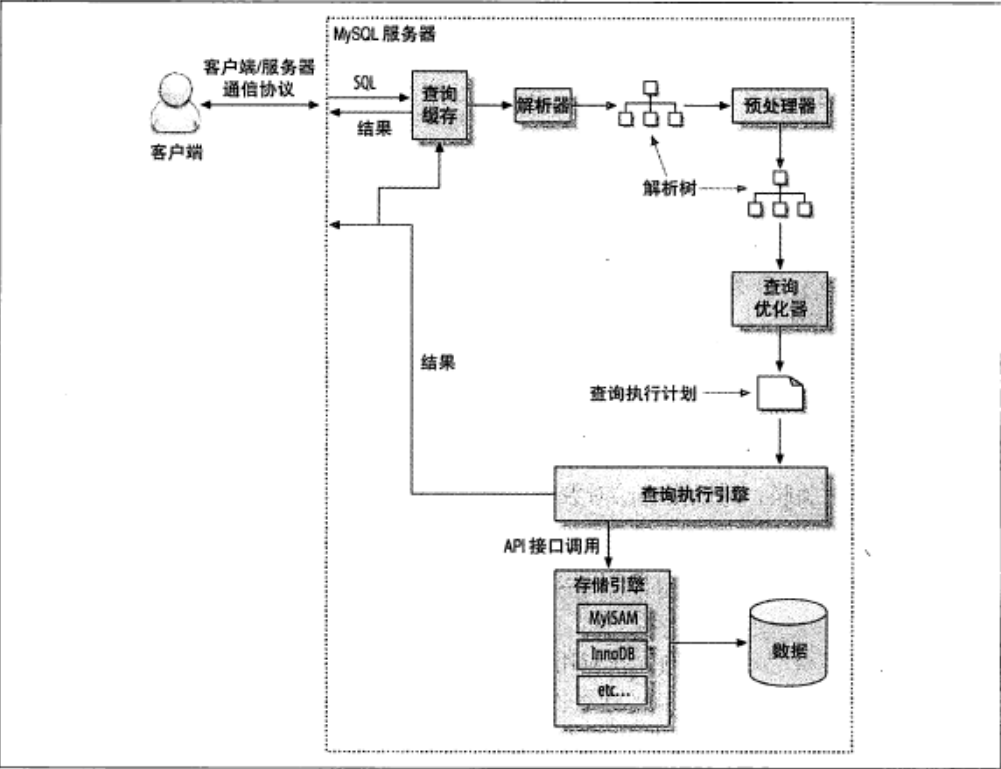
前端有个链接在监听 ==》查询权限==》 mysql服务器获得这个请求;获得这个sql 语句 ==》后是执行 ;
有权限 看你这条sql 是否查询过;如果查询过 会将结果直接返回;查询缓存要求 上一次查询的sql 和你这次
查询sql一致;数据库里的数据没有任何变化的情况下;有变化缓存就失效了
解析器:对sql 语法 进行解析 == 》解析树
这个解析树是没有得到优化;在预处理中进行优化 ==》(比如函数 有计算结果 ) 处理完==》新的解析树
新的解析树 是我们后面正在需要查询用到的一个解析树
mysql 里面最关键的 查询优化器
多种执行方案里面做选择 根据mysql自身的统计信息 选择性能最高的
我们后面所说的怎么优化 mysql 就是要让优化器按照我们的意愿去执行我们所写的sql语句;帮我们选择最优
的执行方案;
查询执行计划==》最终查询的原则 也可以说是执行步骤
mysql 存储引擎 ==》InnoDB MyISAM Memory(内存存储引擎) ....
查询引擎 show engines;
==》磁盘文件
影响查询性能==》硬盘机械运动 IO
==》查询的快和慢 看执行计划 产生的IO越少 执行性能就越高
查询处理的每个阶段如下:

sql优化原则:
1,优先优化高并发低消耗的SQL;
1,1小时请求1W次,1次10个IO;
2,1小时请求10次,1次1W个IO;
从IO消耗,优化难度,CPU消耗进行比较;
2,定位性能瓶颈;
1,SQL运行较慢有两个影响原因,IO和CPU,明确性能瓶颈所在;
2,明确优化目标;XX毫秒 优化XXXX毫秒
二、Explain和Profile
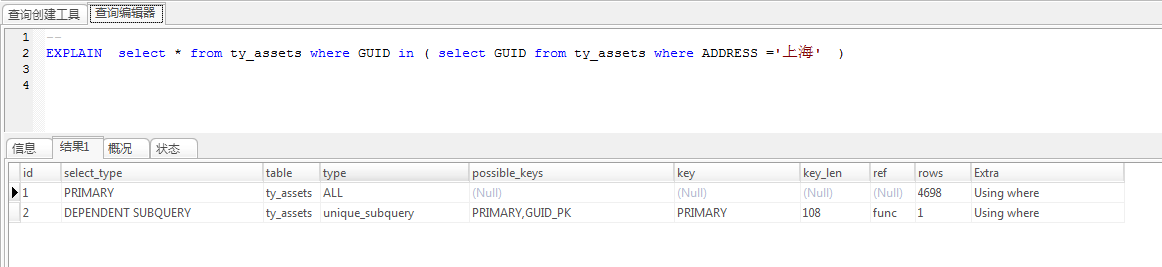
1,任何SQL的优化,都从Explain语句开始;Explain语句能够得到数据库执行该SQL选择的执行计划;
2,首先明确需要的执行计划,再使用Explain检查;
3,使用profile明确SQL的问题和优化的结果;(mysql 5.1之后 提供了一个很方便诊断Query执行工具,能够准确的获取一条查询执行过程中的CPU,IO等情况)
Explain:


Profile:
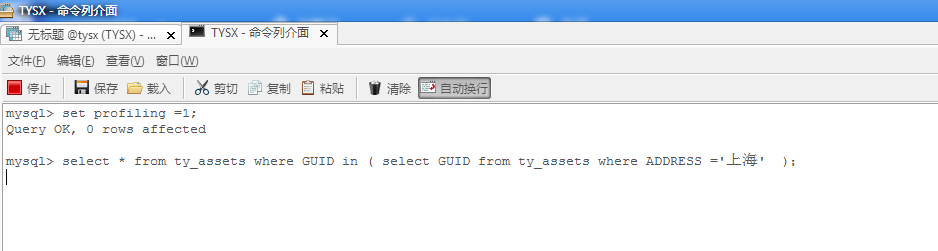
sql 执行的每一步细节操作:
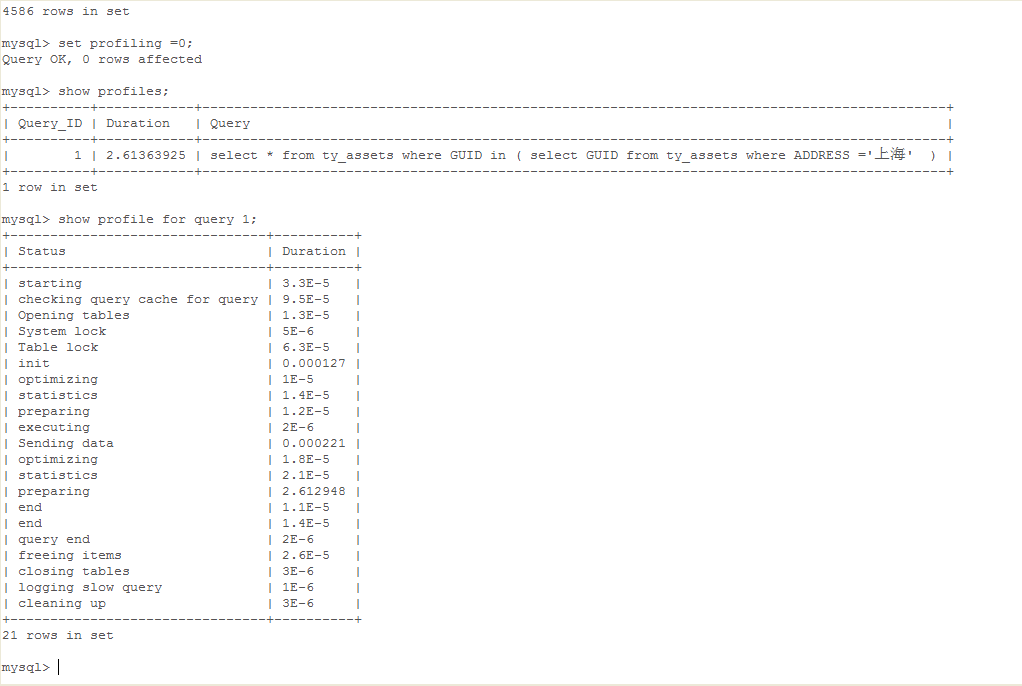
查询CPU IO占用情况:

set profiling =1;
select * from ty_assets where GUID in ( select GUID from ty_assets where ADDRESS ='上海' );
set profiling =0;
show profiles;
show profile for query 1;
show profile cpu,block io for query 1;
三、永远用小结果集驱动大的结果集
JOIN工作原理:
A JOIN B:通过A表的结果集作为循环基础,一条一条的通过结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果;
JOIN优化原则;
1,尽可能减少Join 语句中的Nested Loop 的循环总次数,用小结果集驱动大结果集;(小的for查大的)
2,优先优化Nested Loop 的内层循环;(小的结果集去循环大的结果集优先优化内存循环)
3,保证Join 语句中被驱动表上Join 条件字段已经被索引;(得出:减少外部外层循环;提高内层查询性能)
4,扩大join buffer的大小;(缓存)
四、在索引中完成排序
如果排序的列是索引列,大大降低排序成本
排序原则:先查询结果 再排序
五、使用最小Columns
1,减少网络传输数据量;
2,MYSQL排序原理,是把所有的column数据全部取出,在排序缓存区排序,再返回结果;如果column数据量大,排序区容量不够的时候,就会使用先column排序,再取数据,再返回的多次请求方式;
六、使用最有效的过滤条件
1,过多的WHERE条件不一定能够提高访问性能;(where条件最多就能用一个索引;其他查询条件都是附加查询条件)
2,一定要让where条件使用自己预期的执行计划;
七、避免复杂的JOIN和子查询
1,复杂的JOIN和子查询,需要锁定过多的资源,MYSQL在大量并发情况下处理锁定性能下降较快;
2,不要过多依赖SQL的功能,把复杂的SQL拆分为简单的SQL;(内存里做复杂逻辑拼装)
3,MySQL子查询性能较低,应尽量避免使用;