数据分析:
是不把隐藏在看似杂乱无章的数据域背后的信息提炼出来,总结出所研究对象内在规律
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
创建ndarray
使用np.array()创建
- 一维数据创建
-
import numpy as np np.array([1,2,3,4,5]) 结果:rray([1, 2, 3, 4, 5])
- 二维数组创建
np.array([[1,2,3],['a','b',1.1]]) #二维数据就是讲一个大列表嵌套两个小列表 结果: array([['1', '2', '3'], ['a', 'b', '1.1']], dtype='<U11')
注意:
- numpy默认ndarray的所有元素的类型是相同的
- 如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
2. 使用np的routines函数创建
#np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) 等差数列 np.linspace(1,100,num=50) array([ 1. , 3.02040816, 5.04081633, 7.06122449, 9.08163265, 11.10204082, 13.12244898, 15.14285714, 17.16326531, 19.18367347, 21.20408163, 23.2244898 , 25.24489796, 27.26530612, 29.28571429, 31.30612245, 33.32653061, 35.34693878, 37.36734694, 39.3877551 , 41.40816327, 43.42857143, 45.44897959, 47.46938776, 49.48979592, 51.51020408, 53.53061224, 55.55102041, 57.57142857, 59.59183673, 61.6122449 , 63.63265306, 65.65306122, 67.67346939, 69.69387755, 71.71428571, 73.73469388, 75.75510204, 77.7755102 , 79.79591837, 81.81632653, 83.83673469, 85.85714286, 87.87755102, 89.89795918, 91.91836735, 93.93877551, 95.95918367, 97.97959184, 100. ])
间隔为2的等差数列
#np.arange([start, ]stop, [step, ]dtype=None)
np.arange(1,100,2) array([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99])
生成随机数
#np.random.randint(low, high=None, size=None, dtype='l') np.random.seed(10)#这里random.seed 是固定随机数获取的值 arr = np.random.randint(0,100,size=(5,6))
生成3 * 3 的二维随机数
#np.random.random(size=None) #生成0到1的随机数,左闭右开 np.random.seed(3) np.random.random(size=(3,3)) array([[0.765334 , 0.68742254, 0.12771576], [0.34878082, 0.46292111, 0.75355298], [0.08188152, 0.53189213, 0.17514265]])
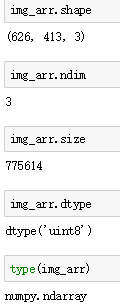
二、ndarray的属性
4个必记参数:
ndim:维度
shape:形状(各维度的长度)
size:总长度
dtype:元素类型
三、ndarray的基本操作
1. 索引一维与列表完全一致
多维时同理
arr
array([[ 9, 15, 64, 28, 89, 93], [29, 8, 73, 0, 40, 36], [16, 11, 54, 88, 62, 33], [72, 78, 49, 51, 54, 77], [69, 13, 25, 13, 92, 86]])
arr[[1,2]] #进行索引当是二维数组的时候,arr[0] 表示获取第一列, arr[[2,4]]表示获取3,5 行 结果: array([[29, 8, 73, 0, 40, 36], [16, 11, 54, 88, 62, 33]]) 可以根据索引修改数据 根据索引修改数据
2. 切片
一维与列表完全一致
多维时同理
arr
array([[ 9, 15, 64, 28, 89, 93],
[29, 8, 73, 0, 40, 36],
[16, 11, 54, 88, 62, 33],
[72, 78, 49, 51, 54, 77],
[69, 13, 25, 13, 92, 86]])
#获取二维数组前两行 arr[0:2] array([[ 9, 15, 64, 28, 89, 93], [29, 8, 73, 0, 40, 36]]) #获取二维数组前两列 arr[:,0:2] array([[ 9, 15], [29, 8], [16, 11], [72, 78], [69, 13]]) #当存在都好后, ,后面的是列的前几个索引
#获取二维数组前两行和前两列数据 arr[0:2,0:2] array([[ 9, 15], [29, 8]])
#将数组的行倒序 arr[::-1] #array([[69, 13, 25, 13, 92, 86], [72, 78, 49, 51, 54, 77], [16, 11, 54, 88, 62, 33], [29, 8, 73, 0, 40, 36], [ 9, 15, 64, 28, 89, 93]]) #列倒序 arr[:,::-1] #array([[93, 89, 28, 64, 15, 9], [36, 40, 0, 73, 8, 29], [33, 62, 88, 54, 11, 16], [77, 54, 51, 49, 78, 72], [86, 92, 13, 25, 13, 69]])
3. 变形
使用arr.reshape()函数,注意参数是一个tuple!
基本使用 1.将一维数组变形成多维数组 arr_1.reshape((-1,15)) array([[ 9, 15, 64, 28, 89, 93, 29, 8, 73, 0, 40, 36, 16, 11, 54], [88, 62, 33, 72, 78, 49, 51, 54, 77, 69, 13, 25, 13, 92, 86]]) 2.将多维数组变形成一维数组 arr_1 = arr.reshape((30,))
4. 级联
就是将表与表拼接
np.concatenate()
1.一维,二维,多维数组的级联,实际操作中级联多为二维数组
arr
array([[ 9, 15, 64, 28, 89, 93],
[29, 8, 73, 0, 40, 36],
[16, 11, 54, 88, 62, 33],
[72, 78, 49, 51, 54, 77],
[69, 13, 25, 13, 92, 86]])
np.concatenate((arr,arr),axis=1) array([[ 9, 15, 64, 28, 89, 93, 9, 15, 64, 28, 89, 93], [29, 8, 73, 0, 40, 36, 29, 8, 73, 0, 40, 36], [16, 11, 54, 88, 62, 33, 16, 11, 54, 88, 62, 33], [72, 78, 49, 51, 54, 77, 72, 78, 49, 51, 54, 77], arr1 = np.random.randint(0,100,size=(5,5)) arr1 [69, 13, 25, 13, 92, 86, 69, 13, 25, 13, 92, 86]]) array([[30, 30, 89, 12, 65], [31, 57, 36, 27, 18], [93, 77, 22, 23, 94], [11, 28, 74, 88, 9], [15, 18, 80, 71, 88]]) np.concatenate((arr,arr1),axis=1) array([[ 9, 15, 64, 28, 89, 93, 30, 30, 89, 12, 65], [29, 8, 73, 0, 40, 36, 31, 57, 36, 27, 18], [16, 11, 54, 88, 62, 33, 93, 77, 22, 23, 94], [72, 78, 49, 51, 54, 77, 11, 28, 74, 88, 9], [69, 13, 25, 13, 92, 86, 15, 18, 80, 71, 88]])
ndarray的聚合操作
求和np.sum
求和np.sum arr.sum(axis=0) array([195, 125, 265, 180, 337, 325])
最大最小值:np.max/ np.min
3.平均值:np.mean()
ndarray的排序
1. 快速排序
np.sort()与ndarray.sort()都可以,但有区别:
np.sort()不改变输入
ndarray.sort()本地处理,不占用空间,但改变输入
np.sort(arr,axis=0) array([[ 9, 8, 25, 0, 40, 33], [16, 11, 49, 13, 54, 36], [29, 13, 54, 28, 62, 77], [69, 15, 64, 51, 89, 86], [72, 78, 73, 88, 92, 93]]) arr.sort(axis=0) arr array([[ 9, 8, 25, 0, 40, 33], [16, 11, 49, 13, 54, 36], [29, 13, 54, 28, 62, 77], [69, 15, 64, 51, 89, 86], [72, 78, 73, 88, 92, 93]])