1、概述
1.1 简介
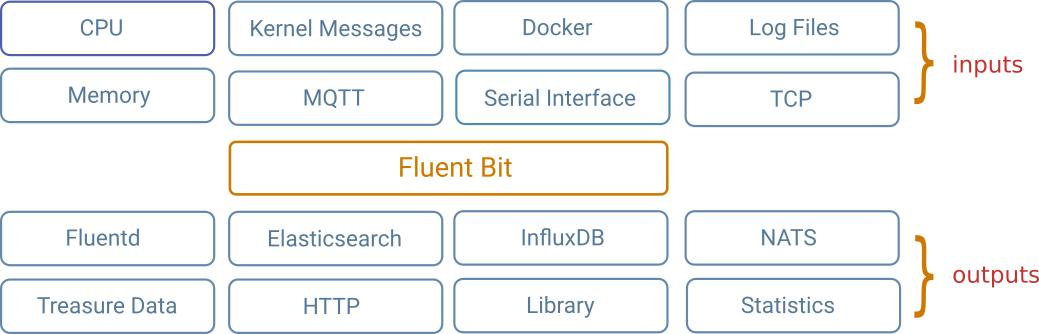
Fluent Bit 是一个开源的日志处理器和转发器,它可以从不同来源收集任何数据,如指标和日志,用过滤器处理它们并将它们发送到多个目的地。它是 Kubernetes 等容器化环境的首选。
Fluent Bit 的设计考虑到了性能:高吞吐量、低 CPU 和内存使用率。它是用 C 语言编写的,具有可插拔架构,支持 70 多种输入、过滤器和输出扩展。
1.2 特点
1. 特点
①事件驱动:使用异步操作来收集和发送数据;
②路由:数据通过插件会被打上tag,可以控制数据发往一个或多个目的地;
③I/O处理: 在Input/Output层提供一个抽象,以异步方式执行读写;
④upstream manager:
⑤安全:通过TLS提供安全传输
2. 突出亮点
①:轻量级、高性能
②:可扩展
③:收集系统信息
1.3 fluentd和fluent-bit的关系及特性
fluentd和fluent-bit都是有Treasure Data公司赞助开发的开源项目,目标是解决日志收集、处理和转发。这两个项目有很多相似之处,fluent-bit完全基于Fluentd体系结构和设计经验。从体系结构的角度来看,选择使用哪个取决于使用场景,我们可以考虑:
- Fluentd是日志收集器,处理器和聚合器。
- fluent-bit是一个日志收集器和处理器(它没有Fluentd等强大的聚合功能)。
|
fluentd |
fluent-bit |
|
|
范围 |
容器/服务器 |
容器/服务器 |
|
语言 |
C和Ruby |
C |
|
大小 |
约40MB |
约450KB |
|
性能 |
高性能 |
高性能 |
|
依赖关系 |
作为Ruby Gem构建,主要依赖gems |
除了一些安装编译插件(GCC、CMAKE)其它零依赖。 |
|
插件支持 |
超过650个可用插件 |
大约35个可用插件 |
|
许可证 |
Apache许可证2.0版 |
Apache许可证2.0版 |
根据两个组件不同特点可以考虑将Fluentd主要用作聚合器,将fluent-bit作为日志转发器,两个项目相互补充,从而提供了完整的可靠轻量级日志解决方案,当然fluent-bit也可以独立完成日志收集。
1.4 fluent-bit支持平台
从体系结构支持的角度来看,fluent-bit在基于x86,x86_64,AArch32和AArch64的处理器上具有全部功能。fluent-bit也可以在OSX和*BSD系统上工作,但并非所有插件在所有平台上都可用。官方支持将根据社区需求而扩大。
2、fluent-bit工作原理
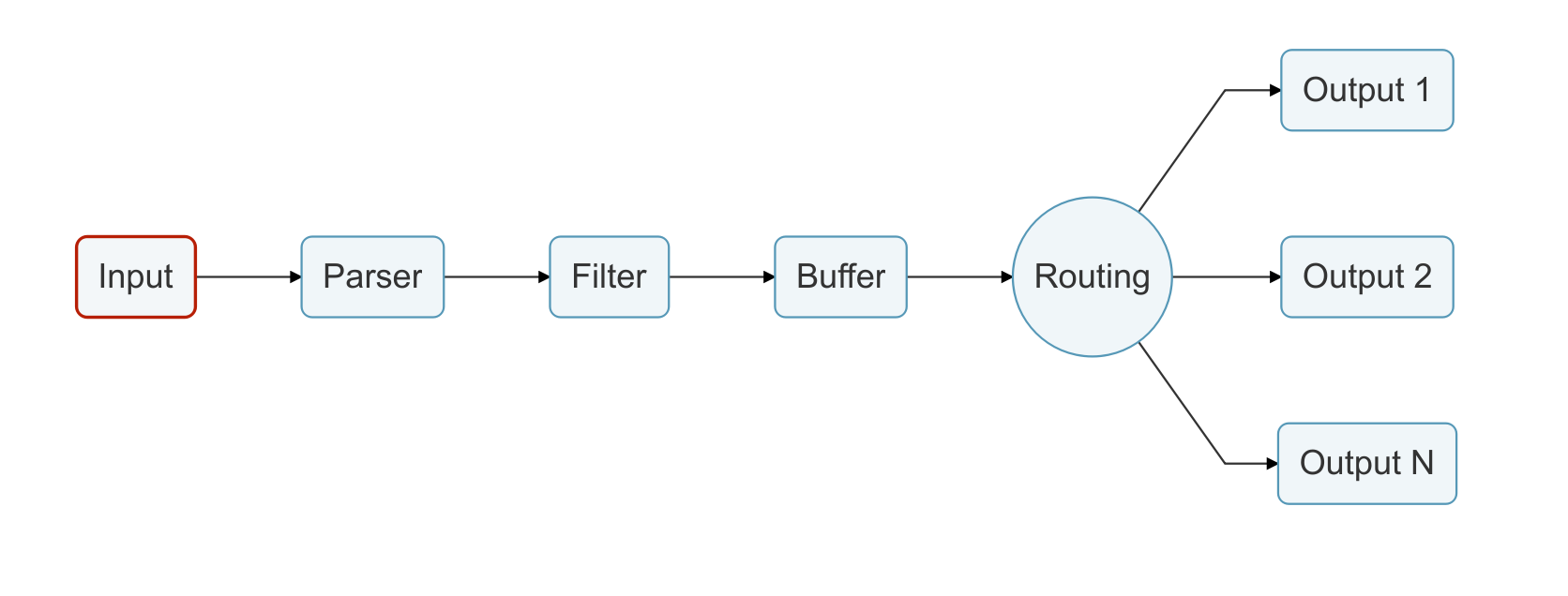
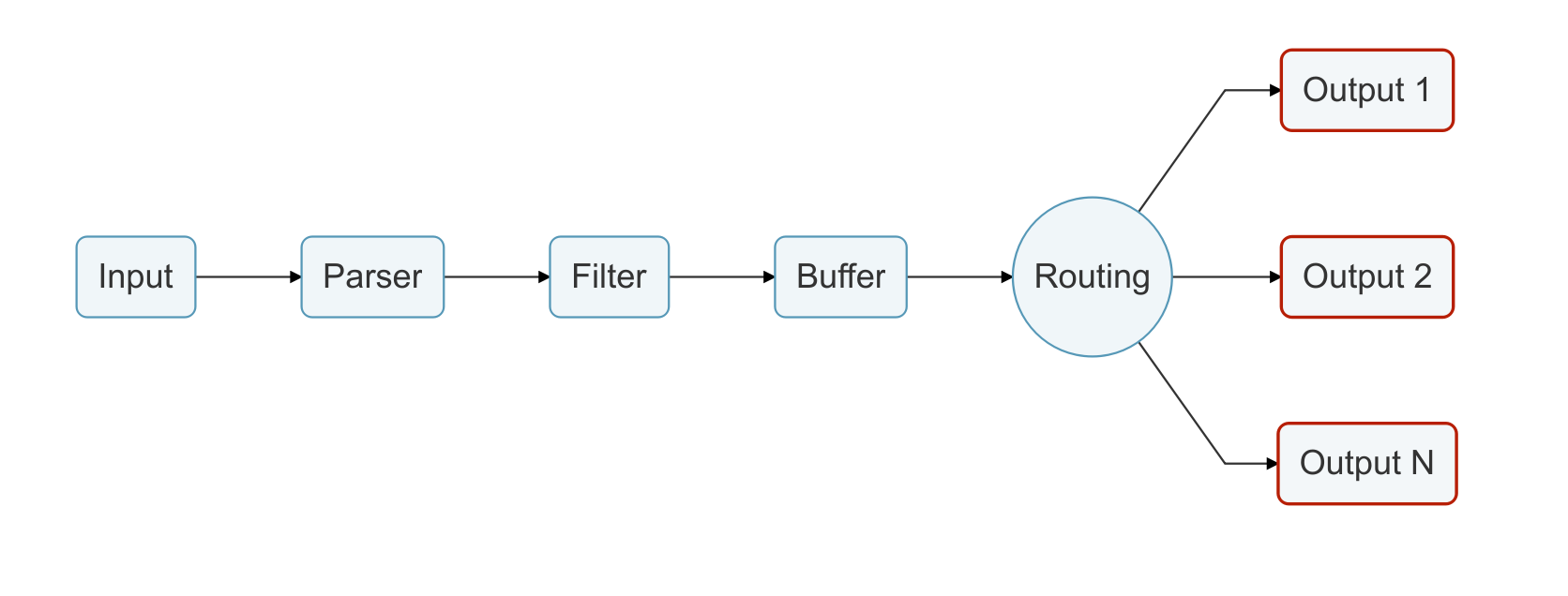
日志通过数据管道从数据源发送到目的地,一个数据管道通常由 Input、Parser、Filter、Buffer、Routing 和 Output组成。
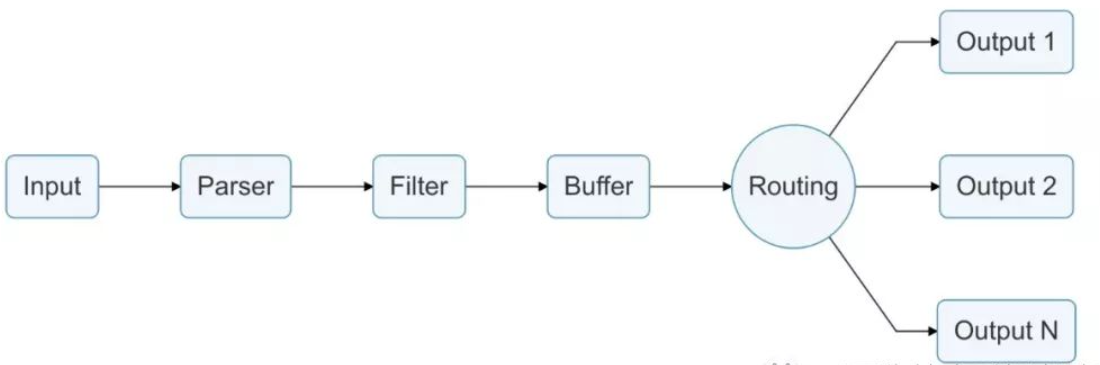
- Input:用于从数据源抽取数据,一个数据管道中可以包含多个 Input。
- Parser:负责将 Input 抽取的非结构化数据转化为标准的结构化数据,每个 Input 均可以定义自己的 Parser。(可选)
- Filter:负责对格式化数据进行过滤和修改。一个数据管道中可以包含多个 Filter,Filter 会顺序执行,其执行顺序与配置文件中的顺序一致。
- Buffer:用户缓存经过 Filter 处理的数据,默认情况下buffer把input插件的数据缓存到内存中,直到路由传递到output为止。
- Routing:将 Buffer 中缓存的数据路由到不同的 Output。
- Output:负责将数据发送到不同的目的地,一个数据管道中可以包含多个 Output。
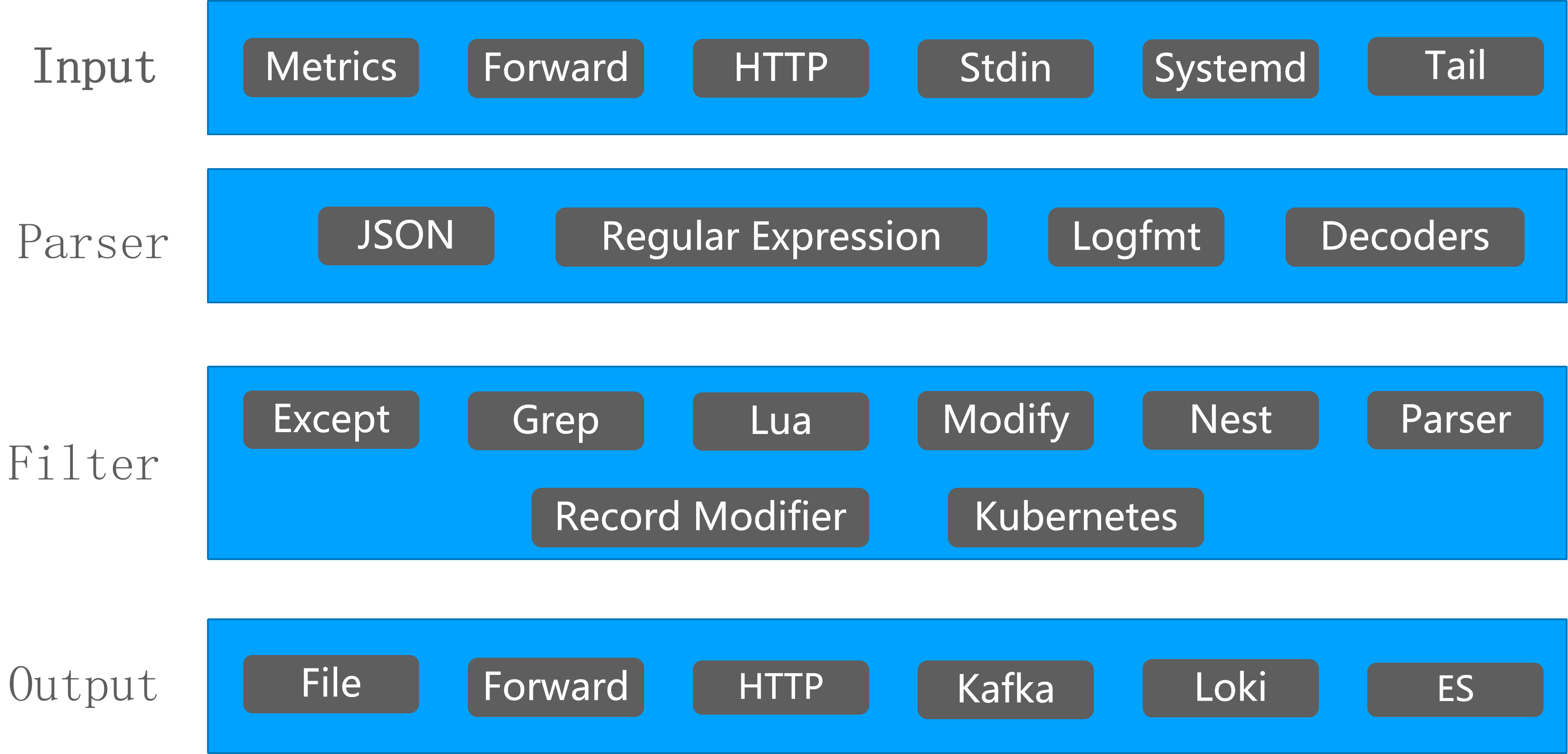
Fluent Bit 支持多种类型的 Input、Parser、Filter、Output 插件,可以应对各种场景。
3、fluent-bit 关键概念
在进入 Fluent Bit 之前,最好先了解一下该服务的一些关键概念。
- 事件或记录。
- 过滤。
- 标签。
- 时间戳。
- 匹配。
- 结构化消息。
3.1 事件或记录(Event or Record)
Fluent Bit 检索到的每一个属于日志或指标的输入数据都被视为事件或记录。
以 Syslog 文件为例:
Jan 18 12:52:16 flb systemd[2222]: Starting GNOME Terminal Server Jan 18 12:52:16 flb dbus-daemon[2243]: [session uid=1000 pid=2243] Successfully activated service 'org.gnome.Terminal' Jan 18 12:52:16 flb systemd[2222]: Started GNOME Terminal Server. Jan 18 12:52:16 flb gsd-media-keys[2640]: # watch_fast: "/org/gnome/terminal/legacy/" (establishing: 0, active: 0)
它包含四行,它们代表四个独立的事件。
在内部,一个事件总是有两个组件(以数组形式):
[TIMESTAMP, MESSAGE]
3.2 过滤(Filtering)
在某些情况下,需要对事件内容执行修改,更改、填充或删除事件的过程称为过滤。
有许多需要过滤的用例,如:
- 向事件附加特定信息,如 IP 地址或元数据。
- 选择一个特定的事件内容。
- 处理匹配特定模式的事件。
3.3 标签(Tag)
每一个进入 Fluent Bit 的事件都会被分配一个标签。这个标签是一个内部字符串,路由器稍后会使用它来决定必须通过哪个 Filter 或 Output 阶段。
大多数标签都是在配置中手动分配的。如果没有指定标签,那么 Fluent Bit 将指定生成事件的输入插件实例的名称作为标签。
唯一不分配标签的输入插件是 Forward 输入。这个插件使用名为 Forward 的 Fluentd wire 协议,其中每个事件都有一个相关的标签。Fluent Bit 将始终使用客户端设置的传入标签。
标签记录必须始终具有匹配规则。要了解关于标签和匹配的更多信息,请查看路由部分。
3.4 时间戳(Timestamp)
时间戳表示事件被创建的时间,每个事件都包含一个相关联的时间戳。时间戳的格式:
SECONDS.NANOSECONDS
Seconds 是自 Unix epoch 以来经过的秒数。
Nanoseconds 是小数秒或十亿分之一秒。
时间戳总是存在的,要么由 Input 插件设置,要么通过数据解析过程发现。
3.5 匹配(Match)
Fluent Bit 允许将收集和处理的事件传递到一个或多个目的地,这是通过路由阶段完成的。匹配表示一个简单的规则,用于选择与已定义规则匹配的事件。
要了解有关标签和匹配的更多信息,请查看路由部分。
3.6 结构化消息(Structured Messages)
源事件可以有或没有结构。结构在事件消息中定义了一组键和值。作为一个例子,考虑以下两个消息:
没有结构化的消息
"Project Fluent Bit created on 1398289291"
结构化消息:
{"project": "Fluent Bit", "created": 1398289291}
在较低的级别上,两者都只是字节数组,但结构化消息定义了键和值,具有结构有助于实现对数据快速修改的操作。
Fluent Bit 总是将每个事件消息作为结构化消息处理。出于性能原因,我们使用名为 MessagePack 的二进制序列化数据格式。
可以把 MessagePack 看作是 JSON 的二进制版本。
4、缓冲
性能和数据安全
当 Fluent Bit 处理数据时,它使用系统内存(heap)作为一个主要的临时位置来存储记录日志,然后在这个私有内存区域中处理记录。
缓冲指的是将记录存储在某个地方的能力,当它们被处理和传递时,仍然能够存储更多的记录。内存缓冲是最快的机制,但在某些情况下,该机制需要特殊的策略来处理背压、数据安全或减少服务在受限环境中的内存消耗。
第三方服务上的网络故障或延迟是很常见的,在接收到新数据时无法足够快地交付数据的情况下,我们可能会面临背压。
我们的缓冲策略旨在解决与背压和一般交付失败相关的问题。
Fluent Bit 作为缓冲策略,在内存中提供了一个主缓冲机制,并使用文件系统提供了一个可选的辅助缓冲机制。使用这种混合解决方案,您可以调整任何用例的安全性,并在处理数据时保持高性能。
这两种机制都不是排他的,当数据准备好被处理或交付时,它将始终在内存中,而队列中的其他数据可能在文件系统中,直到准备好被处理并移到内存中。
要了解更多关于 Fluent Bit 的缓冲配置,请跳转到缓冲和存储部分。
5、数据管道
5.1 输入(Input)
从数据源收集数据的方法
Fluent Bit 提供了不同的输入插件来收集来自不同来源的信息,其中一些插件只是从日志文件中收集数据,而另一些插件则可以从操作系统中收集指标信息。有许多插件可以满足不同的需求。
当一个输入插件被加载时,一个内部实例被创建。每个实例都有自己独立的配置。配置键通常称为属性。
每个输入插件都有自己的文档部分,其中指定了如何使用它和哪些属性可用。
更多的细节,请参考输入插件部分。
5.2 解析(Parser)
将非结构化消息转换为结构化消息
处理原始字符串或非结构化消息是一个持续的痛苦;有一个结构是非常需要的。理想情况下,我们希望在输入插件收集到数据时,为输入数据设置一个结构:
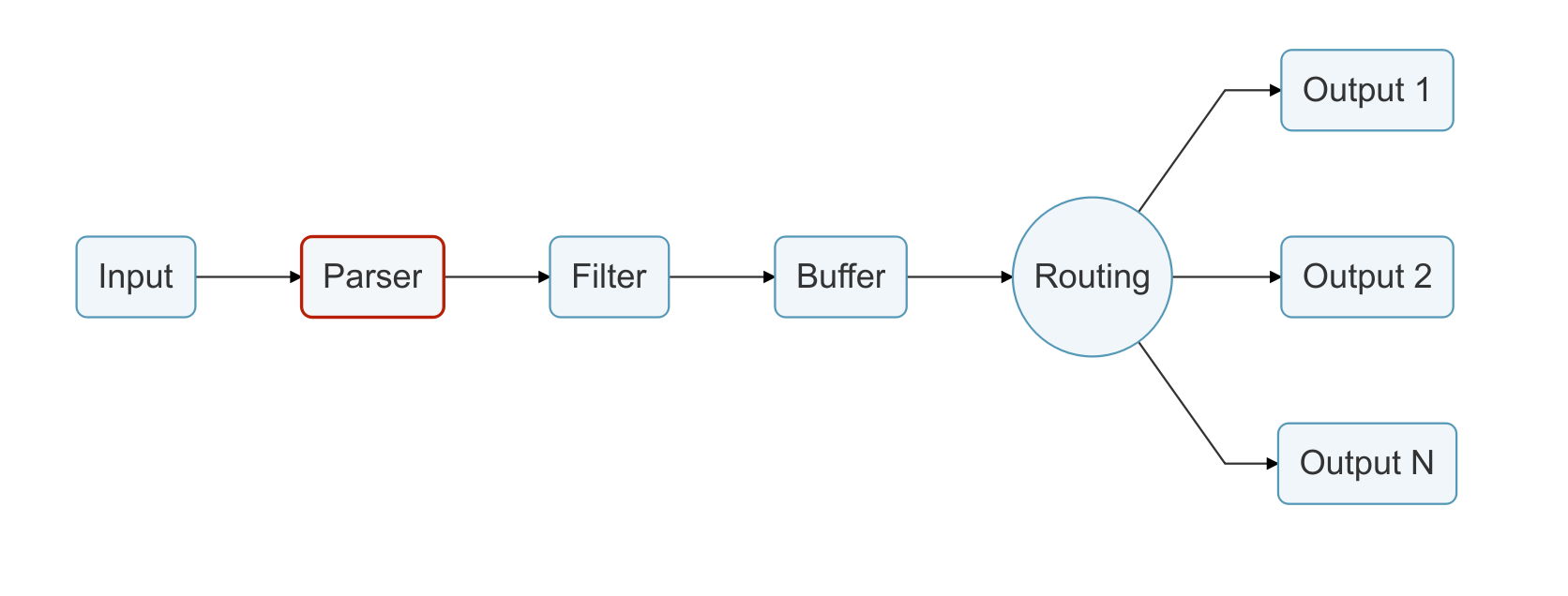
解析器允许您将非结构化数据转换为结构化数据。作为一个演示示例,考虑以下 Apache (HTTP Server) 日志条目:
192.168.2.20 - - [28/Jul/2006:10:27:10 -0300] "GET /cgi-bin/try/ HTTP/1.0" 200 3395
上面的日志行是一个没有格式的原始字符串,理想情况下,我们希望给它一个结构,之后就可以较容易地处理。如果使用了适当的配置,日志条目可以转换为:
{
"host": "192.168.2.20",
"user": "-",
"method": "GET",
"path": "/cgi-bin/try/",
"code": "200",
"size": "3395",
"referer": "",
"agent": ""
}
解析器是完全可配置的,可以由每个输入插件独立处理,更多细节请参考解析器部分。
5.3 过滤(Filter)
修改、丰富或删除您的记录
在生产环境中,我们希望完全控制所收集的数据,筛选是一个重要特性,它允许我们在将数据交付到某个目的地之前修改数据。
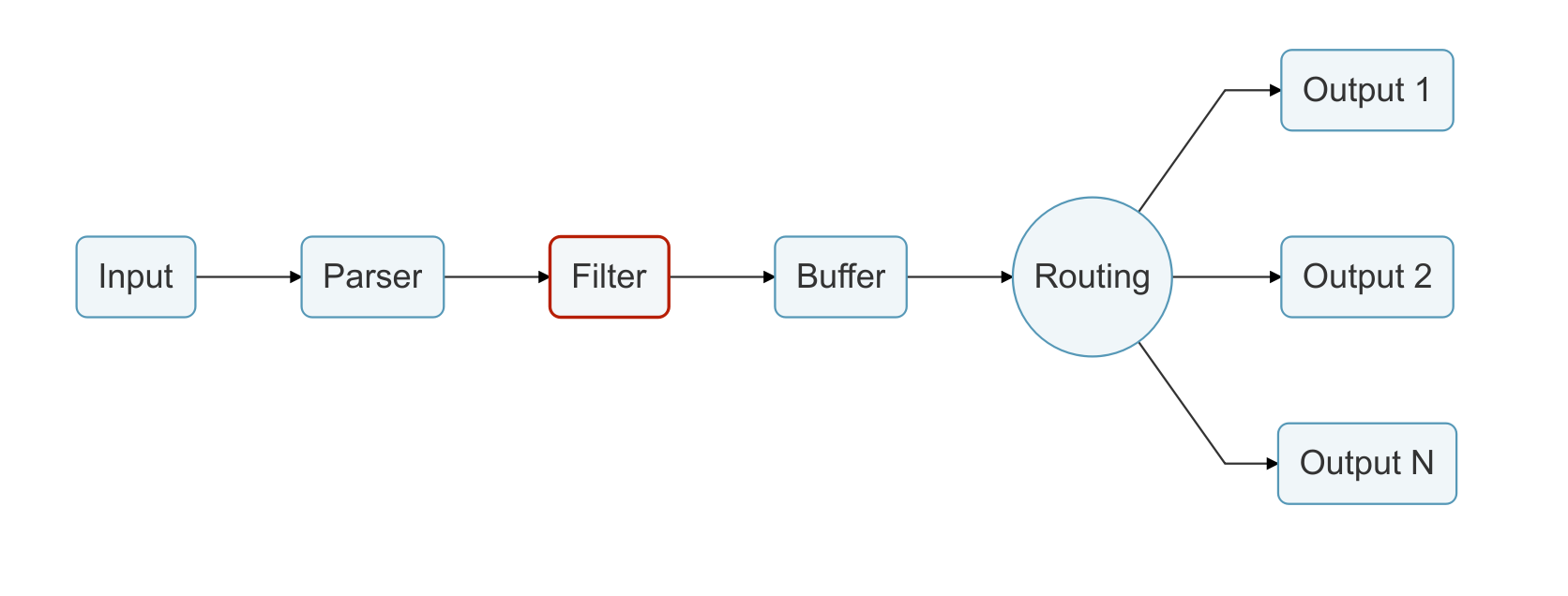
过滤是通过插件实现的,所以每个可用的过滤器都可以用来匹配、排除或用一些特定的元数据丰富您的日志。
我们支持很多过滤器,一个常见的过滤用例是 Kubernetes 的部署。每个 Pod 日志都需要得到适当的关联元数据。
与输入插件非常相似,过滤器在实例上下文中运行,它有自己独立的配置。配置键通常称为属性。
有关可用过滤器及其用法的详细信息,请参阅过滤器部分。
5.4 缓冲(Buffer)
可靠的数据处理
在前面的 Buffering 概念部分中定义,管道中的缓冲阶段旨在提供统一和持久的机制来存储数据,可以使用主内存模型,也可以使用基于文件系统的模式。
缓冲阶段已经包含了处于不可变状态的数据,这意味着不能应用其他筛选器。
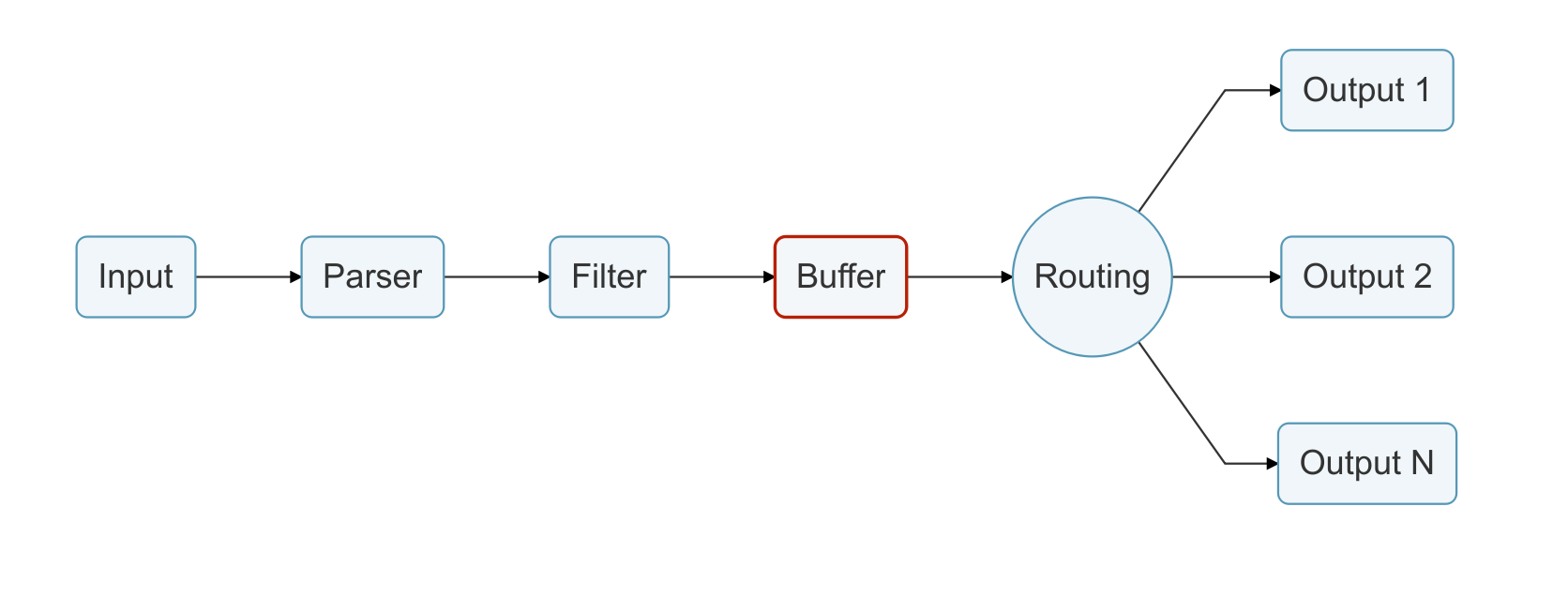
注意,缓冲数据不是原始文本,而是 Fluent Bit 内部的二进制表示。
Fluent Bit 在文件系统中提供缓冲机制,充当备份系统,以避免系统故障时数据丢失。
5.5. 路由(Router)
创建灵活的路由规则
路由是一个核心特性,它允许将数据通过过滤器路由到一个或多个目的地。路由器依赖于标签和匹配规则的概念。
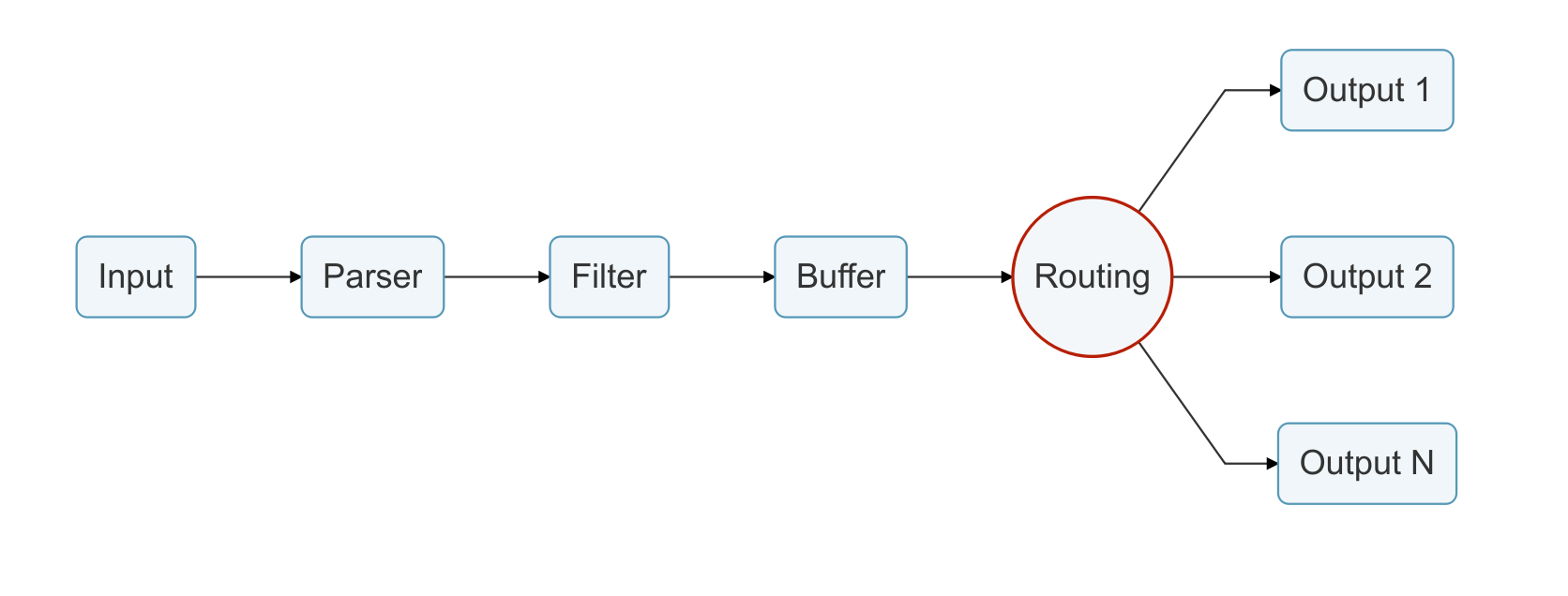
路由中有两个重要的概念:
- Tag
- Match
当数据由输入插件生成时,它带有一个 Tag(大多数情况下,Tag 是手动配置的),Tag 是一个人类可读的指示器,帮助识别数据源。
为了定义应该将数据路由到何处,必须在输出配置中指定 Match 规则。
思考下面的配置示例,目的是将 CPU 指标交付给 Elasticsearch 数据库,并将内存指标交付给标准输出接口:
[INPUT]
Name cpu
Tag my_cpu
[INPUT]
Name mem
Tag my_mem
[OUTPUT]
Name es
Match my_cpu
[OUTPUT]
Name stdout
Match my_mem
注意:上面是一个简单的例子,演示了如何配置路由。
路由自动读取输入标签和输出匹配规则。如果某些数据的 Tag 在路由配置上不匹配,则删除该数据。
路由与通配符
路由非常灵活,Match 模式可以支持通配符。下面的例子定义了两个数据源的共同目标:
[INPUT] Name cpu Tag my_cpu [INPUT] Name mem Tag my_mem [OUTPUT] Name stdout Match my_*
匹配规则被设置为my_*,这意味着它将匹配任何以my_开头的标签。
5.6 输出(Output)
您的数据目的地:数据库,云服务和更多!
输出接口允许我们定义数据的目的地。常见的目标是远程服务、本地文件系统或与其他人的标准接口。输出以插件的形式实现,并且有许多可用的插件。
当一个输出插件被加载时,一个内部实例被创建。每个实例都有自己独立的配置。配置键通常称为属性。
每个输出插件都有自己的文档部分,指定如何使用它以及哪些属性可用。