示所有文档。
查询文档语法:
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件 projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下: >db.col.find().pretty() pretty() 方法以格式化的方式来显示所有文档
九 MongoDB中的limit()与skip()
以上实例为显示查询文档中的两条记录: > db.col.find({},{"title":1,_id:0}).limit(2) { "title" : "PHP 教程" } { "title" : "Java 教程" } > 注:如果你们没有指定limit()方法中的参数则显示集合中的所有数据。 MongoDB Skip() 方法 我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。 语法 skip() 方法脚本语法格式如下: >db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) 实例 以下实例只会显示第二条文档数据 >db.col.find({},{"title":1,_id:0}).limit(1).skip(1) { "title" : "Java 教程" } > 注:skip()方法默认参数为 0
十 MongoDB 复制 :
什么是复制:
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
复制还允许您从硬件故障和服务中断中恢复数据。
- 保障数据的安全性
- 数据高可用性 (24*7)
- 灾难恢复
- 无需停机维护(如备份,重建索引,压缩)
- 分布式读取数据
复制的原理:
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
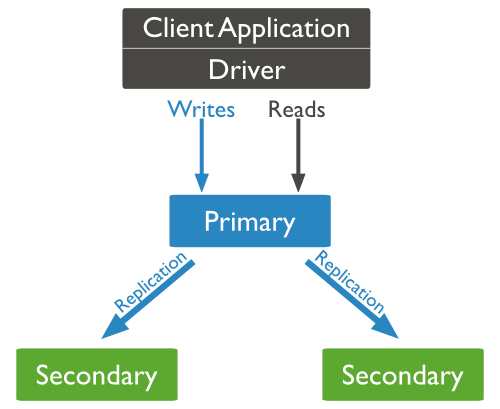
副本集特征:
N 个节点的集群
任何节点可作为主节点
所有写入操作都在主节点上
自动故障转移
自动恢复
十一 MongoDB分片:
①什么是分片:
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
②为什么分片:
复制所有的写入操作到主节点
延迟的敏感数据会在主节点查询
单个副本集限制在12个节点
当请求量巨大时会出现内存不足。
本地磁盘不足
垂直扩展价格昂贵
③ 分片集群结构图:
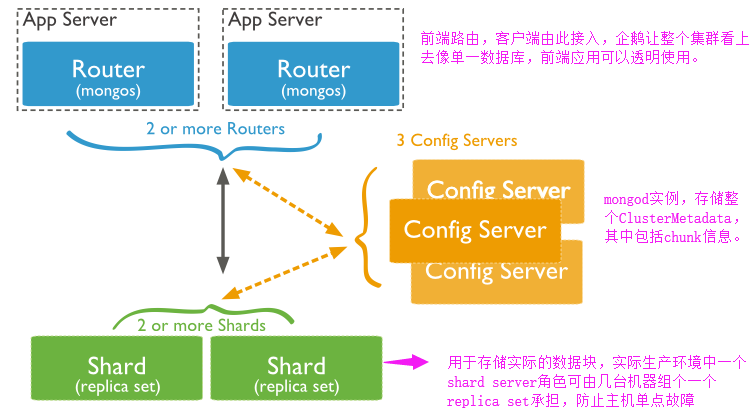
④ 实例
分片实例
分片结构端口分布如下: Shard Server 1:27020 Shard Server 2:27021 Shard Server 3:27022 Shard Server 4:27023 Config Server :27100 Route Process:40000 步骤一:启动Shard Server [root@100 /]# mkdir -p /www/mongoDB/shard/s0 [root@100 /]# mkdir -p /www/mongoDB/shard/s1 [root@100 /]# mkdir -p /www/mongoDB/shard/s2 [root@100 /]# mkdir -p /www/mongoDB/shard/s3 [root@100 /]# mkdir -p /www/mongoDB/shard/log [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork .... [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 --dbpath=/www/mongoDB/shard/s3 --logpath=/www/mongoDB/shard/log/s3.log --logappend --fork 步骤二: 启动Config Server [root@100 /]# mkdir -p /www/mongoDB/shard/config [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork 注意:这里我们完全可以像启动普通mongodb服务一样启动,不需要添加—shardsvr和configsvr参数。因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以。 步骤三: 启动Route Process /usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500 mongos启动参数中,chunkSize这一项是用来指定chunk的大小的,单位是MB,默认大小为200MB. 步骤四: 配置Sharding 接下来,我们使用MongoDB Shell登录到mongos,添加Shard节点 [root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000 MongoDB shell version: 2.0.7 connecting to: 127.0.0.1:40000/admin mongos> db.runCommand({ addshard:"localhost:27020" }) { "shardAdded" : "shard0000", "ok" : 1 } ...... mongos> db.runCommand({ addshard:"localhost:27029" }) { "shardAdded" : "shard0009", "ok" : 1 } mongos> db.runCommand({ enablesharding:"test" }) #设置分片存储的数据库 { "ok" : 1 } mongos> db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}}) { "collectionsharded" : "test.log", "ok" : 1 } 步骤五: 程序代码内无需太大更改,直接按照连接普通的mongo数据库那样,将数据库连接接入接口40000
未完待续:
http://www.runoob.com/mongodb/mongodb-replication.html