本文参考博文https://blog.csdn.net/u013733326/article/details/80086090完成。
1.神经网络的底层搭建
本次作业要求我们要实现一个拥有卷积层(CONV)和池化层(POOL)的网络,它包含了前向和反向传播。首先我们确定一下此次项目要实现的功能模块。
-
卷积模块,包含了以下函数:
- 使用0扩充边界
- 卷积窗口
- 前向卷积
- 反向卷积(可选)
-
池化模块,包含了以下函数:
- 前向池化
- 创建掩码
- 值分配
- 反向池化(可选)
因为我写这篇博客主要是为了巩固学习吴恩达老师深度学习课程的知识,所以对于一些名词的解释就不再赘述了。直接进入正题。
1.1、边界填充函数
边界填充函数作用是在图像周围添加一些像素值为0的像素点,如下图所示:

使用0填充边界有以下好处:
1、卷积了上一层之后的CONV层,没有缩小高度和宽度。 这对于建立更深的网络非常重要,否则在更深层时,高度/宽度会缩小。 一个重要的例子是“same”卷积,其中高度/宽度在卷积完一层之后会被完全保留。
2、它可以帮助我们在图像边界保留更多信息。在没有填充的情况下,卷积过程中图像边缘的极少数值会受到过滤器的影响从而导致信息丢失。
接下来编写好零扩充边界函数:
1 def zero_pad(X, pad): 2 """ 3 把数据集X的图像边界全部使用0来扩充pad个宽度和高度。 4 5 参数: 6 X - 图像数据集,维度为(样本数,图像高度,图像宽度,图像通道数) 7 pad - 整数,每个图像在垂直和水平维度上的填充量 8 返回: 9 X_paded - 扩充后的图像数据集,维度为(样本数,图像高度 + 2*pad,图像宽度 + 2*pad,图像通道数) 10 11 """ 12 13 X_paded = np.pad(X, ( 14 (0, 0), # 样本数,不填充 15 (pad, pad), # 图像高度,你可以视为上面填充x个,下面填充y个(x,y) 16 (pad, pad), # 图像宽度,你可以视为左边填充x个,右边填充y个(x,y) 17 (0, 0)), # 通道数,不填充 18 'constant', constant_values=0) # 连续一样的值填充 19 20 return X_paded
1.2、单步卷积
填充好边界之后,我们可以准备单步的卷积操作,卷积操作的意思老师课程里有讲过,我自己理解就是利用过滤器进行特征的提取,下面是代码:
1 def conv_single_step(a_slice_prev,W,b): 2 """ 3 在前一层的激活输出的一个片段上应用一个由参数W定义的过滤器。 4 这里切片大小和过滤器大小相同 5 6 参数: 7 a_slice_prev - 输入数据的一个片段,维度为(过滤器大小,过滤器大小,上一通道数) 8 W - 权重参数,包含在了一个矩阵中,维度为(过滤器大小,过滤器大小,上一通道数) 9 b - 偏置参数,包含在了一个矩阵中,维度为(1,1,1) 10 11 返回: 12 Z - 在输入数据的片X上卷积滑动窗口(w,b)的结果。 13 """ 14 15 s = np.multiply(a_slice_prev,W) + b 16 17 Z = np.sum(s) 18 19 return Z
1.3、卷积层前向传播
接下来利用编写好的卷积操作函数来进行卷积神经网络中的前向传播操作,前向传播就是利用多种过滤器对输入的数据进行卷积计算,每一个滤波器卷积计算之后会得到一个2维的矩阵,把这一层所有的2维矩阵组合到一起形成一个高维矩阵。我们需要实现一个函数以实现对激活值进行卷积。我们需要在激活值矩阵Aprev上使用过滤器W进行卷积。该函数的输入是前一层的激活输出Aprev,F个过滤器,其权重矩阵为W、偏置矩阵为b,每个过滤器只有一个偏置,最后,我们需要一个包含了步长s和填充p的字典类型的超参数。
1 def conv_forward(A_prev, W, b, hparameters): 2 """ 3 实现卷积函数的前向传播 4 5 参数: 6 A_prev - 上一层的激活输出矩阵,维度为(m, n_H_prev, n_W_prev, n_C_prev),(样本数量,上一层图像的高度,上一层图像的宽度,上一层过滤器数量) 7 W - 权重矩阵,维度为(f, f, n_C_prev, n_C),(过滤器大小,过滤器大小,上一层的过滤器数量,这一层的过滤器数量) 8 b - 偏置矩阵,维度为(1, 1, 1, n_C),(1,1,1,这一层的过滤器数量) 9 hparameters - 包含了"stride"与 "pad"的超参数字典。 10 11 返回: 12 Z - 卷积输出,维度为(m, n_H, n_W, n_C),(样本数,图像的高度,图像的宽度,过滤器数量) 13 cache - 缓存了一些反向传播函数conv_backward()需要的一些数据 14 """ 15 16 #获取来自上一层数据的基本信息 17 (m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape 18 19 #获取权重矩阵的基本信息 20 ( f , f ,n_C_prev , n_C ) = W.shape 21 22 #获取超参数hparameters的值 23 stride = hparameters["stride"] 24 pad = hparameters["pad"] 25 26 #计算卷积后的图像的宽度高度,参考上面的公式,使用int()来进行板除 27 n_H = int(( n_H_prev - f + 2 * pad )/ stride) + 1 28 n_W = int(( n_W_prev - f + 2 * pad )/ stride) + 1 29 30 #使用0来初始化卷积输出Z 31 Z = np.zeros((m,n_H,n_W,n_C)) 32 33 #通过A_prev创建填充过了的A_prev_pad 34 A_prev_pad = zero_pad(A_prev,pad) 35 36 for i in range(m): #遍历样本 37 a_prev_pad = A_prev_pad[i] #选择第i个样本的扩充后的激活矩阵 38 for h in range(n_H): #在输出的垂直轴上循环 39 for w in range(n_W): #在输出的水平轴上循环 40 for c in range(n_C): #循环遍历输出的通道 41 #定位当前的切片位置 42 vert_start = h * stride #竖向,开始的位置 43 vert_end = vert_start + f #竖向,结束的位置 44 horiz_start = w * stride #横向,开始的位置 45 horiz_end = horiz_start + f #横向,结束的位置 46 #切片位置定位好了我们就把它取出来,需要注意的是我们是“穿透”取出来的, 47 #自行脑补一下吸管插入一层层的橡皮泥就明白了 48 a_slice_prev = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:] 49 #执行单步卷积 50 Z[i,h,w,c] = conv_single_step(a_slice_prev,W[: ,: ,: ,c],b[0,0,0,c]) 51 52 #数据处理完毕,验证数据格式是否正确 53 assert(Z.shape == (m , n_H , n_W , n_C )) 54 55 #存储一些缓存值,以便于反向传播使用 56 cache = (A_prev,W,b,hparameters) 57 58 return (Z , cache)
注意上面的代码用的是循环操作,没有用向量化和框架。可以看出过程还是比较繁琐的。
1.4、池化层
池化层会减少输入的宽度和高度,这样它会较少计算量的同时也使特征检测器对其在输入中的位置更加稳定。下面介绍两种类型的池化层:
-
最大值池化层:在输入矩阵中滑动一个大小为fxf的窗口,选取窗口里的值中的最大值,然后作为输出的一部分。
-
均值池化层:在输入矩阵中滑动一个大小为fxf的窗口,计算窗口里的值中的平均值,然后这个均值作为输出的一部分。
池化层没有用于进行反向传播的参数,但是它们有像窗口的大小为f的超参数,它指定fxf窗口的高度和宽度,我们可以计算出最大值或平均值。
池化层前向传播:
现在我们要在同一个函数中实现最大值池化层和均值池化层。
1 def pool_forward(A_prev,hparameters,mode="max"): 2 """ 3 实现池化层的前向传播 4 5 参数: 6 A_prev - 输入数据,维度为(m, n_H_prev, n_W_prev, n_C_prev) 7 hparameters - 包含了 "f" 和 "stride"的超参数字典 8 mode - 模式选择【"max" | "average"】 9 10 返回: 11 A - 池化层的输出,维度为 (m, n_H, n_W, n_C) 12 cache - 存储了一些反向传播需要用到的值,包含了输入和超参数的字典。 13 """ 14 15 #获取输入数据的基本信息 16 (m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape 17 18 #获取超参数的信息 19 f = hparameters["f"] 20 stride = hparameters["stride"] 21 22 #计算输出维度 23 n_H = int((n_H_prev - f) / stride ) + 1 24 n_W = int((n_W_prev - f) / stride ) + 1 25 n_C = n_C_prev 26 27 #初始化输出矩阵 28 A = np.zeros((m , n_H , n_W , n_C)) 29 30 for i in range(m): #遍历样本 31 for h in range(n_H): #在输出的垂直轴上循环 32 for w in range(n_W): #在输出的水平轴上循环 33 for c in range(n_C): #循环遍历输出的通道 34 #定位当前的切片位置 35 vert_start = h * stride #竖向,开始的位置 36 vert_end = vert_start + f #竖向,结束的位置 37 horiz_start = w * stride #横向,开始的位置 38 horiz_end = horiz_start + f #横向,结束的位置 39 #定位完毕,开始切割 40 a_slice_prev = A_prev[i,vert_start:vert_end,horiz_start:horiz_end,c] 41 42 #对切片进行池化操作 43 if mode == "max": 44 A[ i , h , w , c ] = np.max(a_slice_prev) 45 elif mode == "average": 46 A[ i , h , w , c ] = np.mean(a_slice_prev) 47 48 #池化完毕,校验数据格式 49 assert(A.shape == (m , n_H , n_W , n_C)) 50 51 #校验完毕,开始存储用于反向传播的值 52 cache = (A_prev,hparameters) 53 54 return A,cache
1.5、卷积神经网络中的反向传播
在现在的深度学习框架中我们不需要事先反向传播,只需要实现前向传播就行,吴恩达老师的课程中也没有介绍,我就在原博文中了解了一下。
1 def conv_backward(dZ,cache): 2 """ 3 实现卷积层的反向传播 4 5 参数: 6 dZ - 卷积层的输出Z的 梯度,维度为(m, n_H, n_W, n_C) 7 cache - 反向传播所需要的参数,conv_forward()的输出之一 8 9 返回: 10 dA_prev - 卷积层的输入(A_prev)的梯度值,维度为(m, n_H_prev, n_W_prev, n_C_prev) 11 dW - 卷积层的权值的梯度,维度为(f,f,n_C_prev,n_C) 12 db - 卷积层的偏置的梯度,维度为(1,1,1,n_C) 13 14 """ 15 #获取cache的值 16 (A_prev, W, b, hparameters) = cache 17 18 #获取A_prev的基本信息 19 (m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape 20 21 #获取dZ的基本信息 22 (m,n_H,n_W,n_C) = dZ.shape 23 24 #获取权值的基本信息 25 (f, f, n_C_prev, n_C) = W.shape 26 27 #获取hparaeters的值 28 pad = hparameters["pad"] 29 stride = hparameters["stride"] 30 31 #初始化各个梯度的结构 32 dA_prev = np.zeros((m,n_H_prev,n_W_prev,n_C_prev)) 33 dW = np.zeros((f,f,n_C_prev,n_C)) 34 db = np.zeros((1,1,1,n_C)) 35 36 #前向传播中我们使用了pad,反向传播也需要使用,这是为了保证数据结构一致 37 A_prev_pad = zero_pad(A_prev,pad) 38 dA_prev_pad = zero_pad(dA_prev,pad) 39 40 #现在处理数据 41 for i in range(m): 42 #选择第i个扩充了的数据的样本,降了一维。 43 a_prev_pad = A_prev_pad[i] 44 da_prev_pad = dA_prev_pad[i] 45 46 for h in range(n_H): 47 for w in range(n_W): 48 for c in range(n_C): 49 #定位切片位置 50 vert_start = h 51 vert_end = vert_start + f 52 horiz_start = w 53 horiz_end = horiz_start + f 54 55 #定位完毕,开始切片 56 a_slice = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:] 57 58 #切片完毕,使用上面的公式计算梯度 59 da_prev_pad[vert_start:vert_end, horiz_start:horiz_end,:] += W[:,:,:,c] * dZ[i, h, w, c] 60 dW[:,:,:,c] += a_slice * dZ[i,h,w,c] 61 db[:,:,:,c] += dZ[i,h,w,c] 62 #设置第i个样本最终的dA_prev,即把非填充的数据取出来。 63 dA_prev[i,:,:,:] = da_prev_pad[pad:-pad, pad:-pad, :] 64 65 #数据处理完毕,验证数据格式是否正确 66 assert(dA_prev.shape == (m, n_H_prev, n_W_prev, n_C_prev)) 67 68 return (dA_prev,dW,db)
1 def create_mask_from_window(x): 2 """ 3 从输入矩阵中创建掩码,以保存最大值的矩阵的位置。 4 5 参数: 6 x - 一个维度为(f,f)的矩阵 7 8 返回: 9 mask - 包含x的最大值的位置的矩阵 10 """ 11 mask = x == np.max(x) 12 13 return mask
1 def distribute_value(dz,shape): 2 """ 3 给定一个值,为按矩阵大小平均分配到每一个矩阵位置中。 4 5 参数: 6 dz - 输入的实数 7 shape - 元组,两个值,分别为n_H , n_W 8 9 返回: 10 a - 已经分配好了值的矩阵,里面的值全部一样。 11 12 """ 13 #获取矩阵的大小 14 (n_H , n_W) = shape 15 16 #计算平均值 17 average = dz / (n_H * n_W) 18 19 #填充入矩阵 20 a = np.ones(shape) * average 21 22 return a
1 def pool_backward(dA,cache,mode = "max"): 2 """ 3 实现池化层的反向传播 4 5 参数: 6 dA - 池化层的输出的梯度,和池化层的输出的维度一样 7 cache - 池化层前向传播时所存储的参数。 8 mode - 模式选择,【"max" | "average"】 9 10 返回: 11 dA_prev - 池化层的输入的梯度,和A_prev的维度相同 12 13 """ 14 #获取cache中的值 15 (A_prev , hparaeters) = cache 16 17 #获取hparaeters的值 18 f = hparaeters["f"] 19 stride = hparaeters["stride"] 20 21 #获取A_prev和dA的基本信息 22 (m , n_H_prev , n_W_prev , n_C_prev) = A_prev.shape 23 (m , n_H , n_W , n_C) = dA.shape 24 25 #初始化输出的结构 26 dA_prev = np.zeros_like(A_prev) 27 28 #开始处理数据 29 for i in range(m): 30 a_prev = A_prev[i] 31 for h in range(n_H): 32 for w in range(n_W): 33 for c in range(n_C): 34 #定位切片位置 35 vert_start = h 36 vert_end = vert_start + f 37 horiz_start = w 38 horiz_end = horiz_start + f 39 40 #选择反向传播的计算方式 41 if mode == "max": 42 #开始切片 43 a_prev_slice = a_prev[vert_start:vert_end,horiz_start:horiz_end,c] 44 #创建掩码 45 mask = create_mask_from_window(a_prev_slice) 46 #计算dA_prev 47 dA_prev[i,vert_start:vert_end,horiz_start:horiz_end,c] += np.multiply(mask,dA[i,h,w,c]) 48 49 elif mode == "average": 50 #获取dA的值 51 da = dA[i,h,w,c] 52 #定义过滤器大小 53 shape = (f,f) 54 #平均分配 55 dA_prev[i,vert_start:vert_end, horiz_start:horiz_end ,c] += distribute_value(da,shape) 56 #数据处理完毕,开始验证格式 57 assert(dA_prev.shape == A_prev.shape) 58 59 return dA_prev
以上就是使用原生代码实现的神经网络,接下来作者使用了TensorFlow框架来搭建了一个卷积神经网络,并将它应用于手势识别中。
2、神经网络的应用
2.1、TensorFlow模型
首先是导入所需要的库:
1 import math 2 import numpy as np 3 import h5py 4 import matplotlib.pyplot as plt 5 import matplotlib.image as mpimg 6 import tensorflow as tf 7 from tensorflow.python.framework import ops 8 9 import cnn_utils 10 11 np.random.seed(1)
数据集使用的是课程二中TensorFlow入门那节课的课后作业的数据集:
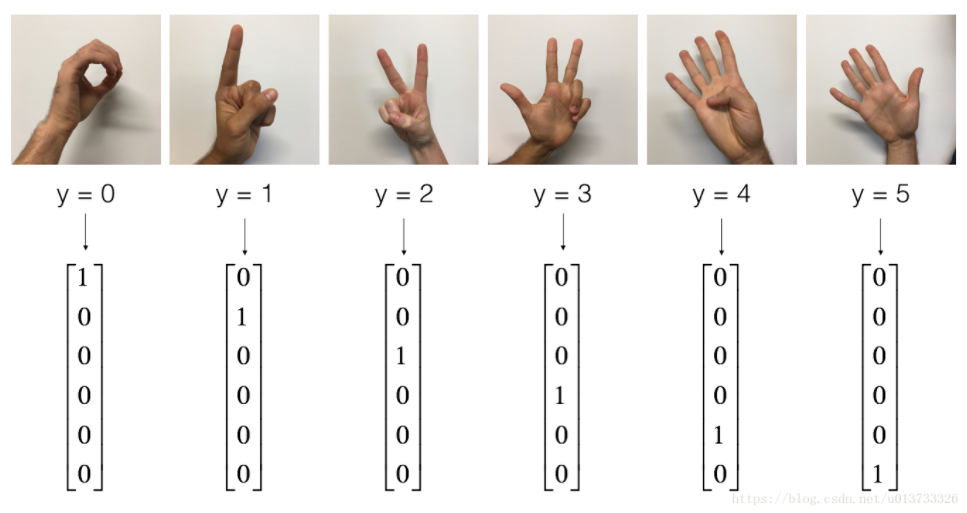
2.2、 创建placeholders
TensorFlow要求您为运行会话时将输入到模型中的输入数据创建占位符。现在我们要实现创建占位符的函数,因为我们使用的是小批量数据块,输入的样本数量可能不固定,所以我们在数量那里我们要使用None作为可变数量。输入X的维度为**[None,n_H0,n_W0,n_C0],对应的Y是[None,n_y]**。
1 def create_placeholders(n_H0, n_W0, n_C0, n_y): 2 """ 3 为session创建占位符 4 5 参数: 6 n_H0 - 实数,输入图像的高度 7 n_W0 - 实数,输入图像的宽度 8 n_C0 - 实数,输入的通道数 9 n_y - 实数,分类数 10 11 输出: 12 X - 输入数据的占位符,维度为[None, n_H0, n_W0, n_C0],类型为"float" 13 Y - 输入数据的标签的占位符,维度为[None, n_y],维度为"float" 14 """ 15 X = tf.placeholder(tf.float32,[None, n_H0, n_W0, n_C0]) 16 Y = tf.placeholder(tf.float32,[None, n_y]) 17 18 return X,Y
2.3、初始化参数
现在我们将使用tf.contrib.layers.xavier_initializer(seed = 0) 来初始化权值/过滤器W1、W2。在这里,我们不需要考虑偏置,因为TensorFlow会考虑到的。需要注意的是我们只需要初始化为2D卷积函数,全连接层TensorFlow会自动初始化的。
1 def initialize_parameters(): 2 """ 3 初始化权值矩阵,这里我们把权值矩阵硬编码: 4 W1 : [4, 4, 3, 8] 5 W2 : [2, 2, 8, 16] 6 7 返回: 8 包含了tensor类型的W1、W2的字典 9 """ 10 tf.set_random_seed(1) 11 12 W1 = tf.get_variable("W1",[4,4,3,8],initializer=tf.contrib.layers.xavier_initializer(seed=0)) 13 W2 = tf.get_variable("W2",[2,2,8,16],initializer=tf.contrib.layers.xavier_initializer(seed=0)) 14 15 parameters = {"W1": W1, 16 "W2": W2} 17 18 return parameters
2.4、前向传播
在TensorFlow里面有一些可以直接拿来用的函数:
-
tf.nn.conv2d(X,W1,strides=[1,s,s,1],padding='SAME'):给定输入XXX和一组过滤器W1W1W1,这个函数将会自动使用W1W1W1来对XXX进行卷积,第三个输入参数是**[1,s,s,1]**是指对于输入 (m, n_H_prev, n_W_prev, n_C_prev)而言,每次滑动的步伐。 -
tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = 'SAME'):给定输入XXX,该函数将会使用大小为(f,f)以及步伐为(s,s)的窗口对其进行滑动取最大值 -
tf.contrib.layers.flatten(P):给定一个输入P,此函数将会把每个样本转化成一维的向量,然后返回一个tensor变量,其维度为(batch_size,k) -
tf.contrib.layers.fully_connected(F, num_outputs):给定一个已经一维化了的输入F,此函数将会返回一个由全连接层计算过后的输出。
使用tf.contrib.layers.fully_connected(F, num_outputs)的时候,全连接层会自动初始化权值且在你训练模型的时候它也会一直参与,所以当我们初始化参数的时候我们不需要专门去初始化它的权值。
我们实现前向传播的时候,我们需要定义一下我们模型的大概样子:

我们具体实现的时候,我们需要使用以下的步骤和参数:
- Conv2d : 步伐:1,填充方式:“SAME”
- ReLU
- Max pool : 过滤器大小:8x8,步伐:8x8,填充方式:“SAME”
- Conv2d : 步伐:1,填充方式:“SAME”
- ReLU
- Max pool : 过滤器大小:4x4,步伐:4x4,填充方式:“SAME”
- 一维化上一层的输出
- 全连接层(FC):使用没有非线性激活函数的全连接层。这里不要调用SoftMax, 这将导致输出层中有6个神经元,然后再传递到softmax。 在TensorFlow中,softmax和cost函数被集中到一个函数中,在计算成本时您将调用不同的函数。
1 def forward_propagation(X,parameters): 2 """ 3 实现前向传播 4 CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED 5 6 参数: 7 X - 输入数据的placeholder,维度为(输入节点数量,样本数量) 8 parameters - 包含了“W1”和“W2”的python字典。 9 10 返回: 11 Z3 - 最后一个LINEAR节点的输出 12 13 """ 14 W1 = parameters['W1'] 15 W2 = parameters['W2'] 16 17 #Conv2d : 步伐:1,填充方式:“SAME” 18 Z1 = tf.nn.conv2d(X,W1,strides=[1,1,1,1],padding="SAME") 19 #ReLU : 20 A1 = tf.nn.relu(Z1) 21 #Max pool : 窗口大小:8x8,步伐:8x8,填充方式:“SAME” 22 P1 = tf.nn.max_pool(A1,ksize=[1,8,8,1],strides=[1,8,8,1],padding="SAME") 23 24 #Conv2d : 步伐:1,填充方式:“SAME” 25 Z2 = tf.nn.conv2d(P1,W2,strides=[1,1,1,1],padding="SAME") 26 #ReLU : 27 A2 = tf.nn.relu(Z2) 28 #Max pool : 过滤器大小:4x4,步伐:4x4,填充方式:“SAME” 29 P2 = tf.nn.max_pool(A2,ksize=[1,4,4,1],strides=[1,4,4,1],padding="SAME") 30 31 #一维化上一层的输出 32 P = tf.contrib.layers.flatten(P2) 33 34 #全连接层(FC):使用没有非线性激活函数的全连接层 35 Z3 = tf.contrib.layers.fully_connected(P,6,activation_fn=None) 36 37 return Z3 38
2.5、计算成本
我们要在这里实现计算成本的函数,下面的两个函数是我们要用到的:
-
tf.nn.softmax_cross_entropy_with_logits(logits = Z3 , lables = Y):计算softmax的损失函数。这个函数既计算softmax的激活,也计算其损失 -
tf.reduce_mean:计算的是平均值,使用它来计算所有样本的损失来得到总成本。
1 def compute_cost(Z3,Y): 2 """ 3 计算成本 4 参数: 5 Z3 - 正向传播最后一个LINEAR节点的输出,维度为(6,样本数)。 6 Y - 标签向量的placeholder,和Z3的维度相同 7 8 返回: 9 cost - 计算后的成本 10 11 """ 12 13 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3,labels=Y)) 14 15 return cost
2.6、构建模型
最后,我们已经实现了我们所有的函数,我们现在就可以实现我们的模型了。
我们之前在课程2就实现过random_mini_batches()这个函数,它返回的是一个mini-batches的列表。
在实现这个模型的时候我们要经历以下步骤:
- 创建占位符
- 初始化参数
- 前向传播
- 计算成本
- 反向传播
- 创建优化器
最后,我们将创建一个session来运行模型。
1 def model(X_train, Y_train, X_test, Y_test, learning_rate=0.009, 2 num_epochs=100,minibatch_size=64,print_cost=True,isPlot=True): 3 """ 4 使用TensorFlow实现三层的卷积神经网络 5 CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED 6 7 参数: 8 X_train - 训练数据,维度为(None, 64, 64, 3) 9 Y_train - 训练数据对应的标签,维度为(None, n_y = 6) 10 X_test - 测试数据,维度为(None, 64, 64, 3) 11 Y_test - 训练数据对应的标签,维度为(None, n_y = 6) 12 learning_rate - 学习率 13 num_epochs - 遍历整个数据集的次数 14 minibatch_size - 每个小批量数据块的大小 15 print_cost - 是否打印成本值,每遍历100次整个数据集打印一次 16 isPlot - 是否绘制图谱 17 18 返回: 19 train_accuracy - 实数,训练集的准确度 20 test_accuracy - 实数,测试集的准确度 21 parameters - 学习后的参数 22 """ 23 ops.reset_default_graph() #能够重新运行模型而不覆盖tf变量 24 tf.set_random_seed(1) #确保你的数据和我一样 25 seed = 3 #指定numpy的随机种子 26 (m , n_H0, n_W0, n_C0) = X_train.shape 27 n_y = Y_train.shape[1] 28 costs = [] 29 30 #为当前维度创建占位符 31 X , Y = create_placeholders(n_H0, n_W0, n_C0, n_y) 32 33 #初始化参数 34 parameters = initialize_parameters() 35 36 #前向传播 37 Z3 = forward_propagation(X,parameters) 38 39 #计算成本 40 cost = compute_cost(Z3,Y) 41 42 #反向传播,由于框架已经实现了反向传播,我们只需要选择一个优化器就行了 43 optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) 44 45 #全局初始化所有变量 46 init = tf.global_variables_initializer() 47 48 #开始运行 49 with tf.Session() as sess: 50 #初始化参数 51 sess.run(init) 52 #开始遍历数据集 53 for epoch in range(num_epochs): 54 minibatch_cost = 0 55 num_minibatches = int(m / minibatch_size) #获取数据块的数量 56 seed = seed + 1 57 minibatches = cnn_utils.random_mini_batches(X_train,Y_train,minibatch_size,seed) 58 59 #对每个数据块进行处理 60 for minibatch in minibatches: 61 #选择一个数据块 62 (minibatch_X,minibatch_Y) = minibatch 63 #最小化这个数据块的成本 64 _ , temp_cost = sess.run([optimizer,cost],feed_dict={X:minibatch_X, Y:minibatch_Y}) 65 66 #累加数据块的成本值 67 minibatch_cost += temp_cost / num_minibatches 68 69 #是否打印成本 70 if print_cost: 71 #每5代打印一次 72 if epoch % 5 == 0: 73 print("当前是第 " + str(epoch) + " 代,成本值为:" + str(minibatch_cost)) 74 75 #记录成本 76 if epoch % 1 == 0: 77 costs.append(minibatch_cost) 78 79 #数据处理完毕,绘制成本曲线 80 if isPlot: 81 plt.plot(np.squeeze(costs)) 82 plt.ylabel('cost') 83 plt.xlabel('iterations (per tens)') 84 plt.title("Learning rate =" + str(learning_rate)) 85 plt.show() 86 87 #开始预测数据 88 ## 计算当前的预测情况 89 predict_op = tf.arg_max(Z3,1) 90 corrent_prediction = tf.equal(predict_op , tf.arg_max(Y,1)) 91 92 ##计算准确度 93 accuracy = tf.reduce_mean(tf.cast(corrent_prediction,"float")) 94 print("corrent_prediction accuracy= " + str(accuracy)) 95 96 train_accuracy = accuracy.eval({X: X_train, Y: Y_train}) 97 test_accuary = accuracy.eval({X: X_test, Y: Y_test}) 98 99 print("训练集准确度:" + str(train_accuracy)) 100 print("测试集准确度:" + str(test_accuary)) 101 102 return (train_accuracy,test_accuary,parameters)
然后我们启动模型:
1 _, _, parameters = model(X_train, Y_train, X_test, Y_test,num_epochs=150)
2.7、预测
之后我们利用自己的照片测试一下效果如何:
1 my_image1 = "test.png" #定义图片名称 2 fileName1 = "datasets/" + my_image1 #图片地址 3 image1 = mpimg.imread(fileName1) #读取图片 4 plt.imshow(image1) #显示图片 5 my_image1 = image1.reshape(1,64 * 64 * 3).T #重构图片 6 my_image_prediction = cnn_utils.predict(my_image1, parameters) #开始预测 7 print("预测结果: y = " + str(np.squeeze(my_image_prediction)))

以上就是本次作业的全部内容,本次是对卷积神经网络的初次探索,利用原生代码实现还是比较复杂的,tensflow框架用起来很简单,但是还是不太熟练,很多函数需要多练习。