课时二 单变量线性回归
课时二介绍了线性回归算法的概述以及监督学习的完整过程。
1、模型表示
我们在学习时会用几个固定的符号来表示某一含义,具体表示如下:

监督学习的工作方式:
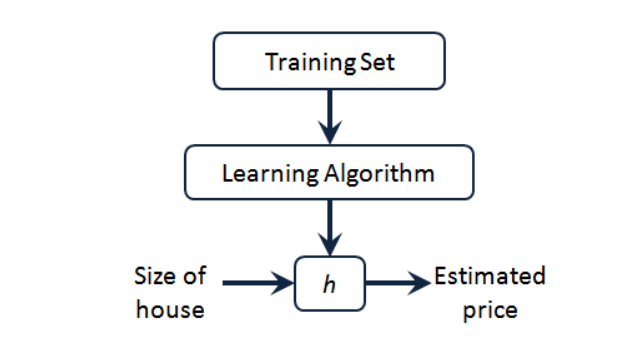
监督学习的完整工作流程如上图所示,首先我们要准备训练集,然后我们把训练集输入学习方法,学习方法工作之后会输出一个函数,这个函数我们用h表示,也叫作假设函数,h函数是x到y的函数映射。我们向假设函数h中输入特征x可以得到对应的目标特征y。
那么h函数是一个什么样的函数呢?有一种可能的表达方式为 ,因为只含有一个输入变量,所以这样的问题叫做单变量线性回归问题,具体的问题案例有房价预测问题,具体问题内容可看视频。
,因为只含有一个输入变量,所以这样的问题叫做单变量线性回归问题,具体的问题案例有房价预测问题,具体问题内容可看视频。
2、代价函数
在上面我们已经得到了假设函数也就是用来预测的函数,接下来就是确定合适参数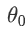 和
和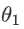 ,我们选择的参数会影响我们得到的函数直线相对于训练集的准确程度,模型所预测的值和实际值之间的差距就是建模误差,(下图中蓝线所指的差距)
,我们选择的参数会影响我们得到的函数直线相对于训练集的准确程度,模型所预测的值和实际值之间的差距就是建模误差,(下图中蓝线所指的差距)
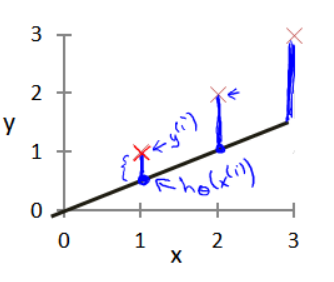
我们的目标是选择出可以使建模误差的平方和能够最小的参数。定义代价函数为:
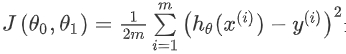
分母那个求和式子是所有样本建模误差的平方和,除以m是把误差平均到每个样本,再除以2是为了后续求导后方便数学计算。
代价函数又叫做平方误差函数,之所以选择这个形式是因为平方误差函数对于大多数问题,特别是回归问题,都是一个合理的选择,也有其他代价函数,但是平方误差函数可能是解决回归问题最常用的手段。(本段笔记来自吴恩达老师的2014机器学习课程笔记,具体为什么我也不太理解,只是记住了这里)

上图包括我们已经确定的假设函数,所需的参数,代价函数,我们的目标是找到合适的参数使得代价函数值最小,然后老师介绍了一种算法,用于自动找出合适的参数,该算法就是梯度下降算法。
3、梯度下降
梯度下降算法是一个用来求函数最小值的算法,我们使用它来求代价函数的最小值。梯度下降的思想是:开始我们随机选择一个参数组合 计算代价函数,然后寻找下一个能让代价函数下降最多的参数组合,持续这一过程直到找到一个局部最小值。(梯度下降算法求得是局部最小值,不确定是否为全局最小值)
计算代价函数,然后寻找下一个能让代价函数下降最多的参数组合,持续这一过程直到找到一个局部最小值。(梯度下降算法求得是局部最小值,不确定是否为全局最小值)
批量梯度下降算法的公式为:
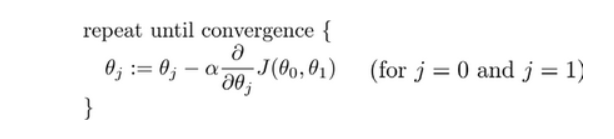
其中∂是学习率,决定了代价函数沿着下降程度最大的方向下降的步子有多大,在批量下降中,我们每次都同时让所有参数减去学习率诚意代价函数的导数,具体过程如下:

梯度下降算法要重点理解的一点是算法是同时更新 。
。
现在解释一下算法中各个符号的意义,首先是学习率,学习率 如果太小的话,会导致步子迈的太小,所以会很慢到达最低点,如果学习率太大的话,我们就可能一次次地越过最低点,从而导致函数无法收敛,甚至是发散。
然后就是后面的导数,导数的意义是函数的切线斜率
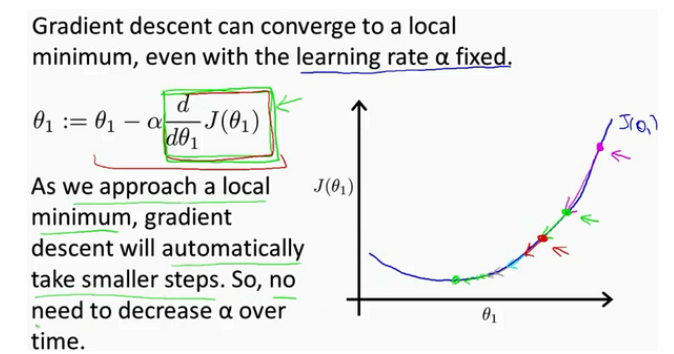
在上图中假设初始参数在紫色箭头处,这个位置函数切线斜率为正数,所以导数就是正数,因为∂小于1,所以更新之后的参数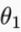 就会向坐标左边移一点,以此类推直到参数移到了最低点,此时最低点的切线斜率是0,所以参数值不变,此时就找到了代价函数的最小值,也确定了参数,这就是梯度下降算法的原理,当然参数最开始初始在任何地方都可以,都能推导出来。这里解释时简化了参数个数,当有多个参数时推导过程一样,只不过是函数图像变化了,但是原理不变。
就会向坐标左边移一点,以此类推直到参数移到了最低点,此时最低点的切线斜率是0,所以参数值不变,此时就找到了代价函数的最小值,也确定了参数,这就是梯度下降算法的原理,当然参数最开始初始在任何地方都可以,都能推导出来。这里解释时简化了参数个数,当有多个参数时推导过程一样,只不过是函数图像变化了,但是原理不变。
4、梯度下降的线性回归
既然已经找到了合适的算法,现在就可以把算法应用到我们的模型中了,将梯度下降算法应用于具体的拟合直线的线性回归算法。

上图是原笔记截图,过程我做了一遍,求偏导时也求了一遍,所以这种数学公式的推导过程一定要亲手做一遍,这样才会理解。最后算法改写成有关两个参数的形式,通过梯度下降算法最终确定参数,得到模型。
以上就是我学的第一个机器学习算法的知识点,总的来说还是比较简单的,过程全都跟下来的话学习来并不困难,用到的数学知识还是比较简单的求偏导等等。学习机器学习的路还很长,这只是第一步,接下来继续努力。
以上就是课时二的内容,部分笔记来自“机器学习初学者”网站提供的吴恩达老师的2014机器学习课程笔记http://www.ai-start.com/