一、传统运维方式和自动化运维的区别
二、CMDB的介绍
三、CMDB的四种方式
四、项目的目录架构介绍以及配置文件的升级编写
五、比较low的项目架构书写
六、可插拔式收集资产
七、对收集的服务器信息进行清洗
八、整个项目的总结
九、收集资产遇到的唯一标识的大坑
十、开启线程池并发采集
十一、后台目录结构设计
十二、API请求认证
十三、后台数据表结构设计
十四、后台数据表生成
十五、资产清洗入库
十六、硬盘数据入库
十七、AES加密数据
十八、将数据展示前端
十九、bootstraptable行内进行编辑
二十、layui的使用
二十一、使用echarts,highcharts进行画图
Python的几个方向:
1、Python自动化运维
2、爬虫(数据分析)
3、web开发
4、人工智能(AI)
一、传统运维方式和自动化运维的区别
传统运维:
项目上线的流程:
第一步:产品经理进行前期调研(需求分析)
第二步:和开发进行评审
第三步:开发进行开发
第四步:测试人员进行测试
第五步:交给业务运维人员进行上线 (重点讨论这个)--怎么上线-->直接将代码给业务运维人员(代码打一个包用qq传过来),让业务运维人员把代码放到服务器上(拿到代码解压,然后放到服务器上)。服务器上需要配一下域名(就跟百度一样www.baidu.com)才能够对外服务。
缺点:
增加运维的成本
针对这种传统的方式有什么解决优化方案?
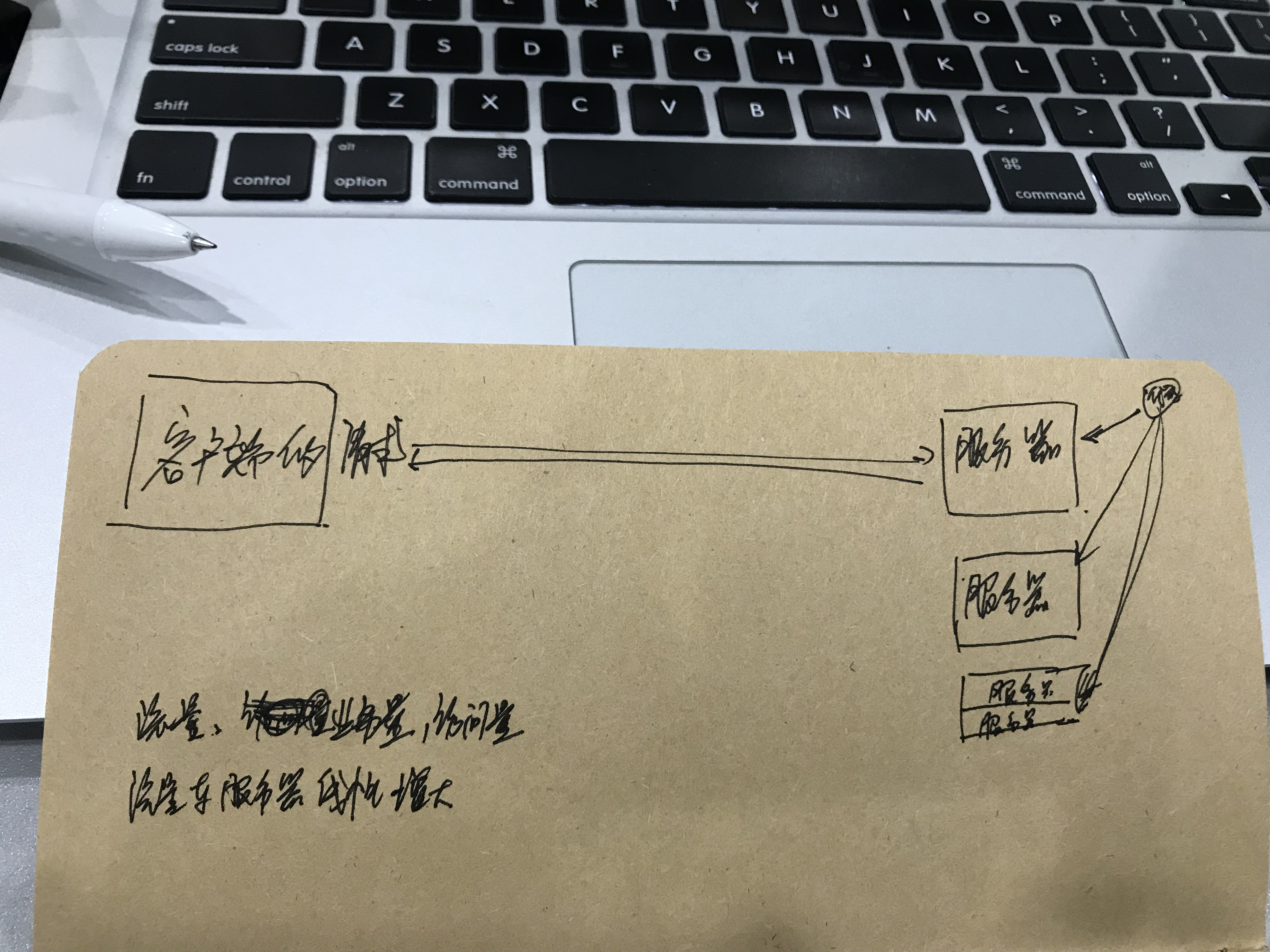
改进一:专门搞一个自动分发程序代码的系统。
a.这个系统的基础是得有服务器的信息(ip、hostname、等)
b.能不能报警自动化


SMTP
一千台服务器上放微博的项目,尾部项目出问题了会触发服务器上一个报警(每台服务器中都有),发邮件,发短信或者打电话到运维人员手机上。
c.装机系统
传统的装机和布线:idc运维-->用大量的人力物力来进行装机。
自动化运维?--->把服务器放到机架上,插一根网线。把服务器ip还有hostname信息告诉一个专门装机的系统。
我发送一个命令,centos就能够装好。
d.收集服务器元信息
1.Excel
缺点:人为干预太严重,统计的时候也会有问题
2.搞一个系统---->这就叫CMDB
作用:自动的帮我们收集服务器的信息,并且自动的记录我们的变更信息。
二、CMDB的介绍
自动的帮我们收集服务器的信息,并且自动的记录我们的变更信息。让所有的操作都变得自动化。
三、CMDB的四种方式
大体流程:
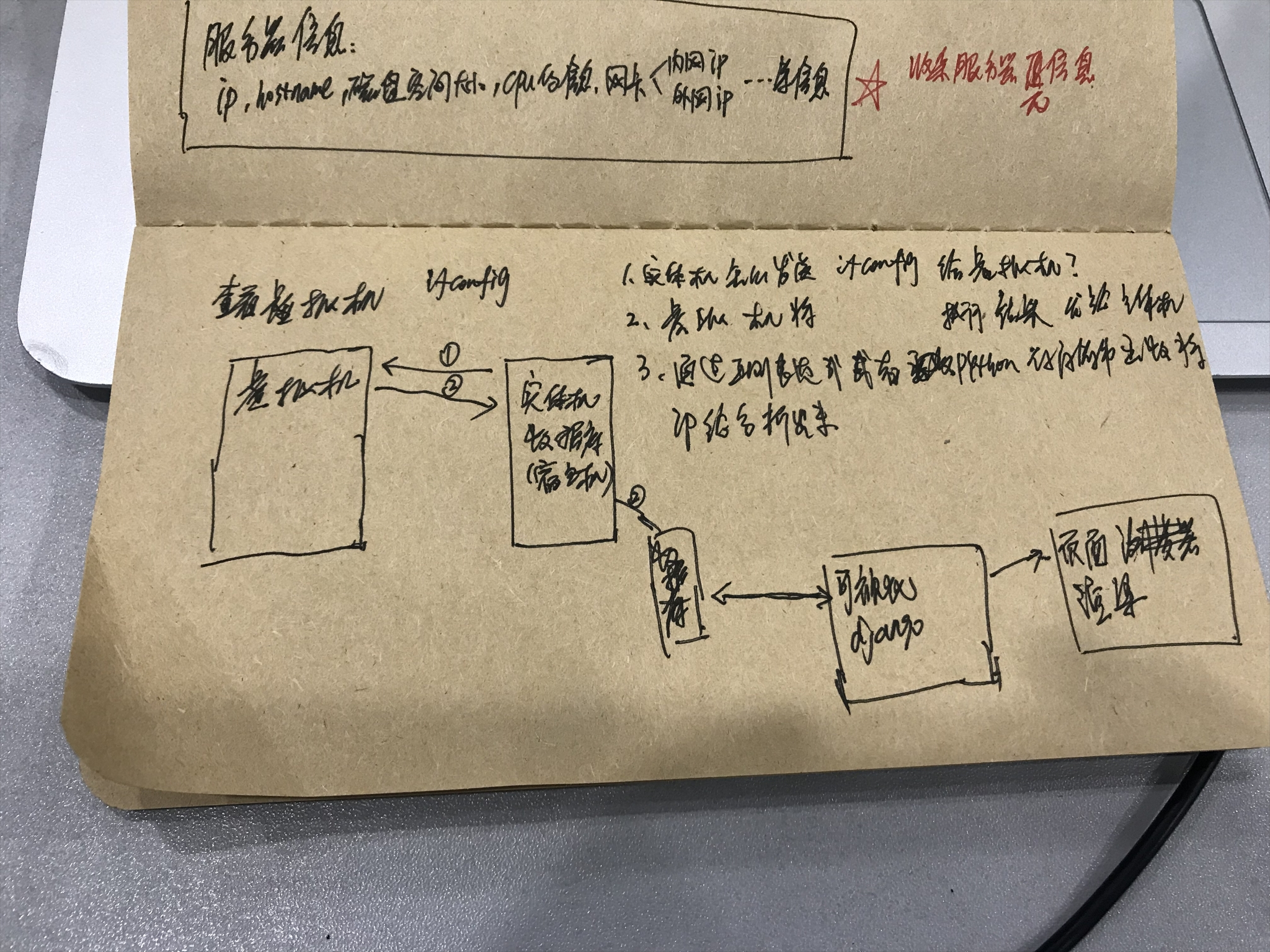
开始收集服务器的元数据:怎么收集虚拟机服务器所有的信息?---->怎么汇报给实体机,数据库里?
获取ip地址:
获取主机名:
获取硬盘信息:
获取内存信息:

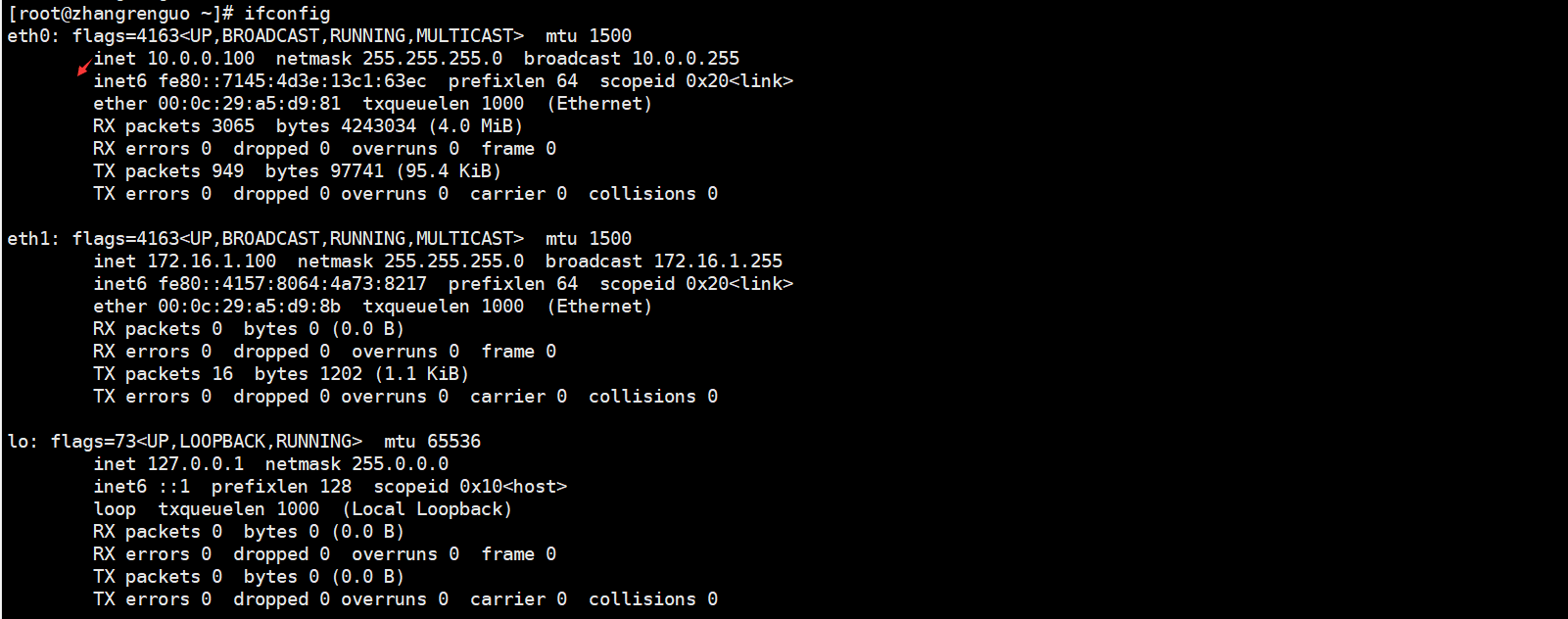
1.实体机发命令虚拟机执行ifconfig
2.虚拟机执行命令得到执行的结果可以通过socket发送给实体机
3.需要通过正则或者Python的一些字符串函数将ip信息给分析出来
在实际开发中,收集服务器的信息总共有4中方案:
第一个方案:agent方式 (代理中介的意思)
第一步:在每台服务器上写Python脚本(脚本内容),且python代码执行的结果还在每台服务器上。
import subprocess # res = subprocess.getoutput('ipconfig') res = subprocess.getoutput('ifconfig') print(res) # 用正则,字符串分割函数...拿到想要的结果
第二步:定时(crontab)的执行收集代码
linux命令crontab,可以指定在哪一时刻执行某一个脚本。
第三步:将执行的结果返回给那台专门收集信息的服务器。用requests模块,post请求
第四步:专门收集的服务器收集到所有的服务器信息后放到DB(数据库)服务器里。
第五步:搞一个给管理人员或者想要用CMDB系统的人看的Django页面
注:我们把每一台服务器叫每一个agent。开启一个agent代表的意思是,在我们每一台服务器上,我们布一个agent脚本(就是我们写的test.py脚本)。agent脚本目前三行代码,但将来实际上会非常非常的大。
缺点:每台服务器都要安装agent
优点:速度快
应用场景:适用服务器多的时候,大公司
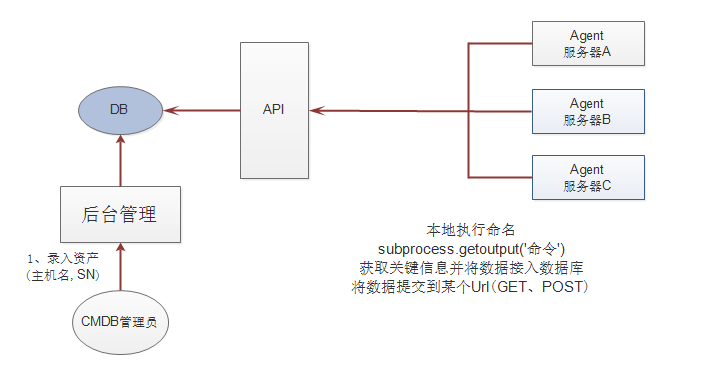
agent方式:
agent脚本
API
web界面
第二种方案:ssh连接 另外目前市面上除了使用paramiko模块本身外,还有fabric,ansible等,它们内部都是基于paramiko模块实现的
# # ssh类 用于连接远程服务器并执行基本命令 # import paramiko # # # # 创建SSH对象 # ssh = paramiko.SSHClient() # # 允许连接不在know_hosts文件中的主机 # ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # # 连接服务器 # ssh.connect(hostname='zhangrenguo', port=22, username='root', password='1') # # # 执行命令 # stdin, stdout, stderr = ssh.exec_command('ifconfig') # # 获取命令结果 # result = stdout.read() # print(result.decode('utf-8')) # # 关闭连接 # ssh.close()
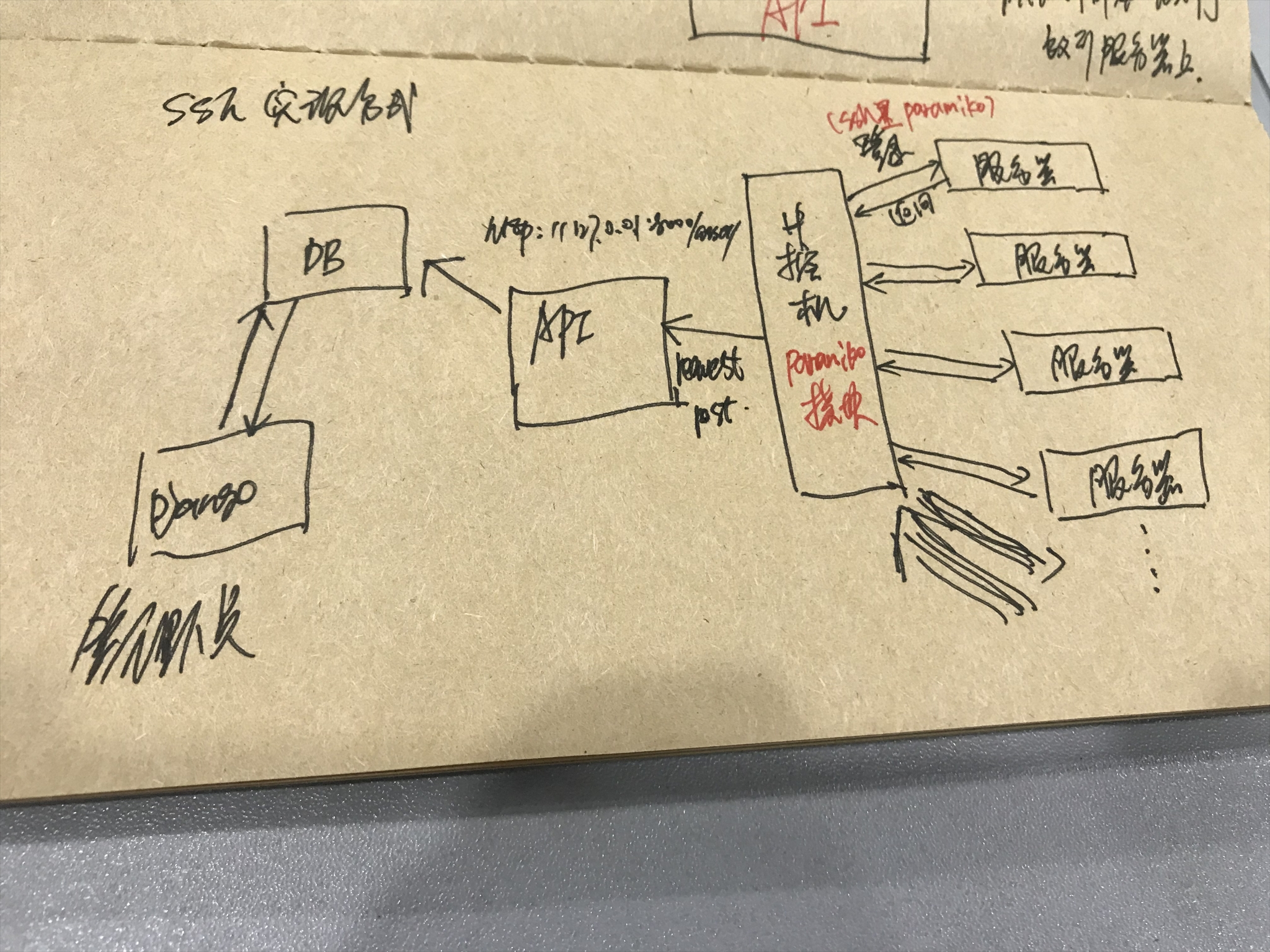
缺点:依赖于网络,速度慢
优点:不用部署agent
适用于服务器少的
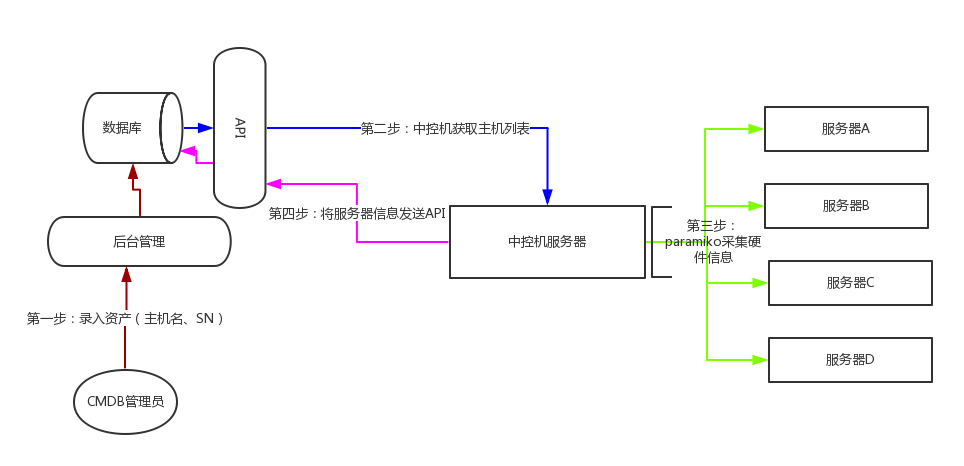
ssh类(parmiko)
parmiko(获取主机名)
API
Web界面展示
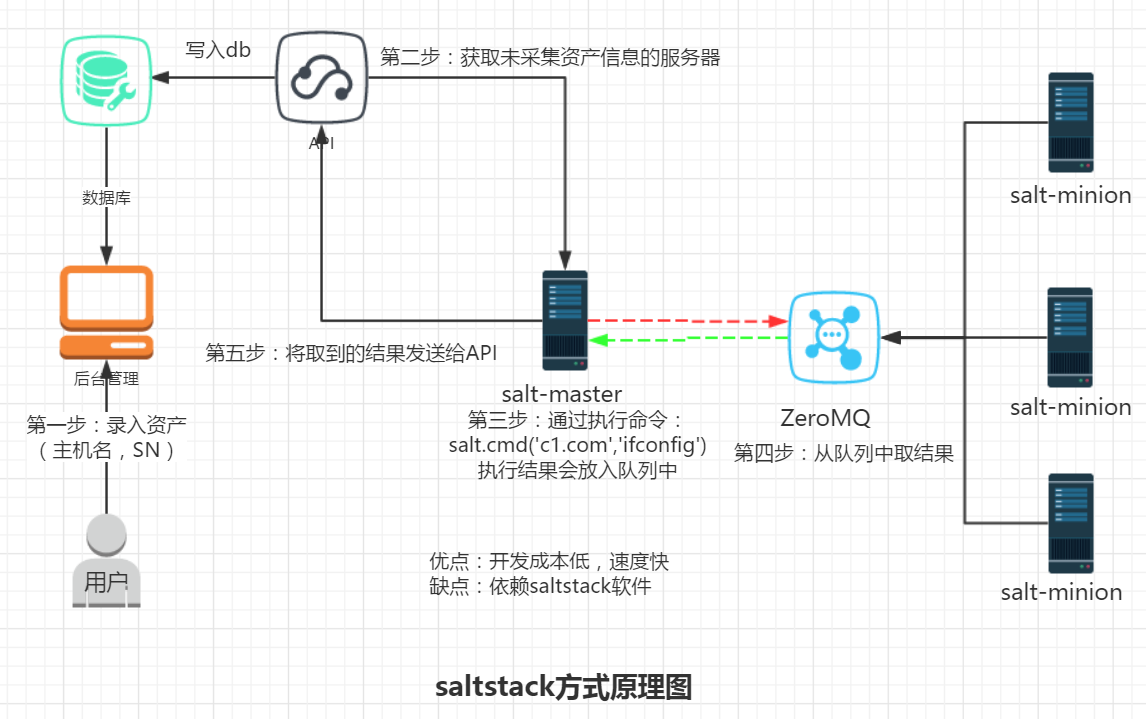
第三种方案:saltstack的工作原理--->
安装:
#master端: """ 1. 安装salt-master yum install salt-master 2. 修改配置文件:/etc/salt/master interface: 10.0.0.7 # 表示Master的IP 3. 启动 service salt-master start """ #slave端: """ 1. 安装salt-minion yum install salt-minion 2. 修改配置文件 /etc/salt/minion master: 10.0.0.7 # master的地址 或 master: - 10.211.55.4 - 10.211.55.5 random_master: True id: c2.salt.com # 客户端在salt-master中显示的唯一ID 3. 启动 service salt-minion start """"""
授权
""" salt-key -L # 查看已授权和未授权的slave salt-key -a salve_id # 接受指定id的salve salt-key -r salve_id # 拒绝指定id的salve salt-key -d salve_id # 删除指定id的salve """
执行命令
#在master服务器上对salve进行远程操作 salt 'c2.salt.com' cmd.run 'ifconfig' #基于API的方式 import salt.client local = salt.client.LocalClient() result = local.cmd('c2.salt.com', 'cmd.run', ['ifconfig'])
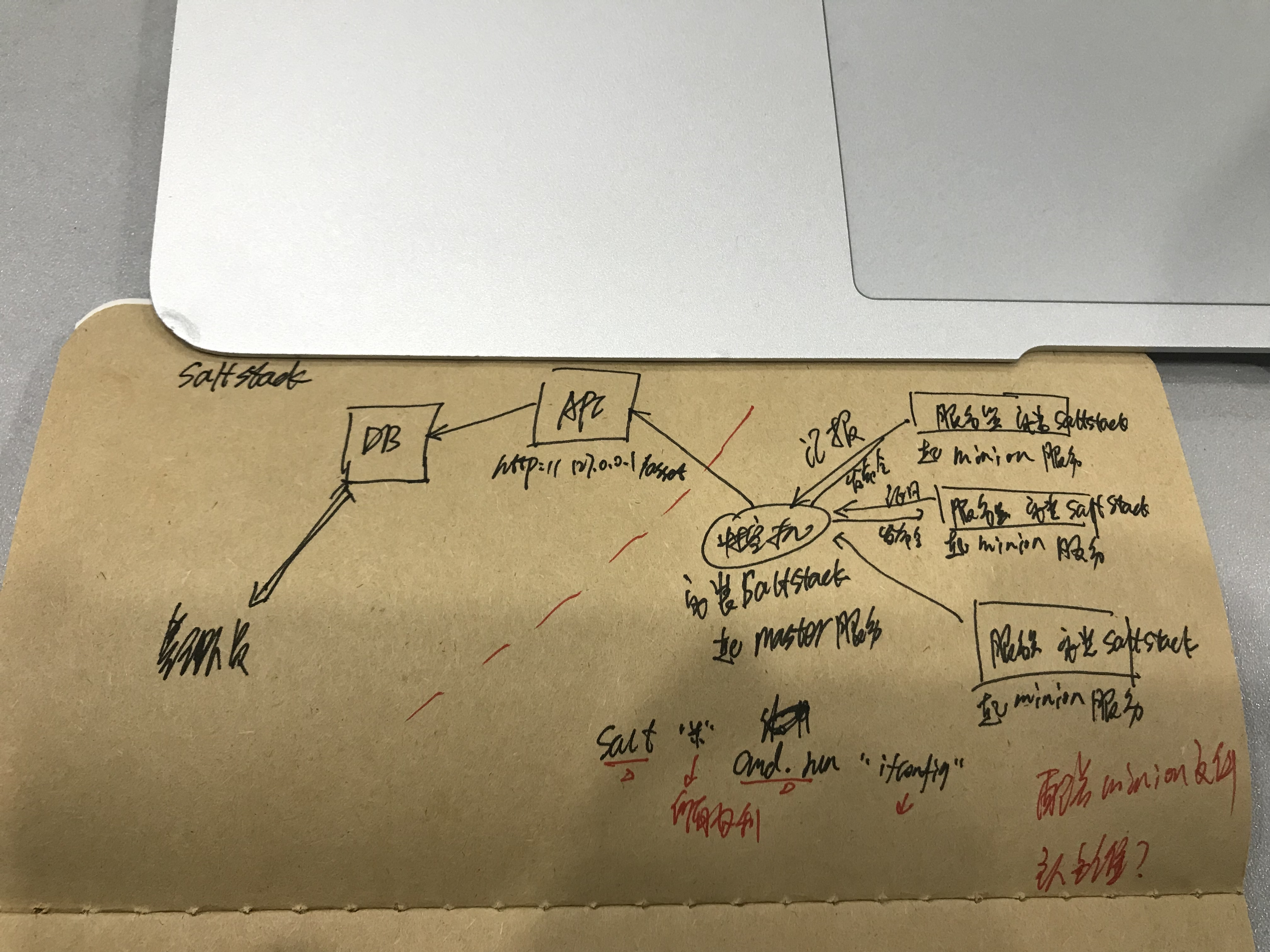
缺点:所有服务器需要安装saltstack软件
优点:直接用现有的软件,速度快,开发成本低
适用于公司一直使用saltstack,业内最流行的方案
saltstack:
saltstack软件
API
web界面展示
第四种方案:puppet 慢慢被淘汰了
不做了解。
四种方式大致的步骤:
1.收集服务器信息
2.数据提交给api
3.文本页面展示
可视化工具:
https://echarts.baidu.com
https://www.highcharts.com.cn/demo/highcharts
在线画图工具:
www.processon.com
www.draw.io
为什么要使用CMDB?
因为现在统计资产使用的是Excel表格,但业务业务越来越多。导致变更资产的时候,Excel表格越来越乱。为了让所有的资产收集全部自动化,所以我们做了CMDB。
目标:
三种方式我们都要实现兼容
只需要改配置文件里面的一个配置,我们就能够自如的切换
四、项目的目录架构介绍以及配置文件的升级编写
项目名叫autoclient
core文件夹
conf目录放settings一些自定义配置文件settings.py
bin目录放入口启动可执行的文件start.py
src放一些核心业务的一些逻辑agent.py
db 放数据相关文件
log 放一些日志相关文件
lib 放一些自己写的公共的类公共的模块common.py
test.py测试
配置文件的编写:
目标:写一个类似于Django的配置方法(有自定义的配置文件,还要有项目默认的配置文件)--->无非是集成自定义配置文件和项目默认的配置文件里面的这些配置。通过面向对象高级里面知识!
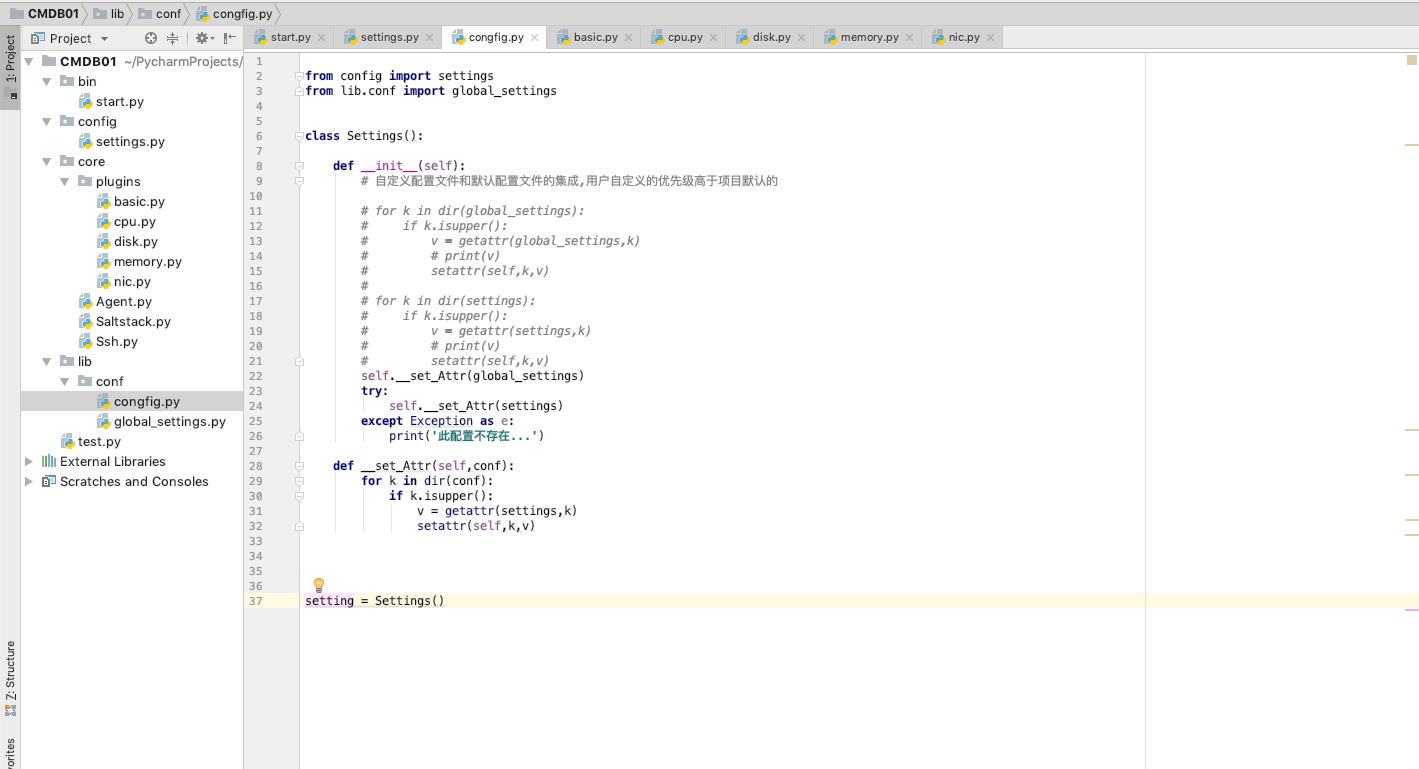
代码重复
可以写一个公共的方法
可以写一个父类方法
代码高内聚--->某一个方法就干一件事,剩下的其他的不管。
代码低解耦--->启动脚本是脚本,不参与业务逻辑。
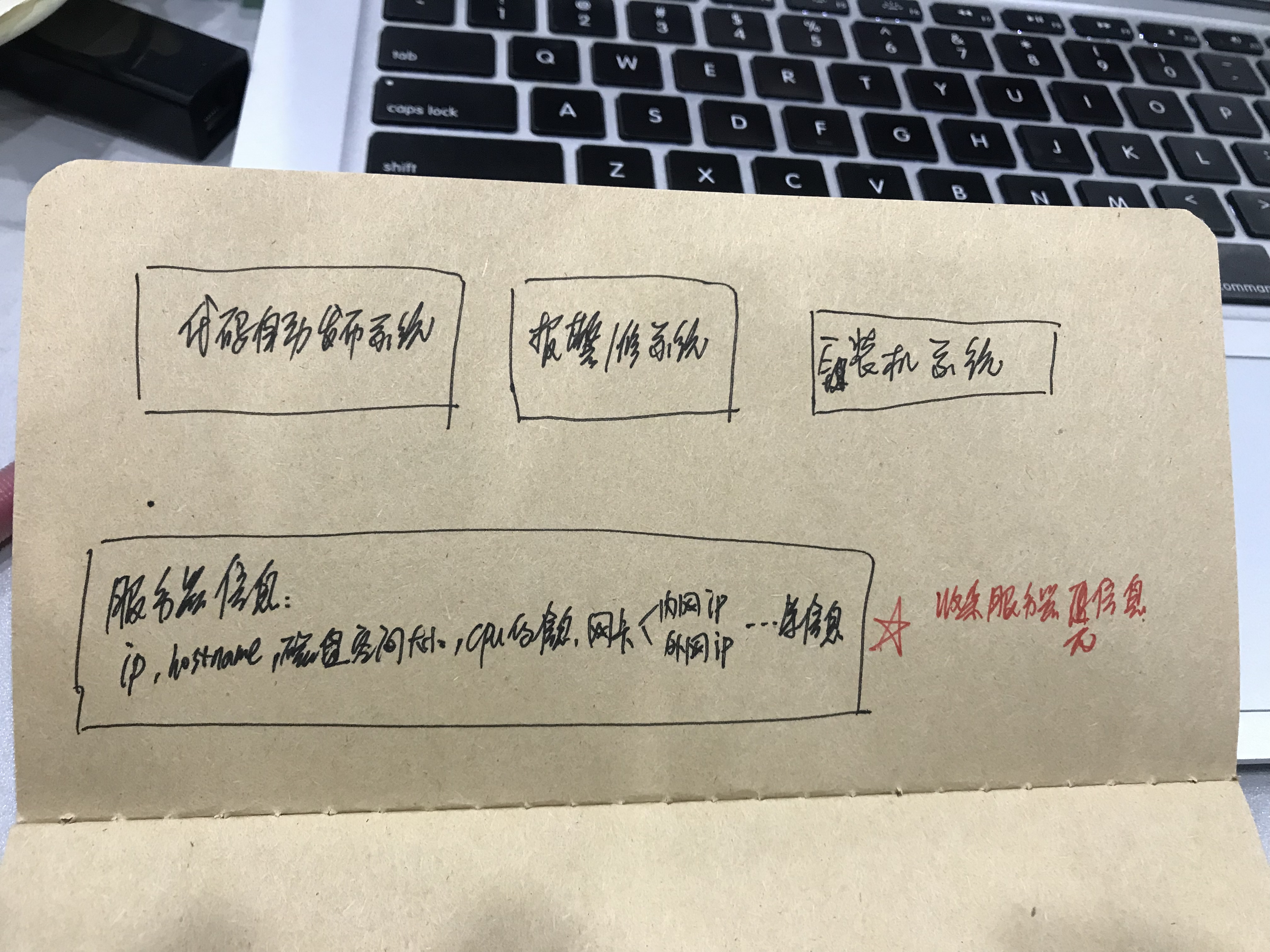
收集的信息:
主板信息:hostname、Mac地址
cpu信息:型号,几个核
dick(磁盘信息):磁盘大小、几块磁盘
memory(内存信息):
nic(网卡信息):ip地址、
可插拔式的收集上述信息-----什么是可插拔式的?-->在配置文件里的配置,想用的时候去掉注释,不想用的时候加上注释。和业务逻辑没关系。
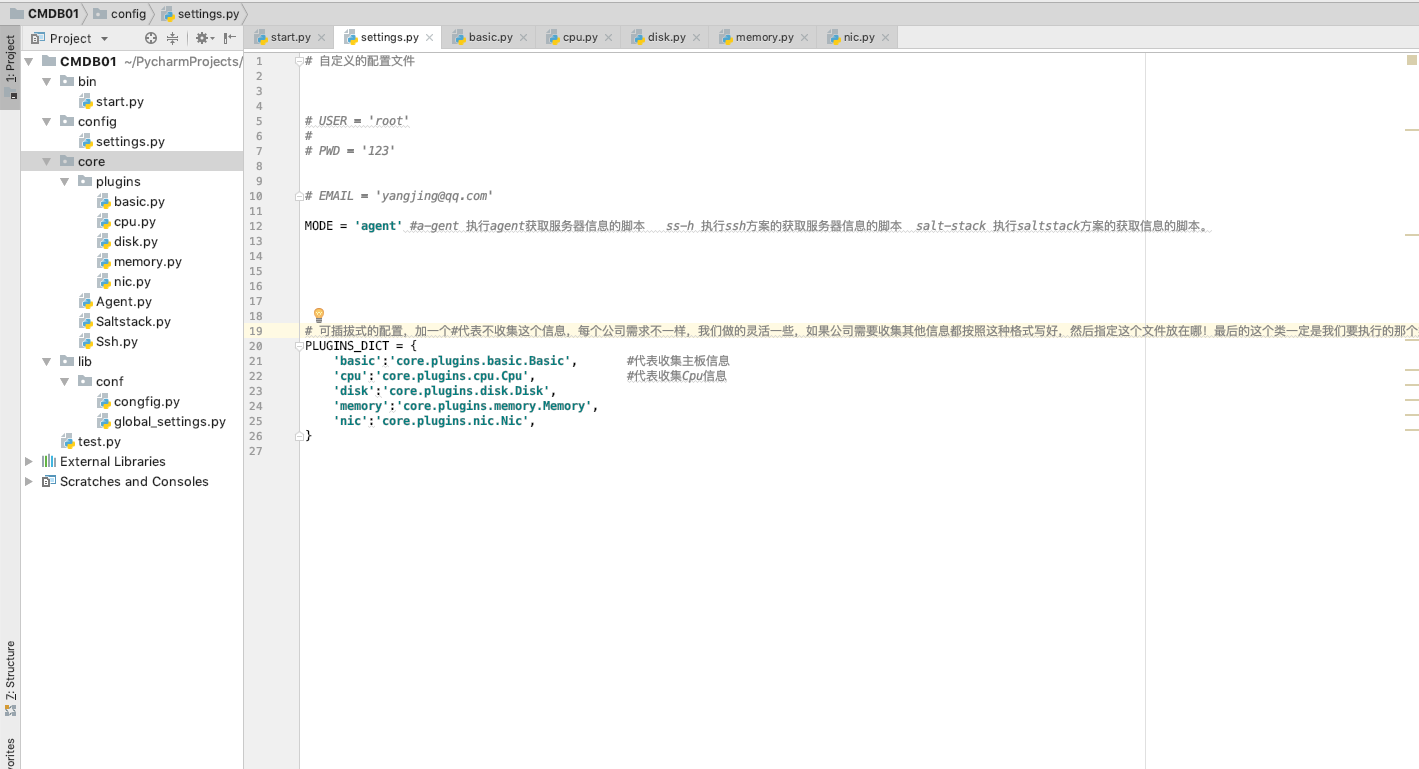
接下来升级可插件的__init__文件。 写代码收集
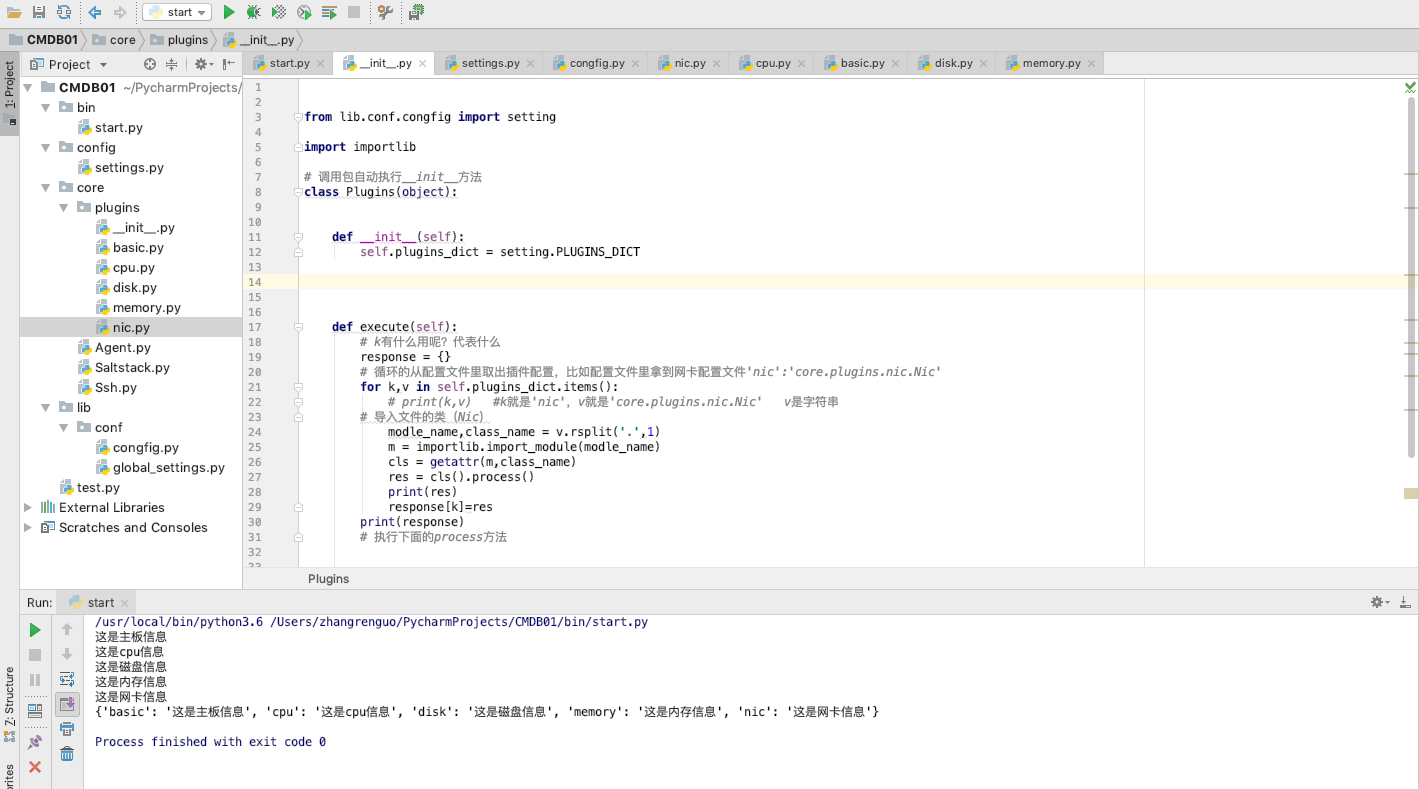
插件的第一种解决方案:
a、写一个公共的类
让其他的所有的类继承Base这个基类
b、
信息已经收集好了---发送给API通过requests模块-->
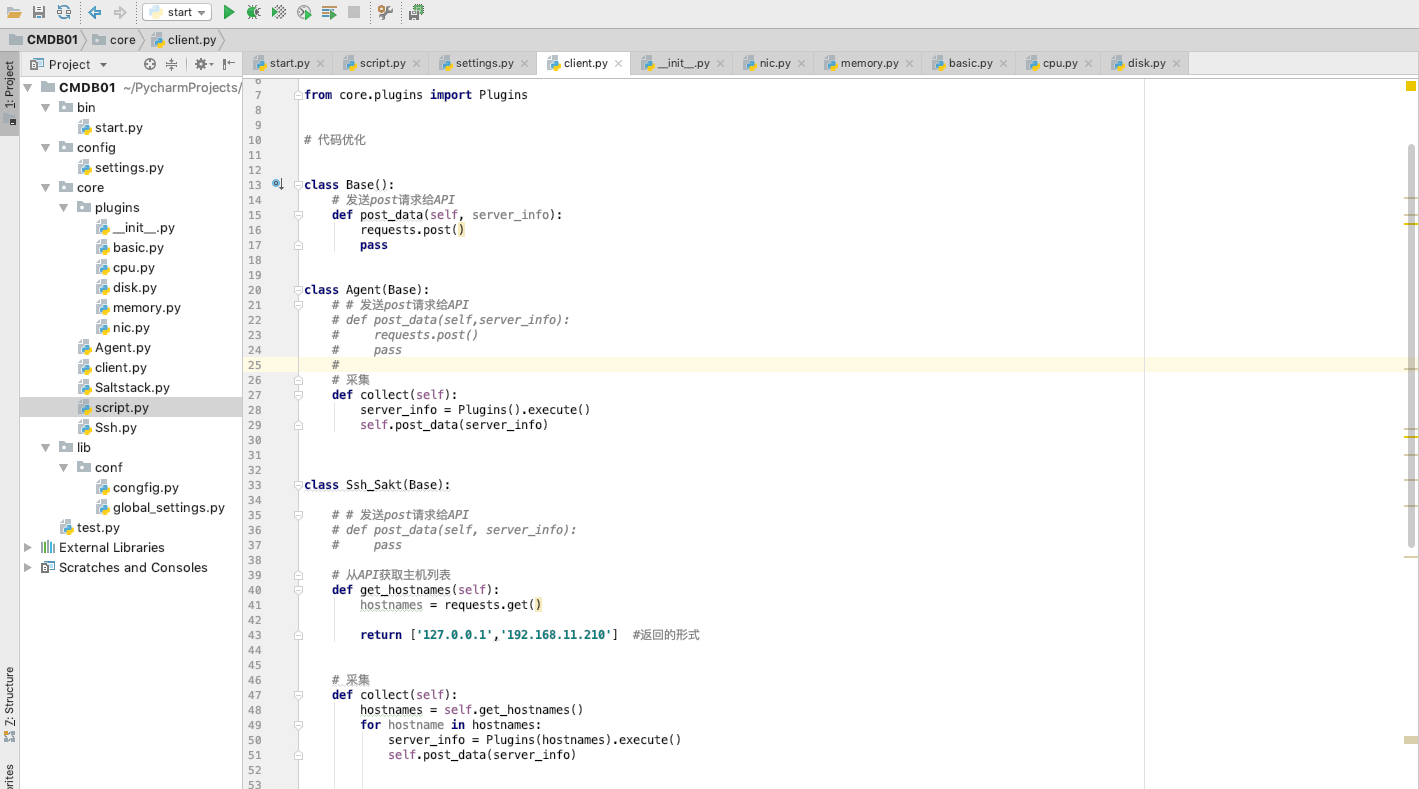
收集的信息:Linux上的命令
主板信息:hostname、Mac地址
cpu信息:型号,几个核 cat /proc/cpuinfo
dick(磁盘信息):磁盘大小、几块磁盘
memory(内存信息):
nic(网卡信息):ip地址、