本文参考文章https://blog.csdn.net/u013733326/article/details/80250818完成,原文写的非常好,非常详细,如果是第一次做这个作业的同学可以去看一下这个作者的文章,非常推荐。
本次作业的内容有两项,一是框架Keras的入门练习,二是搭建一个残差网络。下面开始第一项任务。
1 Keras入门 - 笑脸识别
Keras框架是一个高级的神经网络的框架,能够运行在包括TensorFlow和CNTK的几个较低级别的框架之上的框架。通过引入所需要的库可以实现从Keras中导入很多功能, 只需直接调用它们即可轻松使用它们。 比如:X = Input(…) 或者X = ZeroPadding2D(…)。
1 import numpy as np 2 from keras import layers 3 from keras.layers import Input, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D 4 from keras.layers import AveragePooling2D, MaxPooling2D, Dropout, GlobalMaxPooling2D, GlobalAveragePooling2D 5 from keras.models import Model 6 from keras.preprocessing import image 7 from keras.utils import layer_utils 8 from keras.utils.data_utils import get_file 9 from keras.applications.imagenet_utils import preprocess_input 10 import pydot 11 from IPython.display import SVG 12 from keras.utils.vis_utils import model_to_dot 13 from keras.utils import plot_model 14 import kt_utils 15 16 import keras.backend as K 17 K.set_image_data_format('channels_last') 18 import matplotlib.pyplot as plt 19 from matplotlib.pyplot import imshow
1.1 任务描述
此次项目实现的功能就是识别图片中的人是否是笑脸,来判断人物是否开心,下面是我们的数据集:

我们先来加载一下我们的数据:
1 X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = kt_utils.load_dataset() 2 3 # Normalize image vectors 4 X_train = X_train_orig/255. 5 X_test = X_test_orig/255. 6 7 # Reshape 8 Y_train = Y_train_orig.T 9 Y_test = Y_test_orig.T 10 print ("number of training examples = " + str(X_train.shape[0])) 11 print ("number of test examples = " + str(X_test.shape[0])) 12 print ("X_train shape: " + str(X_train.shape)) 13 print ("Y_train shape: " + str(Y_train.shape)) 14 print ("X_test shape: " + str(X_test.shape)) 15 print ("Y_test shape: " + str(Y_test.shape))

可以看到图片的维度是64*64*3,训练集有600张,测试集有150张。
1.2 构建模型
接下来我们利用Keras框架构建出来我们要的模型:
1 def HappyModel(input_shape): 2 """ 3 实现一个检测笑容的模型 4 5 参数: 6 input_shape - 输入的数据的维度 7 返回: 8 model - 创建的Keras的模型 9 10 """ 11 12 # 你可以参考和上面的大纲 13 X_input = Input(input_shape) 14 15 # 使用0填充:X_input的周围填充0 16 X = ZeroPadding2D((3, 3))(X_input) 17 18 # 对X使用 CONV -> BN -> RELU 块 19 X = Conv2D(32, (7, 7), strides=(1, 1), name='conv0')(X) 20 X = BatchNormalization(axis=3, name='bn0')(X) 21 X = Activation('relu')(X) 22 23 # 最大值池化层 24 X = MaxPooling2D((2, 2), name='max_pool')(X) 25 26 # 降维,矩阵转化为向量 + 全连接层 27 X = Flatten()(X) 28 X = Dense(1, activation='sigmoid', name='fc')(X) 29 30 # 创建模型,讲话创建一个模型的实体,我们可以用它来训练、测试。 31 model = Model(inputs=X_input, outputs=X, name='HappyModel') 32 33 return model
可以看到用Keras框架实现的模型非常简单,因为框架为我们提供了比如填充、卷积操作等函数,我们只需要用一行代码调用一下就行,并且只需要完成前向传播,所以看起来很方便。
现在我们已经设计好了我们的模型了,要训练并测试模型我们需要这么做:
- 创建一个模型实体。
- 编译模型,可以使用这个语句:
model.compile(optimizer = "...", loss = "...", metrics = ["accuracy"])。 - 训练模型:
model.fit(x = ..., y = ..., epochs = ..., batch_size = ...)。 - 评估模型:
model.evaluate(x = ..., y = ...)。
接下来我们运行这些步骤:
1 #创建一个模型实体 2 happy_model = HappyModel(X_train.shape[1:]) 3 #编译模型 4 happy_model.compile("adam","binary_crossentropy", metrics=['accuracy']) 5 #训练模型 6 #请注意,此操作会花费你大约6-10分钟。 7 happy_model.fit(X_train, Y_train, epochs=40, batch_size=50) 8 #评估模型 9 preds = happy_model.evaluate(X_test, Y_test, batch_size=32, verbose=1, sample_weight=None) 10 print ("误差值 = " + str(preds[0])) 11 print ("准确度 = " + str(preds[1]))
下面是我的运行结果:

以上就是用Keras搭建的卷积神经网络框架,Keras框架还是很强的,应该仔细的学一下,另外,在搭建项目之前遇到了版本对应的错误,因为Keras框架运行于TensorFlow之上,所以会用到这两种框架,我安装的TensorFlow是1.5版本的,默认安装的Keras框架是最新版本2.4多的,所以这两框架不匹配,大家在实现之前可以先看一下自己的TensorFlow框架的版本,在网上查一下匹配版本对应,再安装对应版本的Keras。
2 残差网络的搭建
第二项作业是搭建残差网络,残差网络一般深度都很大,利用残差网络可以解决过深的网络难以训练的问题。此次作业实现两部分:一是实现残差块,二是把这些残差块放一起,实现并训练用于图像分类的网络。首先是用到的库函数。
1 import numpy as np 2 import tensorflow as tf 3 4 from keras import layers 5 from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D 6 from keras.models import Model, load_model 7 from keras.preprocessing import image 8 from keras.utils import layer_utils 9 from keras.utils.data_utils import get_file 10 from keras.applications.imagenet_utils import preprocess_input 11 from keras.utils.vis_utils import model_to_dot 12 from keras.utils import plot_model 13 from keras.initializers import glorot_uniform 14 15 import pydot 16 from IPython.display import SVG 17 import scipy.misc 18 from matplotlib.pyplot import imshow 19 import keras.backend as K 20 K.set_image_data_format('channels_last') 21 K.set_learning_phase(1) 22 23 import resnets_utils
2.1 构建一个残差网络
在残差网络中,一个“捷径(shortcut)”或者说“跳跃连接(skip connection)”允许梯度直接反向传播到更浅的层,如下图:

图像左边是神经网络的主路,图像右边是添加了一条捷径的主路,通过这些残差块堆叠在一起,可以形成一个非常深的网络。
我们在视频中可以看到使用捷径的方式使得每一个残差块能够很容易学习到恒等式功能,这意味着我们可以添加很多的残差块而不会损害训练集的表现。
残差块有两种类型,主要取决于输入输出的维度是否相同
2.1.1 恒等块(Identity block)
恒等块是残差网络使用的的标准块,对应于输入的激活值(比如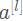 )与输出激活值(比如
)与输出激活值(比如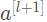 )具有相同的维度。为了具象化残差块的不同步骤,我们来看看下面的图吧~
)具有相同的维度。为了具象化残差块的不同步骤,我们来看看下面的图吧~

上图就是一个恒等块,大家可以看一下原文作者对于恒等块的介绍,要实现这个恒等块不仅要实现主路径的内容,还要把这条捷径表示出来。具体步骤如下:
-
主路径的第一部分:
-
第一个CONV2D有F1个过滤器,其大小为(1,1),步长为(1,1),使用填充方式为“valid”,命名规则为
conv_name_base + '2a',使用0作为随机种子为其初始化。 -
第一个BatchNorm是通道的轴归一化,其命名规则为
bn_name_base + '2a'。 -
接着使用ReLU激活函数,它没有命名也没有超参数。
-
-
主路径的第二部分:
-
第二个CONV2D有F2个过滤器,其大小为(f,f),步长为(1,1),使用填充方式为“same”,命名规则为
conv_name_base + '2b',使用0作为随机种子为其初始化。 -
第二个BatchNorm是通道的轴归一化,其命名规则为
bn_name_base + '2b'。 -
接着使用ReLU激活函数,它没有命名也没有超参数。
-
-
主路径的第三部分:
-
第三个CONV2D有F3个过滤器,其大小为(1,1),步长为(1,1),使用填充方式为“valid”,命名规则为
conv_name_base + '2c',使用0作为随机种子为其初始化。 -
第三个BatchNorm是通道的轴归一化,其命名规则为
bn_name_base + '2c'。 -
注意这里没有ReLU函数
-
-
最后一步:
-
将捷径与输入加在一起
-
使用ReLU激活函数,它没有命名也没有超参数。
-
接下来我们就要代码实现残差网络的恒等块了,在实现之前,我们可以先看看Keras框架的中文使用手册:https://keras-cn.readthedocs.io/en/latest/layers/convolutional_layer/#conv2d
1 def identity_block(X, f, filters, stage, block): 2 """ 3 实现图3的恒等块 4 5 参数: 6 X - 输入的tensor类型的数据,维度为( m, n_H_prev, n_W_prev, n_H_prev ) 7 f - 整数,指定主路径中间的CONV窗口的维度 8 filters - 整数列表,定义了主路径每层的卷积层的过滤器数量 9 stage - 整数,根据每层的位置来命名每一层,与block参数一起使用。 10 block - 字符串,据每层的位置来命名每一层,与stage参数一起使用。 11 12 返回: 13 X - 恒等块的输出,tensor类型,维度为(n_H, n_W, n_C) 14 15 """ 16 17 #定义命名规则 18 conv_name_base = "res" + str(stage) + block + "_branch" 19 bn_name_base = "bn" + str(stage) + block + "_branch" 20 21 #获取过滤器 22 F1, F2, F3 = filters 23 24 #保存输入数据,将会用于为主路径添加捷径 25 X_shortcut = X 26 27 #主路径的第一部分 28 ##卷积层 29 X = Conv2D(filters=F1, kernel_size=(1,1), strides=(1,1) ,padding="valid", 30 name=conv_name_base+"2a", kernel_initializer=glorot_uniform(seed=0))(X) 31 ##归一化 32 X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X) 33 ##使用ReLU激活函数 34 X = Activation("relu")(X) 35 36 #主路径的第二部分 37 ##卷积层 38 X = Conv2D(filters=F2, kernel_size=(f,f),strides=(1,1), padding="same", 39 name=conv_name_base+"2b", kernel_initializer=glorot_uniform(seed=0))(X) 40 ##归一化 41 X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X) 42 ##使用ReLU激活函数 43 X = Activation("relu")(X) 44 45 46 #主路径的第三部分 47 ##卷积层 48 X = Conv2D(filters=F3, kernel_size=(1,1), strides=(1,1), padding="valid", 49 name=conv_name_base+"2c", kernel_initializer=glorot_uniform(seed=0))(X) 50 ##归一化 51 X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X) 52 ##没有ReLU激活函数 53 54 #最后一步: 55 ##将捷径与输入加在一起 56 X = Add()([X,X_shortcut]) 57 ##使用ReLU激活函数 58 X = Activation("relu")(X) 59 60 return X
2.1.2 卷积块
我们已经实现了残差网络的恒等块,现在,残差网络的卷积块是另一种类型的残差块,它适用于输入输出的维度不一致的情况,它不同于上面的恒等块,与之区别在于,捷径中有一个CONV2D层,如下图:
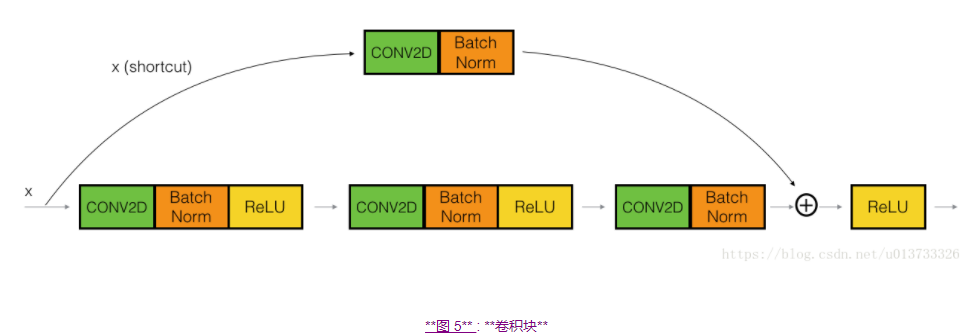
捷径中的卷积层将把输入x卷积为不同的维度,因此在主路径最后那里需要适配捷径中的维度。比如:把激活值中的宽高减少2倍,我们可以使用1x1的卷积,步伐为2。捷径上的卷积层不使用任何非线性激活函数,它的主要作用是仅仅应用(学习后的)线性函数来减少输入的维度,以便在后面的加法步骤中的维度相匹配。
具体步骤如下:
-
主路径第一部分:
-
第一个卷积层有F1个过滤器,其维度为(1,1),步伐为(s,s),使用“valid”的填充方式,命名规则为
conv_name_base + '2a' -
第一个规范层是通道的轴归一化,其命名规则为
bn_name_base + '2a' -
使用ReLU激活函数,它没有命名规则也没有超参数。
-
-
主路径第二部分:
-
第二个卷积层有F2个过滤器,其维度为(f,f),步伐为(1,1),使用“same”的填充方式,命名规则为
conv_name_base + '2b' -
第二个规范层是通道的轴归一化,其命名规则为
bn_name_base + '2b' -
使用ReLU激活函数,它没有命名规则也没有超参数。
-
-
主路径第三部分:
-
第三个卷积层有F3个过滤器,其维度为(1,1),步伐为(s,s),使用“valid”的填充方式,命名规则为
conv_name_base + '2c' -
第三个规范层是通道的轴归一化,其命名规则为
bn_name_base + '2c' -
没有激活函数
-
-
捷径:
-
此卷积层有F3个过滤器,其维度为(1,1),步伐为(s,s),使用“valid”的填充方式,命名规则为
conv_name_base + '1' -
此规范层是通道的轴归一化,其命名规则为
bn_name_base + '1'
-
-
最后一步:
-
将捷径与输入加在一起
-
使用ReLU激活函数
-
下面是实现代码:
1 def convolutional_block(X, f, filters, stage, block, s=2): 2 """ 3 实现图5的卷积块 4 5 参数: 6 X - 输入的tensor类型的变量,维度为( m, n_H_prev, n_W_prev, n_C_prev) 7 f - 整数,指定主路径中间的CONV窗口的维度 8 filters - 整数列表,定义了主路径每层的卷积层的过滤器数量 9 stage - 整数,根据每层的位置来命名每一层,与block参数一起使用。 10 block - 字符串,据每层的位置来命名每一层,与stage参数一起使用。 11 s - 整数,指定要使用的步幅 12 13 返回: 14 X - 卷积块的输出,tensor类型,维度为(n_H, n_W, n_C) 15 """ 16 17 #定义命名规则 18 conv_name_base = "res" + str(stage) + block + "_branch" 19 bn_name_base = "bn" + str(stage) + block + "_branch" 20 21 #获取过滤器数量 22 F1, F2, F3 = filters 23 24 #保存输入数据 25 X_shortcut = X 26 27 #主路径 28 ##主路径第一部分 29 X = Conv2D(filters=F1, kernel_size=(1,1), strides=(s,s), padding="valid", 30 name=conv_name_base+"2a", kernel_initializer=glorot_uniform(seed=0))(X) 31 X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X) 32 X = Activation("relu")(X) 33 34 ##主路径第二部分 35 X = Conv2D(filters=F2, kernel_size=(f,f), strides=(1,1), padding="same", 36 name=conv_name_base+"2b", kernel_initializer=glorot_uniform(seed=0))(X) 37 X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X) 38 X = Activation("relu")(X) 39 40 ##主路径第三部分 41 X = Conv2D(filters=F3, kernel_size=(1,1), strides=(1,1), padding="valid", 42 name=conv_name_base+"2c", kernel_initializer=glorot_uniform(seed=0))(X) 43 X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X) 44 45 #捷径 46 X_shortcut = Conv2D(filters=F3, kernel_size=(1,1), strides=(s,s), padding="valid", 47 name=conv_name_base+"1", kernel_initializer=glorot_uniform(seed=0))(X_shortcut) 48 X_shortcut = BatchNormalization(axis=3,name=bn_name_base+"1")(X_shortcut) 49 50 #最后一步 51 X = Add()([X,X_shortcut]) 52 X = Activation("relu")(X) 53 54 return X
2.2 构建一个残差网络(50层)
我们已经做完所需要的所有残差块了,下面这个图就描述了神经网络的算法细节,图中的"ID BLOCK"是指标准的恒等块,"ID BLOCK X3"是指把三个恒等块放在一起。

这个50层的网络的细节如下:
-
对输入数据进行0填充,padding =(3,3)
-
stage1:
-
卷积层有64个过滤器,其维度为(7,7),步伐为(2,2),命名为“conv1”
-
规范层(BatchNorm)对输入数据进行通道轴归一化。
-
最大值池化层使用一个(3,3)的窗口和(2,2)的步伐。
-
-
stage2:
-
卷积块使用f=3个大小为[64,64,256]的过滤器,f=3,s=1,block=“a”
-
2个恒等块使用三个大小为[64,64,256]的过滤器,f=3,block=“b”、“c”
-
-
stage3:
-
卷积块使用f=3个大小为[128,128,512]的过滤器,f=3,s=2,block=“a”
-
3个恒等块使用三个大小为[128,128,512]的过滤器,f=3,block=“b”、“c”、“d”
-
-
stage4:
-
卷积块使用f=3个大小为[256,256,1024]的过滤器,f=3,s=2,block=“a”
-
5个恒等块使用三个大小为[256,256,1024]的过滤器,f=3,block=“b”、“c”、“d”、“e”、“f”
-
-
stage5:
-
卷积块使用f=3个大小为[512,512,2048]的过滤器,f=3,s=2,block=“a”
-
2个恒等块使用三个大小为[256,256,2048]的过滤器,f=3,block=“b”、“c”
-
-
均值池化层使用维度为(2,2)的窗口,命名为“avg_pool”
-
展开操作没有任何超参数以及命名
-
全连接层(密集连接)使用softmax激活函数,命名为
"fc" + str(classes)
1 def ResNet50(input_shape=(64,64,3),classes=6): 2 """ 3 实现ResNet50 4 CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3 5 -> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER 6 7 参数: 8 input_shape - 图像数据集的维度 9 classes - 整数,分类数 10 11 返回: 12 model - Keras框架的模型 13 14 """ 15 16 #定义tensor类型的输入数据 17 X_input = Input(input_shape) 18 19 #0填充 20 X = ZeroPadding2D((3,3))(X_input) 21 22 #stage1 23 X = Conv2D(filters=64, kernel_size=(7,7), strides=(2,2), name="conv1", 24 kernel_initializer=glorot_uniform(seed=0))(X) 25 X = BatchNormalization(axis=3, name="bn_conv1")(X) 26 X = Activation("relu")(X) 27 X = MaxPooling2D(pool_size=(3,3), strides=(2,2))(X) 28 29 #stage2 30 X = convolutional_block(X, f=3, filters=[64,64,256], stage=2, block="a", s=1) 31 X = identity_block(X, f=3, filters=[64,64,256], stage=2, block="b") 32 X = identity_block(X, f=3, filters=[64,64,256], stage=2, block="c") 33 34 #stage3 35 X = convolutional_block(X, f=3, filters=[128,128,512], stage=3, block="a", s=2) 36 X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="b") 37 X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="c") 38 X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="d") 39 40 #stage4 41 X = convolutional_block(X, f=3, filters=[256,256,1024], stage=4, block="a", s=2) 42 X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="b") 43 X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="c") 44 X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="d") 45 X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="e") 46 X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="f") 47 48 #stage5 49 X = convolutional_block(X, f=3, filters=[512,512,2048], stage=5, block="a", s=2) 50 X = identity_block(X, f=3, filters=[512,512,2048], stage=5, block="b") 51 X = identity_block(X, f=3, filters=[512,512,2048], stage=5, block="c") 52 53 #均值池化层 54 X = AveragePooling2D(pool_size=(2,2),padding="same")(X) 55 56 #输出层 57 X = Flatten()(X) 58 X = Dense(classes, activation="softmax", name="fc"+str(classes), 59 kernel_initializer=glorot_uniform(seed=0))(X) 60 61 62 #创建模型 63 model = Model(inputs=X_input, outputs=X, name="ResNet50") 64 65 return model
然后我们对模型做实体化和编译工作:
1 model = ResNet50(input_shape=(64,64,3),classes=6) 2 model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
模型准备好后,我们就可以加载数据进行训练了:
1 X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = resnets_utils.load_dataset() 2 3 # Normalize image vectors 4 X_train = X_train_orig / 255. 5 X_test = X_test_orig / 255. 6 7 # Convert training and test labels to one hot matrices 8 Y_train = resnets_utils.convert_to_one_hot(Y_train_orig, 6).T 9 Y_test = resnets_utils.convert_to_one_hot(Y_test_orig, 6).T 10 11 model.fit(X_train,Y_train,epochs=2,batch_size=32)
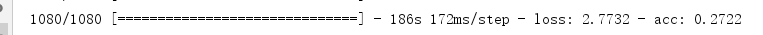
这样,残差网络就训练完毕了,原作者还利用模型测试了自己拍的图片,我就不做测试了,另外作者绘制了网络结构图(可以去原作者那里看这张图,图片比较长),利用这张图可以很清晰的看懂网络结构,其实残差网络并不复杂,无非就是网络层数比较多,但是没有太复杂的结构。本周的作业是基于Keras框架的,由于对该框架掌握不深,所以此次作业的代码都是参考的原作者的代码,再次感谢一下作者。
参考文章:https://blog.csdn.net/u013733326/article/details/80250818