Map集合java.util.Map
方法:
- (1), void clear() : 删除该Map对象中所有的key-value对
- (2), boolean containsKey(Object key) : 查询Map中是否包含指定的key,如果包含返回true
- (3), boolean containsValue(Object value): 查询Map中是否包含一个或者多个value,如果包含,返回true,否则返回false.
- (4), Set entrySet(): 返回Map中包含key-value对所组成的Set集合,每个元素都是Map.Entry对象
- (5), Object get(Object key): 返回指定的key所对应的value,如果此Map中不包含该key,则返回null
- (6), boolean isEmpty(): 查询该Map是否为空
- (7), Set keySet(): 返回该Map中所有key组成的Set集合
- (8), Object put(Object key, Object value): 添加一个key-value对,如果Map中已经存在了对应的key了,那么会覆盖原来的。
- (9), void putAll(Map m):将制定的Map中的key-value复制到本Map中
- (10), Object remove(Object key) : 删除指定key锁对应的key-value对,返回被删除key所关联的value,如果key不存在,那么返回null。
- (11), boolean remove(Object key, Object value): 这个是java8新增的方法,删除制定key,value所对应的key-value对。如果从该Map中成功的删除该key-value对,该方法返回true,否则返回false
- (12), int size(): 返回该Map李对应的key-value对的个数
- (13), Collection values() : 返回该Map李所有value组成的Collection
Java8新增方法:
- Object compute(Object key, BitFunction remappingFunction): 该方法使用remappingFunction根据key-value计算一个新的value。只要value不为null,就是用新value覆盖原value,如果原value不为null,但是新value为null,则删除原来的key-value对。如果原value和新value都是null,那么该方法不改变任何的key-value对,直接返回null。
- Object computeIfAbsent(Object key, Function mappingFunction): 如果传给该方法的key参数在Map中对应的value为null, 则使用mappingFunction根据key计算一个新的结果,如果计算结果不为null,则用计算结果覆盖原有的value。如果原Map不包含该key,那么该方法可能会添加一组key-value对。
- void forEach(BiConsumer action): 该方法是Java8为Map新增的一个遍历Key-value对的方法,通过该方法可以更加简洁的遍历Map的key-value对。
- Object getOrDefault(Object key, V defaultValue) : 获取指定的key对应的value。如果key不存在,那么直接返回defaultValue
- Object merge(Object key, Object value, BiFunction remappingFunction): 该方法会先根据key参数获取该map中对象的value。如果获取的value为null,则直接用传入的value覆盖有缘的value(在这种情况下,可能要新添加一组key-value对);如果获取的value不为null,则使用remappingFunction函数根据原value,新value计算一个新的结果,并用得到的结果去覆盖原有的value。
- Object putIfAbsent(Object key, Object value): 该方法会自动检测指定key对应value是否为null,如果该key对应的value为null,该方法将会用新的value替代原来的value。
- Object replace(Object key, Object oldValue, Object newValue): 将Map中指定的key-value对的原value替换成新的value,如果Map中找到指定的key-value对,执行替换并返回true,否则返回false。
- void replaceAll(BiFunction function) : 该方法使用BiFunction对原key-value对执行计算,并且将计算结果作为该key-value对的value值。
void forEach(BiConsumer action): 测试
persons.forEach((key,value)-> System.out.println(key + "=" + value));
void replaceAll(BiFunction function) 测试
import java.util.HashMap; import java.util.Map; import java.util.Set; import java.util.function.BiFunction; public class MapExample { public static void main(String[] args) { Map persons = new HashMap(); //put方法就是添加key-value对 persons.put("张三",23); persons.put("李四",28); persons.put("王五",23); System.out.println(persons);//{李四=28, 张三=23, 王五=23} //对原有元素做自定义处理运算 persons.replaceAll((key,value) -> (int)value -1); System.out.println(persons); //{李四=27, 张三=22, 王五=22} } }
Java8改进的HashMap和HashTable实现类:
- (1),HashTable是一个线程安全的Map实现,但是HashMap是线程不安全的实现,所以它比HashTable的性能高了一些。
- (2),HashTable不允许使用null作为key和value,如果试图把null的值放进HashTable中,将会引发NullPointerException异常。但是HashMap可以使用null作为key或者value。
HashMap和HashTable存储位置问题:
HashMap和HashTable的containsValue(Object object )方法判断相等其实就是equals:
IdentityHashMap
LinkedHashMap
- 性能要比HashMap低一些
- 元素维持着插入时的顺序
- 但是迭代LinkedHashMap的时候,效率会更快。
public class LinkHahsMapExample { public static void main(String[] args) { Map linkHashMap = new LinkedHashMap(); linkHashMap.put("张三",2); linkHashMap.put("李四",3); linkHashMap.put("老刘",4); linkHashMap.forEach((k,v) -> System.out.println(k + "=====>" + v)); } }
Properties类读取配置文件:
- 用来读取键值对的配置文件。
- String getProperty(String key): 获取Properties中指定属性名对应的属性值。
- Object setProperty(String key, String value): 设置属性值
- void load(InputStream inStream) : 从属性文件中加载key-value对。
- void store(OutputStream out, String comments): 将properties中的key-value对输出到指定的文件中。
import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.util.Properties; /** * @ClassName PropertiesExample * @projectName: object1 * @author: Zhangmingda * @description: XXX * date: 2021/4/10. */ public class PropertiesExample { public static void main(String[] args) throws IOException { Properties properties = new Properties(); properties.load(new FileReader("D:\JavaStudy2\集合\src\configTest.ini")); properties.forEach((k,v) -> System.out.println(k + "=" + v)); /**如上输出 * password=xxx * username=zmd */ properties.setProperty("qjj","hehe"); //新增或者设置老的key对应值 properties.store(new FileWriter("D:\JavaStudy2\集合\src\configTest2.ini"),"测试"); //保存到文件中 } }
SortedMap接口和TreeMap实现类(排序的Map):
- Map.Entry firstEntry(): 返回该Map中key最小的key-value对,如果Map为空会返回null
- Object firstKey(): 返回该Map中最小的key值,如果该Map为空,返回null
- Map.Entry lastEntry(): 返回该Map中最大的key对应的key-value对,如果该Map为空或不存在key-value时,则都返回null。
- Object lastKey(): 返回该Map中最大的Key值,如果该Map为空或者不存在这样的key,则都返回null。
- Map.Entry higherEntity(Object key): 返回该Map中位于key后一位的key-value对(即大于指定key的最小key所对应的key-value对)。如果该Map为空,则返回null.
- Object higherKey(Object key): 返回该Map中位于key后一位的key-value对的key,如果Map为空返回null
- Map.Entry lowerEntry(Object key): 返回该Map中位于key前一位的key-value对,如果Map为空返回null.
- Object lowerKey(Object key): 返回该Map中位于key前一位的key的值。如果该Map为空,或者不存在这样的key,都返回null。
- 省略若干........。
import java.util.Map; import java.util.TreeMap; public class TreeMapTest { private static class A implements Comparable { int count; public A(int count) { this.count = count; } @Override public int compareTo(Object o) { A a = (A) o; return count - a.count; } @Override public String toString() { return "A{count=" + count + '}'; } } public static void main(String[] args) { TreeMap treeMap = new TreeMap(); treeMap.put(new A(9), "李一桐"); treeMap.put(new A(7), "刘亦菲"); treeMap.put(new A(-1), "鞠婧祎"); treeMap.put(new A(4), "蔡依林"); System.out.println(treeMap); Map.Entry firstEntry = treeMap.firstEntry(); System.out.println(firstEntry); System.out.println(firstEntry.getKey() + "------->" + firstEntry.getValue()); System.out.println("lastKey is " + treeMap.lastKey()); System.out.println(treeMap.higherEntry(new A(4))); } }
EnumMap
import java.util.EnumMap; public class EnumMapTest { private enum SEASON { SPRING, SUMMER, FALL, WINTER } public static void main(String[] args) { EnumMap enumMap = new EnumMap(SEASON.class); enumMap.put(SEASON.SPRING, "春乱花开"); enumMap.put(SEASON.SUMMER, "夏日炎炎"); enumMap.put(SEASON.FALL, "秋高气爽"); enumMap.put(SEASON.WINTER, "白雪皑皑"); System.out.println(enumMap); } }
各种Map性能分析:
总结:
线程安全的HashMap
1、ConcurrentHashMap - 推荐
private Map<String, Object> map = new ConcurrentHashMap<>();
这是最推荐使用的线程安全的Map,也是实现方式最复杂的一个集合,每个版本的实现方式也不一样,在jdk8之前是使用分段加锁的一个方式,分成16个桶,每次只加锁其中一个桶,而在jdk8又加入了红黑树和CAS算法来实现。性能好
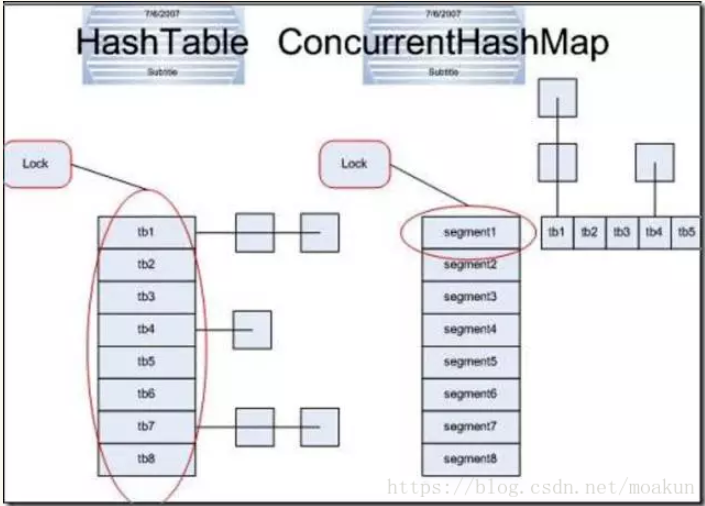
2、HashTable
private Map<String, Object> map = new Hashtable<>();
HashTable的get/put方法都被synchronized关键字修饰,说明它们是方法级别阻塞的,它们占用共享资源锁,所以导致同时只能一个线程操作get或者put,而且get/put操作不能同时执行,所以这种同步的集合效率非常低,一般不建议使用这个集合。

3、SynchronizedMap
private Map<String, Object> map = Collections.synchronizedMap(new HashMap<String, Object>());
这种是直接使用工具类里面的方法创建SynchronizedMap,把传入进行的HashMap对象进行了包装同步而已。这个同步方式实现也比较简单,看出SynchronizedMap的实现方式是加了个对象锁,每次对HashMap的操作都要先获取这个mutex的对象锁才能进入,所以性能也不会比HashTable好到哪里去,也不建议使用。
看源码


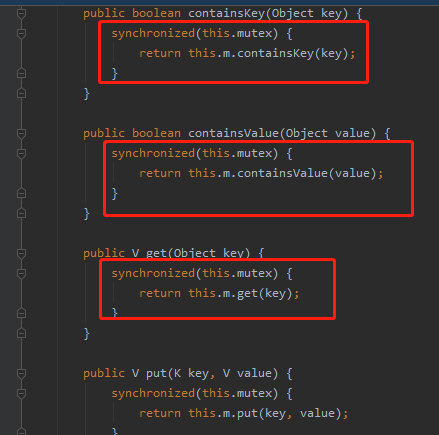
============历史笔记==================
Map集合java.util.Map
以键值对的方式
HashMap hashMap = new HashMap(); //非线程安全
Hashtable hashtable = new Hashtable(); //线程安全
HashMap:底层是Hash表(散列表)
HashTable:线程安全的Hash表。
--Properties 继承了hashTable,键、值都是String字符串用来设置/读取系统属性
TreeMap: 实现了SortedMap接口可以根据键自然排序,要求键必须是可比较的
键是根据红黑树原理排序的,红黑树:一种自平衡二叉树
Map的操作:
clear() 清除元素
containsKey() 判断是否包含键
containsValue() 判断是否包含值
entrySet() 返回所有Entry的集合,
get(Object Key) 返回当前Map中键key对应的Value值
isEmpty() 判断是否为空
KeySet() 返回所有键的集合
put(K key,V value) 向Map中添加元素
putAll(Map<?extends K, ?extend V> m)
remove(Object key) 从map中删除键与key匹配的键值对
remove(Object key, Object value) 从map中删除键与key匹配的键值对
replace(K key , V value) 把map中键与key匹配的值替换为value
size() 返回键值对的数量
values() 返回所有值的集合
15-1 HashMap
15-1-1 示例代码:
//1、定义一个map集合,使用HashMap类实现
Map<String,Integer> map = new HashMap<>();
//2、添加数据
map.put("zhangsan",1300);
map.put("lisi",2370);
map.put("wangwu",2300);
map.put("zhaoliu",17800);
//3、直接打印调用HashMap的toString方法
System.out.println(map);//{lisi=2370, zhaoliu=17800, zhangsan=1300, wangwu=2300}
//4、Map的键不允许重复
map.put("zhaoliu",1234);//如果已存在,用put重复添加将会更新原来的数据=replace的效果
System.out.println(map); //{lisi=2370, zhaoliu=1234, zhangsan=1300, wangwu=2300}
//5、更改
map.replace("zhaoliu",1234);
System.out.println(map);
//6、判断
System.out.println(map.containsKey("zhangsan"));
System.out.println(map.containsValue(2300));
//7、获取Value
System.out.println(map.get("zhangsan"));
System.out.println(map.get("zhangsi")); //不存在返回null
//8、删除
map.remove("zhangsan",9999); //键值都匹配上才删除
System.out.println(map);
map.remove("zhangsan");//键在就删除
System.out.println(map);
//9、遍历
//返回所有键的集合
Set<String> set = map.keySet();
System.out.println(set);
//返回所有值的集合,
for (Integer value : map.values()) {
System.out.println(value);
}
//10、遍历
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
典型应用示例:
//统计一个字符串中每个字符出现的次数
Map<Character,Integer> map = new HashMap<>();
String text = "1234567uyutrewqwertyuytrerfdsadfghjkokmkool,,kxcmnbzsertfgvxfwerdfxdweetrgfdsewethfgcxvcz";
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
if (map.containsKey(c)){ //如果已存在键,把值取出来+1
map.replace(c,map.get(c) + 1); //把值取出来+1,更新键值对
}else {
map.put(c,1); //如果原来没有,put进去,值为1
}
}
System.out.println(map);
15-1-2 HashMap的工作原理
put工作原理:
1)HashMap底层是哈希表,哈希表就是一个数组,数组元素是链表。
2)put添加键值对时:
先根据键的哈希码,经过hash函数计算hash值,根据hash值计算数组下标,访问table[i]元素,
如果该元素为null,就创建节点保存到元素中。
如果该元素不为null,遍历table[i]存储的链表中所有节点
如果有节点的key与当前键相等(Equals),就是用新的value值替换节点中的值
如果所有节点的key都不匹配,就创建一个新的节点插入到链表的尾部
--------传说中的哈希函数:
static final int hash(Object key)
int h;
rerurn (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
//如果key为null 返回0;
//如果不为null,用key的hash码 和 哈希码右移16位 取异或的值。
//(int 占用4个字节,共计32位的长度)
get工作原理: }
先根据键的哈希码,经过hash函数计算hash值,根据hash值计算数组下标,访问table[i]元素,
如果该元素为null返回null
如果不为null,遍历table[i]的链表,如果链表中有节点的键和与当前键Equals相等,就把该节点的value值返回,如果所有节点的key与当前get的键不匹配,返回null
知识点:
如何解决hash碰撞的?
答:-----就是用链表法
JDB中对HashMap做了哪些改进:
答:1、新增节点插入链表尾部
2、链表长度大于8个,会转换为红黑树(自平衡二叉树)
应用案例:取出url中所有请求参数params
Map<String,String[]> map = new HashMap<>();
String urlText = "http://www.baihe.com/register?name=lisi&age=22&gender=女&interest=sing&interest=dance&interest=rap&interest=ball";
//取出url中所有搜索值
int index = urlText.indexOf("?");
//从?后面开始取子串
String paramText = urlText.substring(index + 1);
System.out.println(paramText);//name=lisi&age=22&gender=女&interest=sing&interest=dance&interest=rap&interest=ball
//取出的所有参数缠粉为数组
String[] paramTextArray= paramText.split("[=&]");//正则表达式放到双引号里面
System.out.println(Arrays.toString(paramTextArray));
//对数组遍历取值//每次从paramTextArray数组中取出参数名和参数值两个数据,所以步长为2
for (int i = 0; i < paramTextArray.length; i+=2 ) {
//如果key不存在,就创建一个数组放进map中,key为下标为i的paramTextArray数组值
if (! map.containsKey(paramTextArray[i])){
//添加/创建一个数据放到map集合中,值为一个新数组,创建是传入数据初始化即可
map.put(paramTextArray[i],new String[]{paramTextArray[i+1]});
}else {
//如果已存在则取出原来的数组更新
String[] paramArray = map.get(paramTextArray[i]);
//更新前首先要扩容数组长度
paramArray = Arrays.copyOf(paramArray,paramArray.length +1);
//新增数组元素
paramArray[paramArray.length -1 ] = paramTextArray[i + 1];
//更新元素到
map.replace(paramTextArray[i],paramArray);
}
}
//打印取值的map结果
for (Map.Entry<String, String[]> entry : map.entrySet()) {
System.out.println(entry.getKey() + "="+ Arrays.toString(entry.getValue()));
}
//输出
// gender=[女]
//interest=[sing, dance, rap, ball]
//name=[lisi]
//age=[22]
15-2 HashTable
1)底层都是hash表,HashTable是线程安全的,HahsMap不是线程安全的。
2)初始化容量HashTable为11,HashMap为16
3)加载因子:0.75 当键值对数量> 容量*加载因子 个数进行扩容。
4)扩容:HashTable按2倍+1扩容,HashMap按2倍大小扩容
5) 在使用时HashTable的键与值都不能为null,而HashMap的键和值都可以为null
6)在创建是可以指定初始化容量,HashMap会吧初始化容量自动跳转为2的幂次方,为了快速计算数组下标;而HashTable指定多少就是多少
15-2-1 Properties
继承了HashTable
键值都是String字符串
经常用户设置读取系统属性
方法
setProperty(属性名、属性值)
getProperty(属性名、属性值)
//默认键值都是String,无需指定
示例代码:
Properties properties = new Properties();
properties.setProperty("tdq","123123");
System.out.println(properties.getProperty("tdq"));
System.out.println(properties.getProperty("td"));
//读取系统属性
properties = System.getProperties();
//遍历取值
/* for (Object o : properties.keySet()) {
System.out.println(o);//取key
}*/
//遍历取值entrySet
for (Map.Entry<Object, Object> objectObjectEntry : properties.entrySet()) {
System.out.println(objectObjectEntry.getKey() + "=" + objectObjectEntry.getValue());
}
读取配置文件示例代码:
//propertiesTest02.java
【方法一:代码文件.class.getResourceAsStream()/Thread.currentThread()】
//1、键值默认都是String,创建Properties对象
Properties properties = new Properties();
//2、加载配置文件
InputStream in = propertiesTest02.class.getResourceAsStream("/resources/config.properties");
InputStream in2 = Thread.currentThread().getContextClassLoader().getResourceAsStream("resources/config.properties");
properties.load(in2);//load异常Alt + Enter 选择第一个处理
//3、读取配置文件
System.out.println(properties.getProperty("zmd"));
System.out.println(properties.getProperty("pwd"));
【方法二:通过ResourceBundle.getBundle("相对路径")】
用法ResourceBundle.getBundle("")不需要扩展名和/ ;这个是 静态方法
ResourceBundle resourceBundle = ResourceBundle.getBundle("resources/config");
System.out.println(resourceBundle.getString("zmd"));
System.out.println(resourceBundle.getString("pwd"));
-----------------------------------------------------------
配置文件
目录:properites
文件:propertiesTest02.java
目录:resources
文件:config.properties 【创建方法IDEA new resource bundle】
内容如下:
name=zmd
pwd:123
15-3 TreeMap
TreeMap 实现了SortedMap 接口,可以根据键自然排序,要求键必须是可比较的
1)在构造方法中指定Comparator比较器
2)让键实现Comparable接口
3)TreeMap只能根据键排序,不能根据值排序
4)使用String作为键,String本身已经实现了Comparable接口
示例代码:
//创建TreeMap存储<员工姓名,工资> 要求根据姓名降序排序
TreeMap<String,Integer> treeMap = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
treeMap.put("lisi",2000);
treeMap.put("wangwu",1234);
treeMap.put("zhaoliu",8863);
treeMap.put("chenqi",7800);
System.out.println(treeMap); //{zhaoliu=8863, wangwu=1234, lisi=2000, chenqi=7800}
//注意:TreeMap只能根据键排序,不能根据值排序
//如果没有在构造方法中指定Comparator,键实现Comparable接口即可。基本数据类型已经实现Comparable接口
TreeMap<String,Integer> treeMap1 = new TreeMap<>();
treeMap1.putAll(treeMap);
System.out.println(treeMap1);//默认根据键升序排列
TreeMap中的键是根据共黑树原理排序,是一种自平衡二叉树
二叉树了解:
遍历二叉树的方式有:先序遍历
后序遍历
中序遍历(左子树、根、右子树)