单机系统:
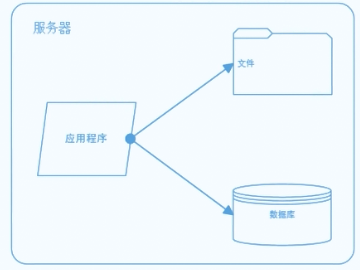
在一些公司中,一个普通的系统,极有可能是负载在一台服务器上的。在这种系统架构中,所有的计算,存储,都保存在了一个服务器上面的。但是因为单机承载能力(硬件资源) 的原因,我们的系统所处理的请求时有上限的。
那随着时间用户数的增多,我们需要系统能够承载更多的请求。
一般会有俩种方案:
1.增加单机硬件资源
2.集群(水平扩展)
单机资源增加是有上限的,大部分情况下不会采用。使用集群的方式,是大部分公司所采用的手段。
集群一般和分布式是相辅相成的,一般来说,集群 “包含“分布式。
分布式系统就是将原来一台服务器上做的事,分散到多台服务器协做处理,这个就可以认为是分布式的实现。它的好处也是很明显的,就是很轻松的提升承载能力,系统各个服务进行了解耦,但是划分粒度是很粗放的。
需要声明的是,使用分布式的第一要务就是不要使用分布式.因为使用分布式会带来其他的许许多多的问题,比如故障排除、数据一致性等问题...
下来要说的是,一个系统性能提升最快的方式就是缓存.。因为其成本低,见效快。
适合做缓存的数据一般是访问频次较多的数据,或者不易变化的数据。一般同一个数据只要访问超过3次,那就有缓存的必要。
集群:
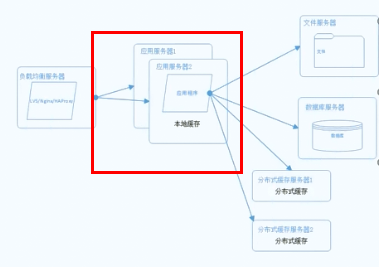
如上图所示,集群可以认为是将一台服务器复制1份或者N份,每一台服务器上面做的是都是一样的,使用集群只是为了分担网站流量,同时,使用集群,我们就应该同时使用SLB(负载均衡)进行请求分发。
DNS负载均衡----可以将请求就近转发,但是不够灵活(服务器宕机等意外情况不能处理)
硬件负载均衡-----相关负载均衡技术包含在硬件中,对外黑盒。
软件级负载均衡:
LVS: Linux下的----是4层协议的负载均衡(可修改IP+Port,更有效率,但是功能性差)
HAProxy 7层协议----可以拿到Http报文。(用得不多)
Nginx 7层协议----许多策略---->平均轮询,加权轮询,IP哈希(回话粘滞 不均衡)---fair,url-hash
压力测试工具:loadrunner