作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
作业要求:
1.列表,元组,字典,集合分别如何增删改查及遍历。
- 列表
增
cm = ['Manry','kimi','tony','张三'] cm.append('在末尾增加一个字符') cm cm = ['Manry','kimi','tony','张三'] cm.insert(1,'在指定位置增加一个字符') cm
运行结果:
删
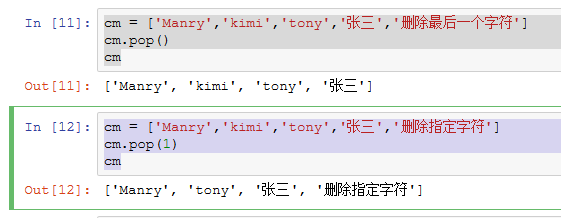
cm = ['Manry','kimi','tony','张三','删除最后一个字符'] cm.pop() cm cm = ['Manry','kimi','tony','张三','删除指定字符'] cm.pop(1) cm
运行结果:
改
cm = ['Manry','kimi','tony','张三'] cm[1]=('修改指定位置字符') cm
运行结果:
查
cm = ['Manry','kimi','tony','张三','34','Tom','Jary'] print(cm[1])#查找下标为1的字符 print(cm[-1])#查找最后一位字符 print(cm[1:2])#查找下标为1和2之间的字符 print(cm[3:])#查找下标为3及之后的字符 print(cm[:2])#查找下标为2之前的字符 print(cm[:6:2])#查找下标为6之前每隔2位的字符 print(cm[:])#查找所有字符
运行结果:
遍历
cm = ['Manry','kimi','tony','张三','34','Tom','Jary'] print(len(cm)) for cm1 in cm: print(cm1)
运行结果: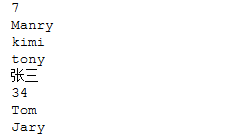
- 元组
tup1=('张三','Tom','zqq','1996') tup2=('许嵩','vae') print(tup1+tup2)
运行结果:

元组不可以修改或单个删除元素。
- 字典
增
dict={'张三':'1998','Tom':'2000','zqq':'1996'}
dict['vae']='1986'
dict
运行结果:

删
dict={'张三':'1998','Tom':'2000','zqq':'1996'}
del dict['张三']
dict
运行结果:

改
dict={'张三':'1998','Tom':'2000','zqq':'1996'}
dict['张三']='2019'
dict
运行结果:

查
dict={'张三':'1998','Tom':'2000','zqq':'1996'}
print('张三的值为:',dict['张三'])
print('字典元素为:',dict)
运行结果:

- 集合
增
aa={'张三','许嵩','vae','zqq','Tom','Jary'}
aa.add('lisa')
aa
运行结果:

删
aa={'张三','许嵩','vae','zqq','Tom','Jary','remove删除集合元素'}
aa.remove('remove删除集合元素')
aa
aa={'张三','许嵩','vae','zqq','Tom','Jary','pop删除集合元素'}
aa.pop()
aa
运行结果:

2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
列表是以方括号形式表示,元组是以圆括号表示,字典以花括号表示,集合则是以[()]的形式表示。
- 有序无序
列表,元组,字典是有顺序的,而集合是没顺序的。
- 可变不可变
元组和列表在结构上没有什么区别,唯一的差异在于元组是只读的,不能修改。元组用“()”表示。元组一旦定义其长度和内容都是固定的。一旦创建元组,则这个元组就不能被修改,即不能对元组进行更新、增加、删除操作。若想创建包含一个元素的元组,则必须在该元素后面加逗号“,”,否则创建的不是一个元组,而是一个字符串。
- 重复不可重复
列表,元组,字典可重复,而集合是不可重复的。
- 存储与查找方式
列表和元组通过值存储,集合通过键(不可重复)存储,字典通过键值对(不可重复)存储。
3.词频统计
import string import pandas as pd '''定义获取文件并处理函数''' def gettext(): txt = open("God is a girl.txt").read().lower() for c in string.punctuation: txt = txt.replace(c, " ") return txt '''将文本分成单词''' txtDC=gettext().split( ) '''过滤无意词''' ex = {'a','an','and','was','as','it','his','he','we','the','you','in','on','but','with','not','of','for','are','is'} txtSet=set(txtDC)-ex '''单词统计''' txtDic = {} for word in txtSet: txtDic[word] = txtDC.count(word) '''排序''' wordList = list(txtDic.items()) wordList.sort(key=lambda x:x[1],reverse=True) '''输出top20''' for i in range(20): print(wordList[i]) '''保存为csv文件''' pd.DataFrame(data=wordList).to_csv('My story.csv',encoding='utf-8')
God is a girl.txt

输出TOP(20)

可视化词云
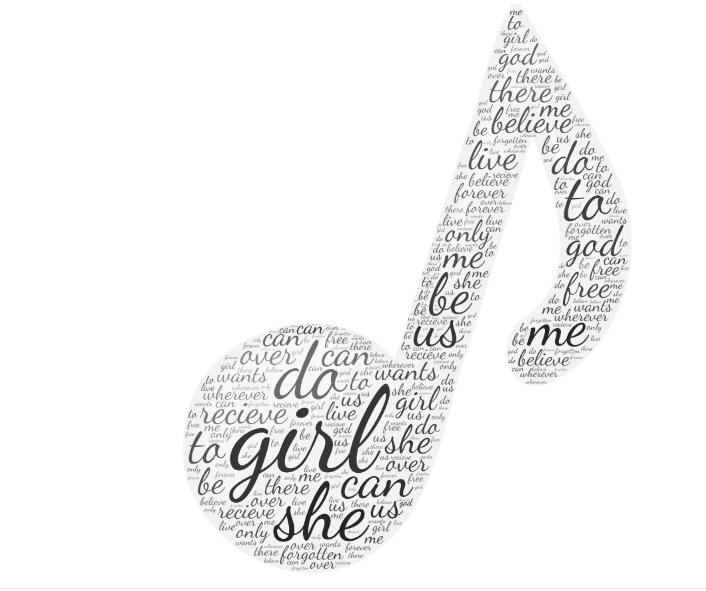
import pandas as pd pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云: https://wordart.com/create
作业博客要求:
- 文字作业要求言简意骇,用自己的话说明清楚。
- 编码作业要求放上代码,加好注释,并附上运行结果截图。