字符串类型(str)
-
字符串说明
-
索引和切片
-
转义字符
-
字符串运算符
-
字符串格式化
-
字符串内置的函数
一.字符串说明
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。
字符串是不可变的数据类型,不论执行任何操作,源字符串是不会改变的,每次操作都会返回新字符串;
创建字符串,只需要为变量赋值即可,如:Str = "hello world"
字符串在转换成int时,如果字符串中的数字有空格,则在转换时自动去除空格;
访问字符串中的值:
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
>>> print("hello world") hello world
字符串更新:
可以截取字符串的一部分并与其他字段拼接,如下实例:
>>> print("hello world" + " 你好,中国") hello world 你好,中国
二、索引和切片
1.索引
说明:通过索引取出字符串对应的值
格式:str[下标]
参数:下标 ------ > 是一个int型数据,
索引从0开始,使用[下标]可以获取到每一个字符,还可以倒着数,最后一个字符用-1表示,一次往前数是-1、-2...
返回值:返回字符串对应索引所对应的值;如果索引超出边界则报错
实例:
>>> s = "abcdefg" >>> print(s[0]) a >>> print(s[1]) b >>> print(s[2]) c >>> print(s[3]) d >>> print(s[4]) e >>> print(s[5]) f >>> print(s[6]) g
----------------索引超出边界,报错---------------------------------
>>> print(s[7])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
2.切片
说明:通过切片取出字符串的一段字符;
格式:str[起始位置:结束位置:步长]
参数:起始位置 --------> 表示从哪个下标开始
结束位置 --------> 表示到哪个下标结束
步长 --------------> 默认从左到右,步长为1,也可以取反,表示倒叙,步长取负数
特点:顾头不顾尾,从start开始截取. 截取到end位置. 但不包括end
返回值:返回一个由切片选择好的子串;
实例:
>>> s = "abcdefg" >>> print(s[:]) abcdefg >>> print(s[0:4]) abcd >>> print(s[2:6]) cdef >>> print(s[:6:2]) ace >>> print(s[1::2]) bdf >>> print(s[::-1]) gfedcba >>> print(s[-1:-3]) >>> print(s[-1:-3:-1]) gf >>> print(s[-1::-2]) geca
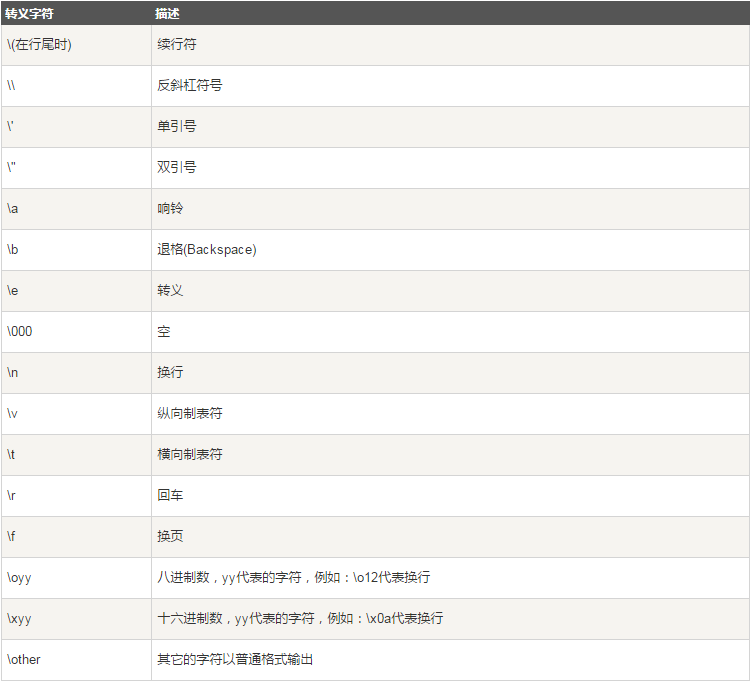
三.转义字符
在需要在字符中使用特殊字符时,python用反斜杠()转义字符。如下表:
四.字符串运算符
下表实例变量a值为字符串 "Hello",b变量值为 "Python":

五.字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
>>> print("中国的首都是%s" % ("北京")) 中国的首都是北京
python字符串格式化符号:
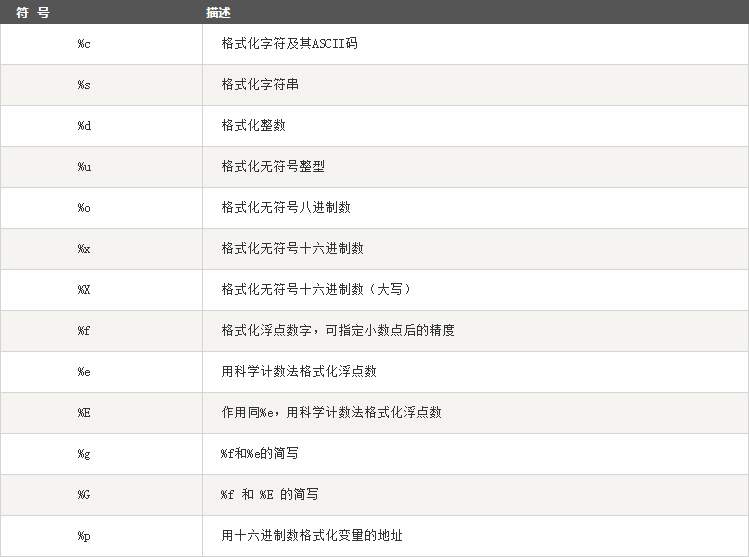
格式化操作符辅助指令:
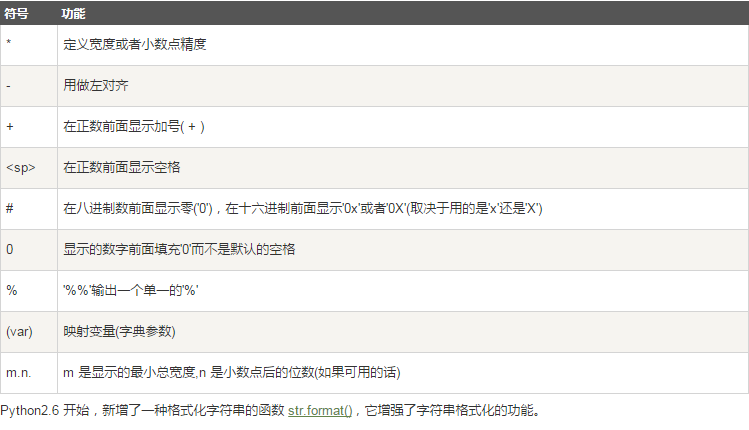
六.字符串内置的函数

1.capitalize(self)
说明:将字符串的第一个字符转换为大写,其他字母变成小写;注意的是并不会改变原字符串内容;
语法:str.capitalize()
返回值:该方法返回一个首字母大写的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.capitalize()) Hello world
2.casefold(self)
说明:将字符串中的所有大写字符转换为小写字符;并支持识别东欧的一些字母;lower不支持东欧的字母;
语法:str.casefold()
返回值:返回将字符串中所有大写字符转换为小写后生成的字符串;
实例:
>>> S = "hello WoRld" >>> print(S.casefold()) hello world
3.center(self, width, fillchar=None)
说明:返回一个指定的宽度width且居中的字符串,字符串长度为width,fillchar为填充的字符,默认为空格;
语法:str.center(width,fillchar)
返回值:返回一个指定的宽度 width 居中的字符串,如果 width 小于字符串宽度直接返回字符串,否则使用 fillchar 去填充。
实例:
>>> print("今日头条".center(40,"*")) ******************今日头条******************
4.count(self, sub, start=None, end=None)
说明:用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法:str.count(sub,start=None, end=None)
参数:sub -----> 要搜索的子字符串;
start -----> 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0;
end ------> 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置;
返回值:返回子字符串在字符串中出现的次数;
实例:
>>> print(ss.count("a")) 2 >>> print(ss.count("a",0,8)) 1
5.encode(self, encoding='utf-8', errors='strict')
说明:以指定的编码格式来编码字符串。errors参数可以指定不同的错误处理方案。
语法:str.encode(encoding='utf-8', errors='strict')
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回编码后的字符串,是一个 bytes 对象
实例:
>>> abc = "灯火阑珊" >>> abc_utf8 = abc.encode("UTF-8") >>> abc_gbk = abc.encode("GBK") >>> print(abc) 灯火阑珊 >>> print(abc_utf8) b'xe7x81xafxe7x81xabxe9x98x91xe7x8fx8a' >>> print(abc_gbk) b'xb5xc6xbbxf0xc0xbbxc9xba'
6.decode(self, decoding='utf-8', errors='strict')
说明:以指定的编码格式来解码字符串。errors参数可以指定不同的错误处理方案。
语法:bytes.decode(encoding="utf-8", errors="strict")
参数:encoding -----> 要使用的编码,如:UTF-8
errors -----> 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值:返回解码后的字符串;
实例:
>>> print(abc_gbk.decode("GBK")) 灯火阑珊 >>> print(abc_utf8.decode("UTF-8")) 灯火阑珊
7.endswith(self, suffix, start=None, end=None)
说明:用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False;
语法:str.endswith(suffix,start=None, end=None)
参数:suffix -----> 该参数可以是一个字符串或者是一个元素;
start ------> 字符串中的开始位置;
end ------> 字符中结束位置
返回值:如果字符串含有指定的后缀返回True,否则返回False;
实例:
>>> end = "hello world" >>> print(end.endswith("ld")) True >>> print(end.endswith("ld",0,10)) False
8.expandtabs(self, tabsize=8)
说明:把字符串中的 tab 符号(' ')转为空格,tab 符号(' ')默认的空格数是 8;
注意:规则是这样的,如果设置空格数是8,则会从开头查询,每8个字符为一组,到有 那组时,缺几个就补几个空格;
语法:str.expandtabs(tabsize=8)
参数:tabszie -----> 指定转换字符串中的 tab 符号(' ')转为空格的字符数;
返回值:返回字符串中的 tab 符号(' ')转为空格后生成的新字符串;
实例:
>>> ss = "this is string example" >>> print(ss) this is string example
#this is 刚好8个,所以到 这里自动在补8个空格;
>>> print(ss.expandtabs(0))
this is string example
#0自动没有
>>> print(ss.expandtabs(20))
this is string example
#this is 是8个,设置的是20空格,所以还需在补12个空格
9.find(self, sub, start=None, end=None)
说明:检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
语法:str.find(sub, start=None, end=None)
参数:sub ------> 指定检索的字符串;
start -----> 指定开始索引位置,默认为0
end -----> 指定结束索引位置,默认为字符串长度,len(str)
返回值:如果包含子字符串返回开始的索引值,否则返回-1;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.find("short")) 12 >>> print(str1.find("short",5,19)) 12
>>> print(str1.find("short",17,19))
-1
10.format(self, *args, **kwargs)
说明:format函数用于字符串的格式化,通过{}和:来代替%;传入的参数两种形式,一种是位置参数,一种是关键字参数;位置参数不受顺序约束,且可以为{},只要format里有相对应的参数值即可,参数索引从0开,传入位置参数列表可用*列表,关键字参数值要对得上,可用字典当关键字参数传入值,字典前加**即可,注意的是当位置参数和关键字参数混合使用时,位置参数一定要在关键字参数左边。
语法:str.format( *args, **kwargs)
参数:*args ------> 当传入的参数为列表时,可用*列表;
**kwargs -------> 可用字典当关键字参数传入值,字典前加**即可;
返回值:返回一个已经填充好的字符串。
例子:
------------------不设置指定位置,按默认顺序-------------------------- >>> str2 = "中国的城市有,{},{},{},{}" >>> print(str2.format("北京","上海","深圳","武安")) 中国的城市有,北京,上海,深圳,武安 ----------------设置指定位置------------------------------------------- >>> str2 = "中国的城市有,{3},{0},{2},{1}" >>> print(str2.format("北京","上海","深圳","武安")) 中国的城市有,武安,北京,深圳,上海 ------------------使用位置-列表形式--------------------------- >>> li = ["北京","上海","深圳","武安"] >>> print(str2.format(*li)) 中国的城市有,北京,上海,深圳,武安
-------------------使用关键字位置形式-------------------------
>>> print(str2.format(k2="北京",k3="上海",k1="深圳",k4="武安"}))
中国的城市有,深圳,北京,上海,武安
-------------------使用关键字位置字典形式------------------------- >>> print(str2.format(**{"k2":"北京","k3":"上海","k1":"深圳","k4":"武安"})) 中国的城市有,深圳,北京,上海,武安 -------------------使用混合模式-------------------------------- >>> str2 = "中国的城市有,{3},{0},{2},{1},{h}" >>> print(str2.format("北京","上海","深圳","武安",**{"h":"石家庄"})) 中国的城市有,武安,北京,深圳,上海,石家庄
也可以向.format()传入对象:
class test(): def __init__(self,asd): self.num = asd ming = test(6) print("ming的数字是:{0.num}".format(ming)) #{0.num}中的0是可选的表示指定位置 -------------------输出结果为------------------------------ ming的数字是:6
.format()的数字格式化:
>>> print("{:.2f}".format(3.1415926)) 3.14
下表展示了 str.format() 格式化数字的多种方法:

>>> print("{}对应的位置是{{0}}".format("zjk")) zjk对应的位置是{0}
11.format_map(self, mapping)
说明:类似于format,不同的是format_map只能使用关键字位置形式传入字典来进行;
语法:str.format_map(mapping)
参数:mapping -----> 必须是一个字典;
返回值:一个已经填充好的字符串;
实例:
>>> print("{name}对应的位置是{{0}}".format_map({"name":"zjk"})) zjk对应的位置是{0}
12.index(self, sub, start=None, end=None)
说明:检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果sub不在 str中则会报一个异常,而find则是返回-1;
语法:str.index(sub,start=None, end=None)
参数:sub ------> 指定检索的子字符串;
start -----> 指定开始索引位置,默认为0;
end ------> 指定结束索引位置,默认为字符串的长度;
返回值:如果包含子字符串返回开始的索引值,否则抛出异常;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.index("short")) 12 >>> print(str1.index("short",14)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
13.isalnum(self)
说明:检测字符串是否由字母和数字组成;
语法:str.isalnum()
返回值:如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
实例:
>>> str1 = "helloworld" >>> print(str1.isalnum()) True >>> str2 = "hello world" >>> print(str2.isalnum()) False
14.isalpha(self)
说明:检测字符串是否只由字母组成;
语法:str.isalpha()
返回值:如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False;
实例:
>>> str1 = "python" >>> print(str1.isalpha()) True >>> str2 = "python3" >>> print(str2.isalpha()) False
15.isdecimal(self)
说明:检查字符串是否只包含十进制字符。这种方法只存在于unicode对象;注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可。
语法:str.isdecimal()
返回值:如果字符串只包含十进制字符返回True,否则返回False
实例:
>>> str1 = u"zjk2018" >>> print(str1.isdecimal()) False >>> str2 = u"201807" >>> print(str2.isdecimal()) True
16.isdigit(self)
说明:检测字符串是否只由数字组成;
语法:str.isdigit()
返回值:如果字符串只包含数字则返回 True 否则返回 False;
实例:
>>> str1 = "zjk2018" >>> print(str1.isdigit()) False >>> str2 = "201807" >>> print(str2.isdigit()) True
17.isidentifier(self)
说明:判断是否为python中的标识符,也就是说是否符合python变量名语法;
语法:str.isidentifier()
返回值:如果字符串的内容符合python变量命名语法,则返回True,否则返回False;
实例:
>>> str1 = "zjk1" True >>> str2 = "666zjk" >>> str2.isidentifier() False >>> str3 = "变量名" >>> str3.isidentifier() True >>> str4 = "def" >>> str4.isidentifier() True
#python的关键字一样是合法的 >>> str5 = "88888" >>> str5.isidentifier() False
18.islower(self)
说明:检测字符串是否由小写字母组成;
语法:str.islower()
返回值:如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False;
实例:
>>> str1 = "Life is too short for python -zjk23" >>> print(str1.islower()) False >>> str2 = "life is too short for python -zjk23" >>> print(str2.islower()) True
19.isnumeric(self)
说明:检测字符串是否只由数字组成。这种方法是只针对unicode对象;注:定义一个字符串为Unicode,只需要在字符串前添加 'u' 前缀即可;
语法:str.isnumeric()
返回值:如果字符串中只包含数字字符,则返回 True,否则返回 False
实例:
>>> str1 = "zjk1995" >>> print(str1.isnumeric()) False >>> str2 = "1995" >>> print(str2.isnumeric()) True
20.isprintable(self)
说明:判断是否由可打印字符组成,回车符等一些特殊字符是不会打印显示在屏幕上的;
语法:str.isprintable()
返回值:如果字符串中所有内容都可打印则返回True,否则返回False;
实例:
>>> print("123 4 56".isprintable()) False >>> print("123\t456".isprintable()) True
21.isspace(self)
说明:检测字符串是否只由空白字符组成;
语法:str.isspace()
返回值:如果字符串中只包含空格,则返回 True,否则返回 False;
实例:
>>> str1 = " " >>> print(str1.isspace()) True >>> str2 = " sdf sdf" >>> print(str2.isspace()) False
22.istitle(self)
说明:检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写;
语法:str.istitle()
返回值:如果字符串中所有的单词拼写首字母是否为大写,且其他字母为小写则返回 True,否则返回 False;
实例:
>>> str1 = "Life Is Too Short For Python" >>> print(str1.istitle()) True >>> str2 = "Life is Too short For PyThon" >>> print(str2.istitle()) False
23.isupper(self)
说明:检测字符串中所有的字母是否都为大写;
语法:str.isupper()
返回值:如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False;
实例:
>>> str1 = "LIFE IS TOO SHORT FOR PYTHON" >>> print(str1.isupper()) True >>> str2 = "LIFE Is TOO ShOrT FOR PYTHON" >>> print(str2.isupper()) False
24.join(self, iterable)
说明:用于将序列中的元素以指定的字符连接生成一个新的字符串;
语法:n.join(iterable)
参数:iterable ------> 要连接的元素序列;
n --------------> 指定用来连接的字符;
返回值:返回通过指定字符连接序列中元素后生成的新字符串;
实例:
>>> str1 = "zjk" >>> print("-".join(str1)) z-j-k
25.ljust(self, width, fillchar=None)
说明:返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串;
语法:str.ljust(width, fillchar=None)
参数:width ------> 指定字符串长度;
fillchar -----> 填充字符,默认为空格;
返回值:返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.ljust(20,"*")) I Love You********** ------------当指定的填充长度小于原字符串长度时返回原字符串------- >>> str2 = "I Love You" >>> print(str1.ljust(10,"*")) I Love You
26.lower(self)
说明:转换字符串中所有大写字符为小写;
语法:str.lower()
返回值:返回将字符串中所有大写字符转换为小写后生成的字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.lower()) i love you
27.lstrip(self, chars=None)
说明:用于截掉字符串左边的空格或指定字符,贪婪模式;
语法:str.lstrip( chars=None)
参数:chars ------> 指定截取的字符;
返回值:返回截掉字符串左边的空格或指定字符后生成的新字符串;
实例:
>>> str1 = "666666I66Love You" >>> print(str1.lstrip("6")) I66Love You
28.maketrans(self, *args, **kwargs)
说明:用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。两个字符串的长度必须相同,为一一对应的关系;
语法:str.maketrans(intab,outtab)
参数:intab -------> 需要转换的字符串;
outtab -----> 被转换的字符串;
返回值:返回的是一个字典,字典内容是字符串的ASCII码的序号,一一对应
实例:
>>> dat = str.maketrans("123","abc") >>> print(dat) {49: 97, 50: 98, 51: 99} -----------------解释-------------------------- 1 的ASCII码为 49 a 的ASCII码为 97
29.partition(self, sep)
说明:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
语法:str.partition(sep)
参数:sep ------> 指定分隔符
返回值:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
实例:
>>> str1 = "http://www.dhlanshan.cn" >>> print(str1.partition("//")) ('http:', '//', 'www.dhlanshan.cn') -----------如果指定的分隔符在字符串中有两个,则以最左侧为分隔符---------- >>> print(str1.partition(".")) ('http://www', '.', 'dhlanshan.cn')
30.replace(self, old, new, count=None)
说明:将字符串中的某子串进行替换,默认替换指定的所有子串;
语法:str.replace(old, new, count=None)
参数:old ------> 旧的子串;
new -----> 新的子串;
count ----> 替换的次数;
返回值:返回一个子串替换好之后的新的字符串;
实例:
------------------替换所有子串---------------------------- >>> str1 = "http://video.dhlanshan.cn" >>> print(str1.replace("a","A")) http://video.dhlAnshAn.cn -----------------从左到右只替换1次子串------------------ >>> print(str1.replace("a","A",1)) http://video.dhlAnshan.cn
31.rfind(self, sub, start=None, end=None)
说明:返回指定的子串在字符串中最后一次出现的位置,如果没有匹配项则返回-1;也可以说是从右边开始找这个指定的子串;
语法:str.rfind(sub, start=None, end=None)
参数:sub ------> 指定的子串;
start ------> 开始查找的位置,默认为0;
end ------> 结束查找位置,默认为字符串的长度;
返回值:返回字符串最后一次出现的位置,如果没有匹配项则返回-1
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rfind("an")) 20 >>> print(str1.rfind("an",21)) -1
32.rindex(self, sub, start=None, end=None)
说明:返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,和rfind类似,只不过rfind找不到会返回-1;也可以说是从右边开始找这个指定的子串;
语法:str.rindex(sub, start=None, end=None)
参数:sub ------> 指定的子串;
start ------> 开始查找的位置,默认为0;
end ------> 结束查找位置,默认为字符串的长度;
返回值:返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rindex("an")) 20 ---------------找不到则报错-------------------------- >>> print(str1.rindex("an",21)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
33.rjust(self, width, fillchar=None)
说明:返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
语法:str.rjust(width, fillchar=None)
参数:width ------> 指定填充指定字符后中字符串的总长度;
fillchar -----> 填充的字符,默认为空格;
返回值:返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rjust(30,"-")) -----http://video.dhlanshan.cn
34.rpartition(self, sep)
说明:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串,分隔符从字符串的右边开始查找。
语法:str.rpartition(sep)
参数:sep ----->指定分隔符;
返回值:返回一个由三个元素组成的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.rpartition(".")) ('http://video.dhlanshan', '.', 'cn')
35.rsplit(self, sep=None, maxsplit=-1)
说明:分隔字符串,从右侧开始分隔,返回一个将字符串以指定分隔符分隔的列表,从右边开始查找分隔符,默认空格为分隔符;注意,最后列表里是不存在指定的那个分隔符的;
语法:str.rsplit(sep=None, maxsplit=-1)
参数:sep ------> 指定分隔符;
maxsplit ------> 最多分隔的次数,-1表示全部分隔;
返回值:返回一个将字符串以指定分隔符分隔的列表;
实例:
--------------------分隔所有-------------------------------------- >>> str1 = "1 2 3 4 5" >>> print(str1.rsplit(" ",maxsplit=-1)) ['1', '2', '3', '4', '5'] -------------------分隔2次--------------------------------------- >>> print(str1.rsplit(" ",maxsplit=2)) ['1 2 3', '4', '5'] --------------------列表中会删除指定的分隔符----------------- >>> print(str1.rsplit("3",maxsplit=1)) ['1 2 ', ' 4 5']
36.rstrip(self, chars=None)
说明:删除 string 字符串最右边的指定字符(默认为空格);贪婪模式;
语法:str.rstrip(chars=None)
参数:chars ------> 指定的子符;
返回值:返回删除 string 字符串最右边的指定字符后生成的新字符串;
实例:
>>> str1 = "**********今日说法**************" >>> print(str1.rstrip("*")) **********今日说法
37.split(self, sep=None, maxsplit=-1)
说明:分隔字符串,从左侧开始分隔,返回一个将字符串以指定分隔符分隔的列表,从左边开始查找分隔符,默认空格为分隔符;注意,最后列表里是不存在指定的那个分隔符的;
语法:str.rsplit(sep=None, maxsplit=-1)
参数:sep ------> 指定分隔符;
maxsplit ------> 最多分隔的次数,-1表示全部分隔;
返回值:返回一个将字符串以指定分隔符分隔的列表;
实例:
--------------------分隔所有-------------------------------------- >>> str1 = "1 2 3 4 5" >>> print(str1.split(" ",maxsplit=-1)) ['1', '2', '3', '4', '5']
-------------------当分隔符为整个字符串时则返回一个有两个空字符串的元素的列表----------------------
>>> str1 = "1 2 3 4 5"
>>> print(str1.split("1 2 3 4 5",maxsplit=-1))
['', '']
-------------------分隔2次--------------------------------------- >>> print(str1.split(" ",maxsplit=2)) ['1','2','3 4 5'] --------------------列表中会删除指定的分隔符----------------- >>> print(str1.split("3",maxsplit=1)) ['1 2 ', ' 4 5']
38.splitlines(self, keepends=None)
说明:按照行(' ', ' ', ')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
语法:str.splitlines(keepends=None)
参数:keepends -- 在输出结果里是否去掉换行符(' ', ' ', '),默认为 False,不包含换行符,如果为 True,则保留换行符
返回值:返回一个包含各行作为元素的列表。
实例:
>>> print("abc defg kl ".splitlines()) ['abc', '', 'defg', 'kl'] >>> print("abc defg kl ".splitlines(True)) ['abc ', ' ', 'defg ', 'kl ']
39.startswith(self, prefix, start=None, end=None)
说明:用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 start 和 end 指定值,则在指定范围内检查。
语法:str.startswith(prefix, start=None, end=None)
参数:prefix ------> 指定的子串;
start -------> 索引开始处;
end --------> 索引结尾处;
返回值:如果检测到字符串则返回True,否则返回False;
实例:
>>> str1 = "http://video.dhlanshan.cn" >>> print(str1.startswith("http")) True >>> print(str1.startswith("video",7)) True >>> print(str1.startswith(":",6,9)) False
40.strip(self, chars=None)
说明:用于移除字符串头尾指定的字符(默认为空格)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法:str.strip(chars)
参数:chars -------> 移除字符串头尾指定的字符序列;
返回值:返回移除字符串头尾指定的字符序列生成的新字符串;
实例:
>>> str1 = "**********今*日*说*法**************" >>> print(str1.strip("*")) 今*日*说*法
无敌匹配法:
先看效果:
>>> str1 = "12345654321" >>> print(str1.strip("12")) 3456543 >>> str1 = "12345654312" >>> print(str1.strip("12")) 3456543 >>> str1 = "12345654321" >>> print(str1.strip("125")) 3456543 >>> str1 = "1234565431221" >>> print(str1.strip("12")) 3456543 >>> str1 = "1234565432121" >>> print(str1.strip("12")) 3456543 ----------------------------------------说明-------------------------------- #其实“12”是分为了3个匹配符,分别是"1" "2" "12",这三个匹配符会循环去匹配字符串,直到这三个匹配符一个也匹配不上为止。
41.swapcase(self)
说明:用于对字符串的大小写字母进行转换,小写变大写,大写变小写;
语法:str.swaocase()
返回值:返回大小写字母转换后生成的新字符串;
实例:
>>> str1 = "I Love You" >>> print(str1.swapcase()) i lOVE yOU
42.title(self)
说明:返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写;注意,默认是按空格来分单词,也可以是其他特殊字符或数字。
语法:str.title()
返回值:返回"标题化"的字符串,就是说所有单词的首字母都转化为大写。
实例:
>>> str1 = "Life is too short for python" >>> print(str1.title()) Life Is Too Short For Python
使用特殊字符或数字来区分:
>>> str1 = "zjk zjk*zjk&zjk^zjk@,zjk.zjk9zjk8zjk/zjk" >>> print(str1.title()) Zjk Zjk*Zjk&Zjk^Zjk@,Zjk.Zjk9Zjk8Zjk/Zjk
43.translate(self, table)
说明:根据由maketrans函数生成的对照表table完成字符替换;
语法:str.tarnslate(table)
参数:table ---- 对照表,是由maketrans函数生成;
返回值:返回翻译后的字符串;
实例:
>>> table = str.maketrans("zjk","666") >>> str = "zjkqwert" >>> print(str.translate(table)) 666qwert
44.upper(self)
说明:将字符串中的小写字母转为大写字母;
语法:str.upper()
返回值:返回小写字母转为大写字母的字符串;
实例:
>>> str1 = "Life is too short for python" >>> print(str1.upper()) LIFE IS TOO SHORT FOR PYTHON
45.zfill(self, width)
说明:返回指定长度的字符串,原字符串右对齐,前面填充0,若指定长度小于原字符串长度,则返回原字符串;
语法:str.zfill(width)
参数:width -------> 指定字符串的长度。原字符串右对齐,前面填充0;
返回值:返回指定长度的字符串;
实例:
>>> str = "zjkqwert" >>> print(str.zfill(10)) 00zjkqwert >>> print(str.zfill(6)) zjkqwert