A库a表(红色为抽取字段):

关联用户表:

B库b表(红色为抽取字段):

关联用户表

C目标库SYS_OPLOG表(c表)

利用kettle抽取A库a表(具体名称见上图),B库b表的上面红色框起来的字段到C库c表。由于c表LOG_ID为主键且类型为varachar类型,而A库a表与B库b表的主键f_operation_id列为int类型(自增),
所以抽取时,我将"数据库名_f_operation_id"组织成c表的LOG_ID,在C表中为了区分不同系统,我将"数据库名"作为c表的F_XTBH列。每次抽取时,只抽取c表中不存在的数据,解决方案如下:
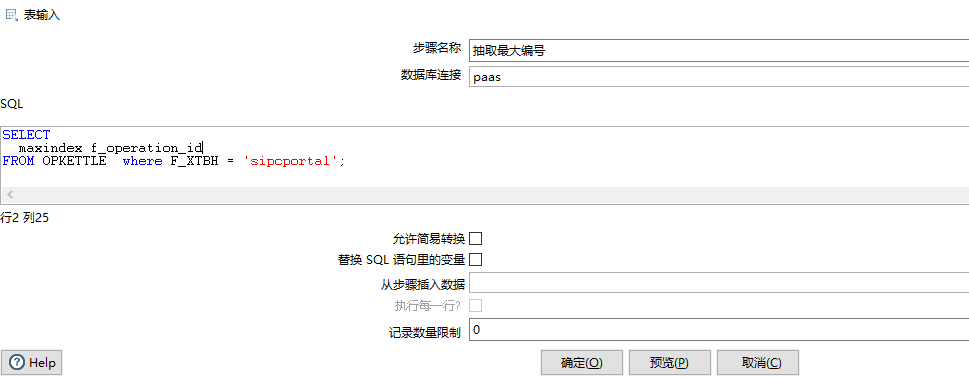
1、在目标库建立OPKETTLE表,其中F_XTBH为待抽取表的数据库名,maxindex为当前已经抽取到的表的f_operation_id位置,(maxindex初始值为0)

2、从OPKETTLE表中查询A数据库的maxindex的值
SELECT maxindex f_operation_id FROM OPKETTLE where F_XTBH = 'sipctask';
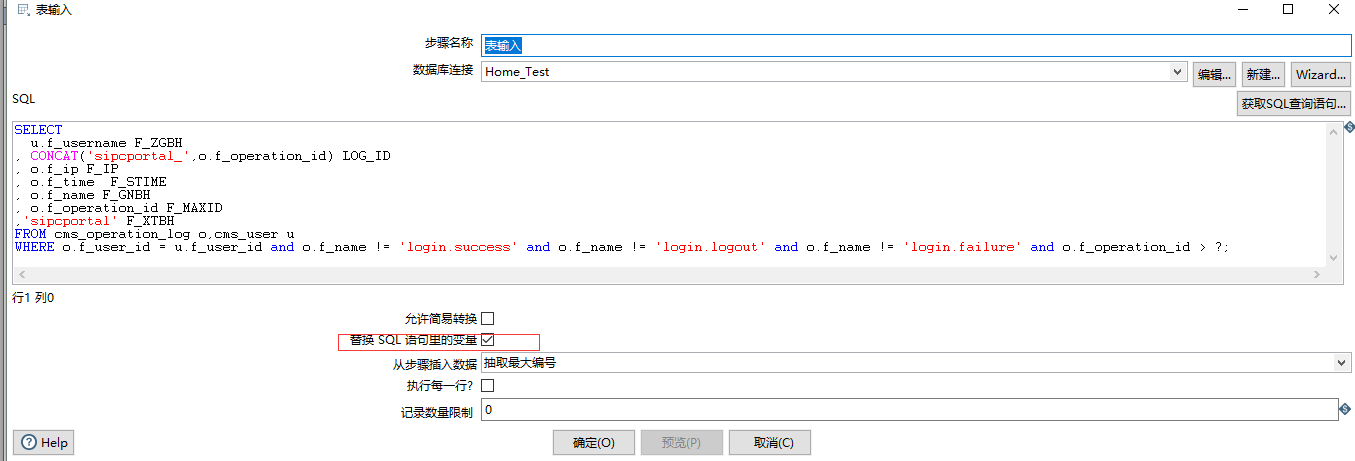
3、抽取A数据库a表的数据,从maxindex+1开始抽取
SELECT
u.f_username F_ZGBH
, CONCAT('sipctask_',o.f_operation_id) LOG_ID
, o.f_ip F_IP
, o.f_time F_STIME
, o.f_name F_GNBH
, o.f_operation_id F_MAXID
,'sipctask' F_XTBH
FROM st_operation_log o,st_user u
WHERE o.f_user_id = u.f_user_id and o.f_name != 'login.success' and o.f_name != 'login.logout' and o.f_name != 'login.failure' and o.f_operation_id > ?;
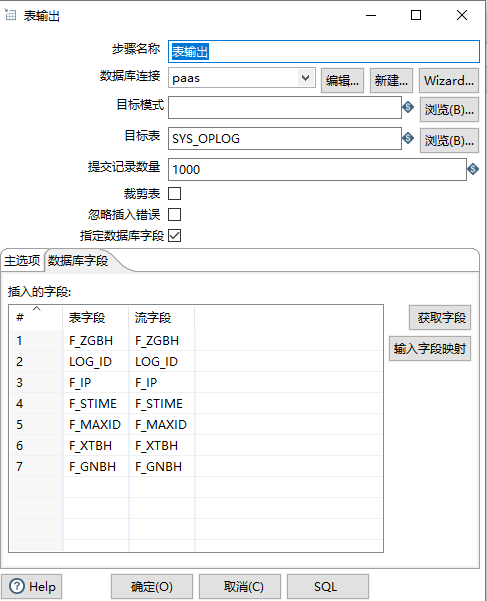
在kettle转换中,通过替换SQL语句中的变量可以获取到第2步sql语句里查询到的当前项目的maxindex值,之后将查询到的数据插入到目标库c表中。
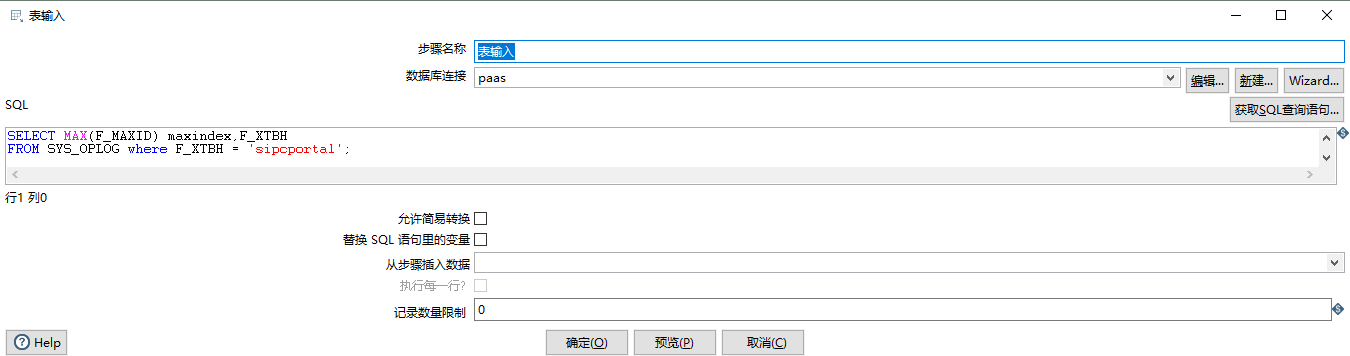
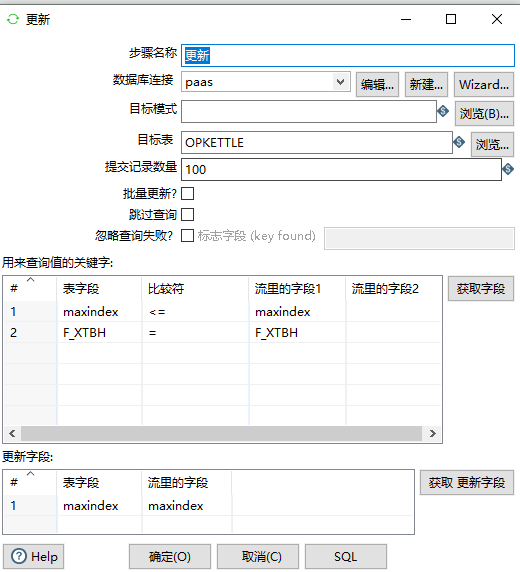
4、更新OPKETTLE表的maxindex的值
SELECT MAX(F_MAXID) maxindex,F_XTBH FROM SYS_OPLOG where F_XTBH = 'sipcportal';
在c表中查询出当前系统已经抽取到的最大编号,之后维护OPKETTLE表的数据
抽取B库b表的过程与上面一致,不在赘余。
抽取A库a表数据到C表c库数据转换图如下:

抽取最大编号:
表输入:
表输出:
更新OPKETTLE表转换图如下:

表输入:
更新:
新建任务(其中"转换"为抽取A库a表数据到C表c库数据转换图,"转换2"为更新OPKETTLE转换图):

Linux定时任务(3分钟执行一次,KETTLE JOB也可以执行定时任务,但是网上说Linux定时任务性能比较好,稳定):
[root@localhost data]# cat kettle_login_ontime.sh #!/bin/sh source /etc/profile ROOT_TOPDIR=/home/data/kettle/ rm -r /home/data/kettle/data-integration/system/karaf/data1 /home/data/kettle/data-integration/kitchen.sh -file=/home/data/kettle/oplogjob.kjb >> /home/data/kettle/data-integration/logs/portaloplog$(date +%Y%m%d).log rm -r /home/data/kettle/data-integration/system/karaf/data1 /home/data/kettle/data-integration/kitchen.sh -file=/home/data/kettle/sipctaskoplogjob.kjb >> /home/data/kettle/data-integration/logs/sipctaskoplog$(date +%Y%m%d).log
