本章重点内容:
1、pandas 数据结构介绍
2、基本功能
3、描述性统计的概述与计算
接下来展开详细的说明
1、pandas 数据结构介绍
Series数据
Series是一种一维的数组型对象,它包含了一个值序列,并且包含了数据标签,成为索引(index),
最简单的序列可以仅仅由一个数组形成,如下:

左侧是索引,右侧是数值,如果没有指定索引,默认的是从0到n-1
Series有两个属性,可以访问对象的值和索引,如下:

在创建Series数据的时候,可以直接通过index参数指定索引,如下:
可以通过索引来访问对象的值,如下:
可以对Series数据进行一些数据函数运算,依然会保留索引,如下:
你会发现,Series数据类型,很想Python数据中的字典,所以你可以将字典转换成一个Series数据类型,如下:
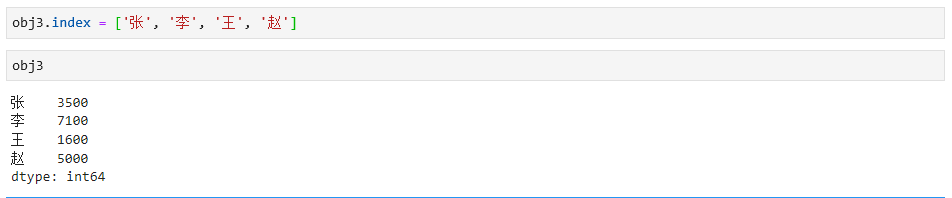
Series的索引可以通过按照位置赋值的方式进行改变,如下:
DataFrame数据类型
DataFrame表示的是矩阵的数据表,它包含已排序的列集合,每一列可以是不同的值类型,DataFrame既有行索引也有列索引,是一个以上的二维块
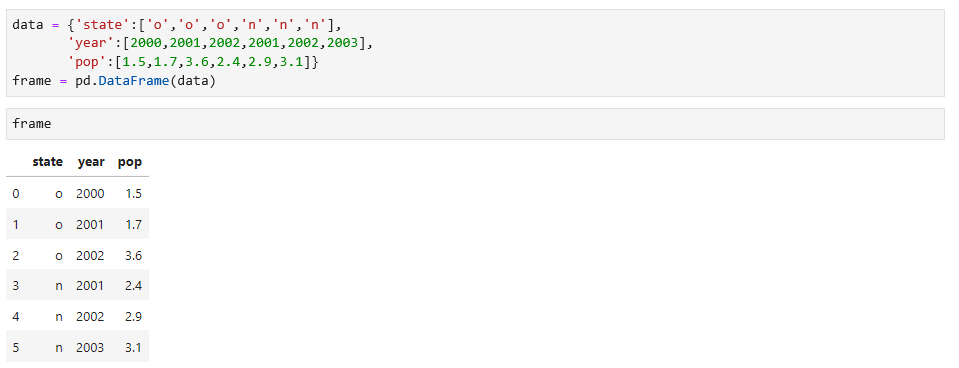
首先,我们创建一个DataFrame数据,可以通过数组的字典来形成,如下:
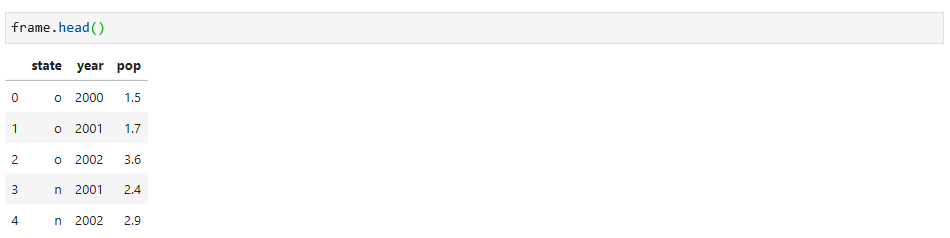
如果你只想选择数据的前五行,可以使用head方法,如下:
你可以指定列的顺序,通过columns参数,如下:

可以选择其中,你需要的列,有两种选择方式,一种是通过字典型标记,一种是通过属性,如下:
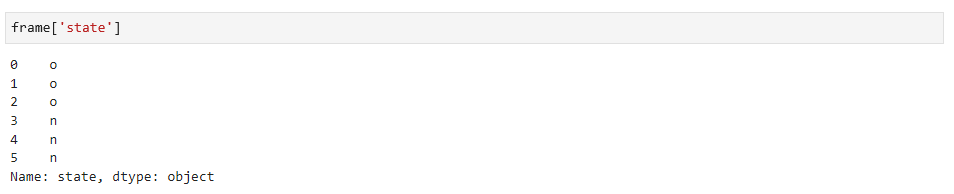
通过字典型标记选择state列:
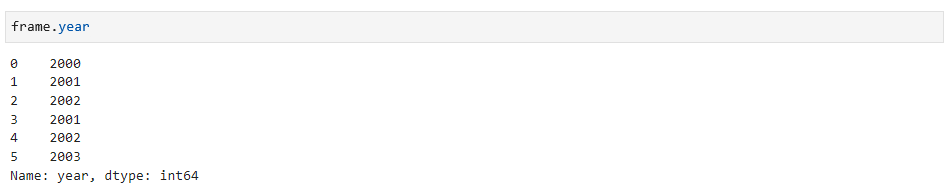
通过属性选择year列:
也可以通过loc属性选择行,如下:

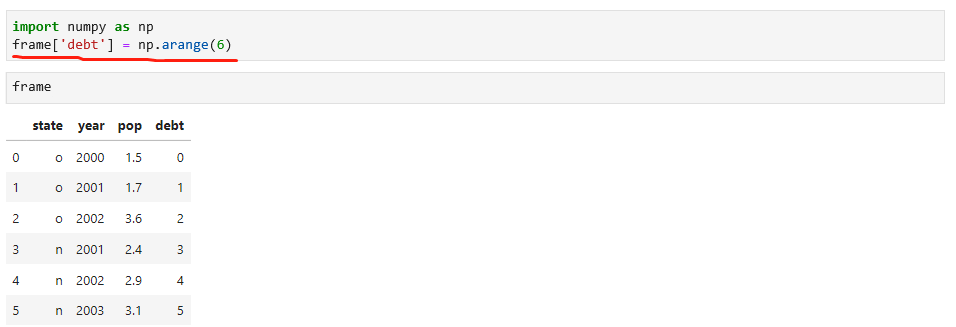
通过赋值一个没有列的名称,同时创建新列,如下:
如果要删除一列,可以通过del关键字删除,如下:

2、基本功能
重建索引
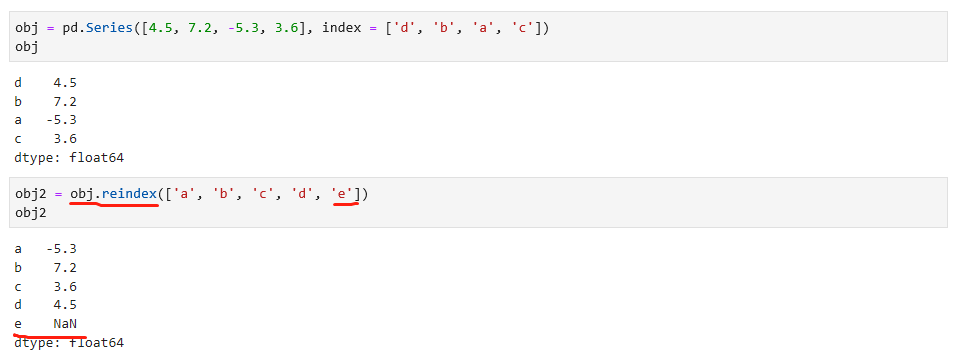
reindex是panda对象的重要方法,如下例子:

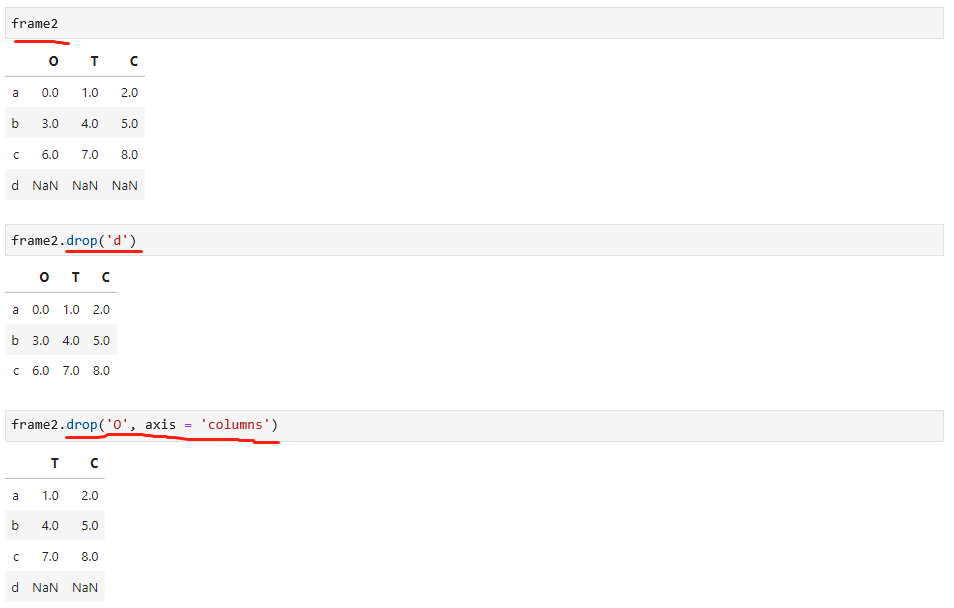
轴向上删除条目
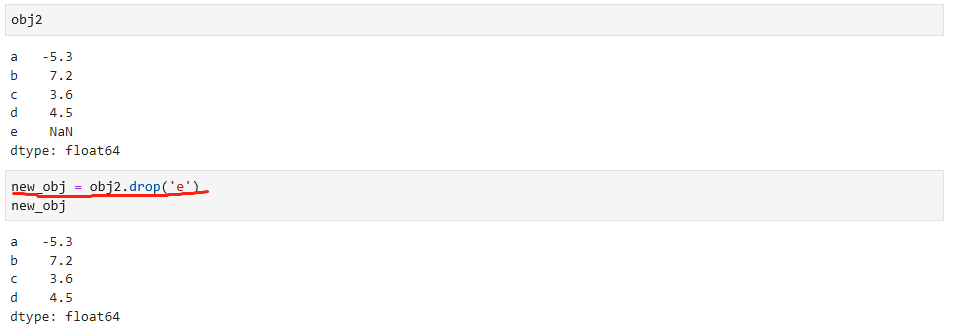
通过drop属性删除条目,如下:
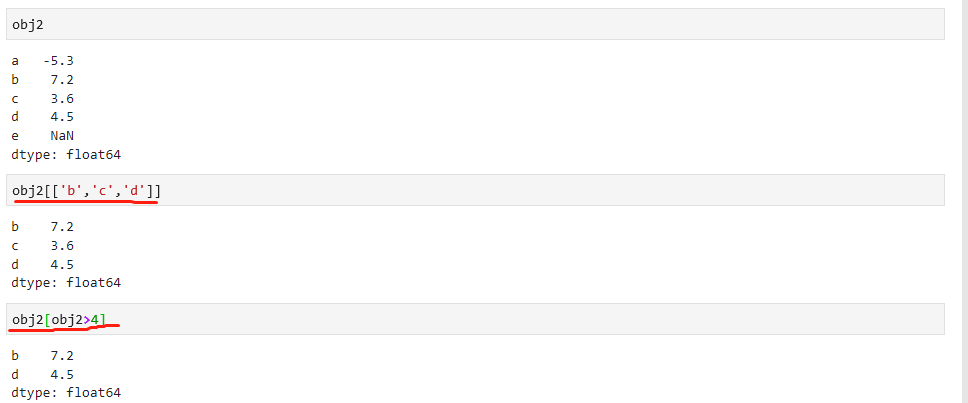
索引、选择、过滤
Series的索引和NumPy数组索引的功能类似,如下:
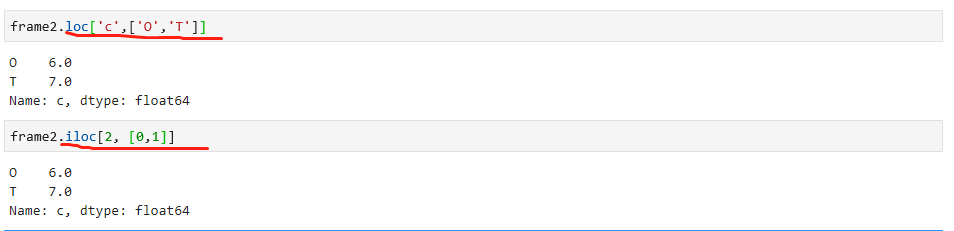
对于DataFrame类型的数据,可以通过loc和iloc属性进行选择,如下:
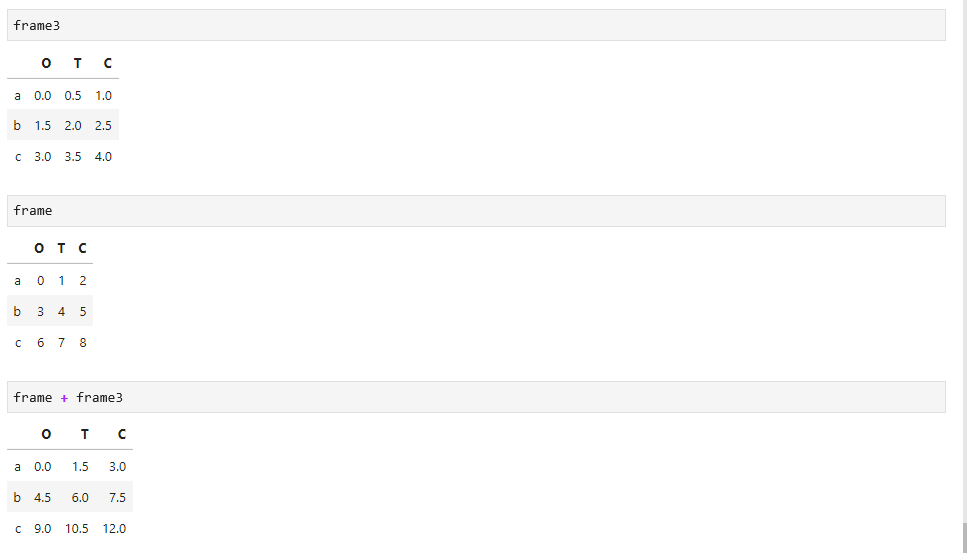
算术和数据对齐
两个同样的DataFrame类型数据,可以进行算术运算,如下:
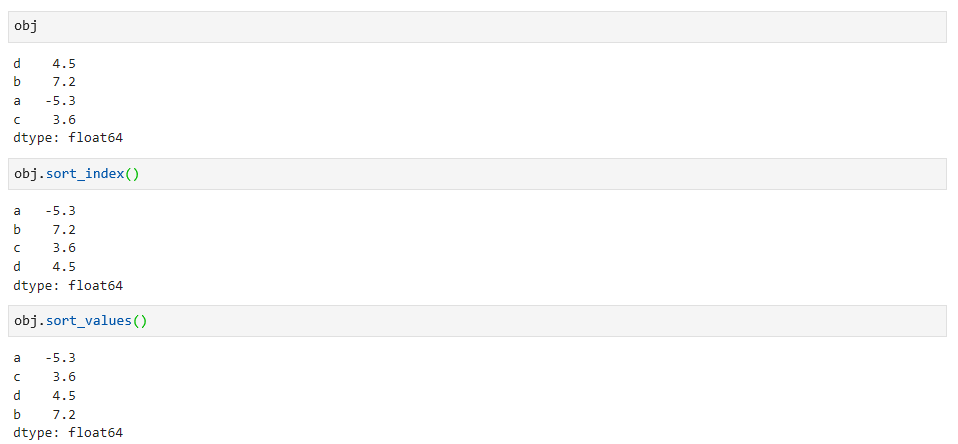
排序和排名
通过sort_index和sort_values方法实现排序,一个是通过索引排序,一个是通过内容排序,如下:
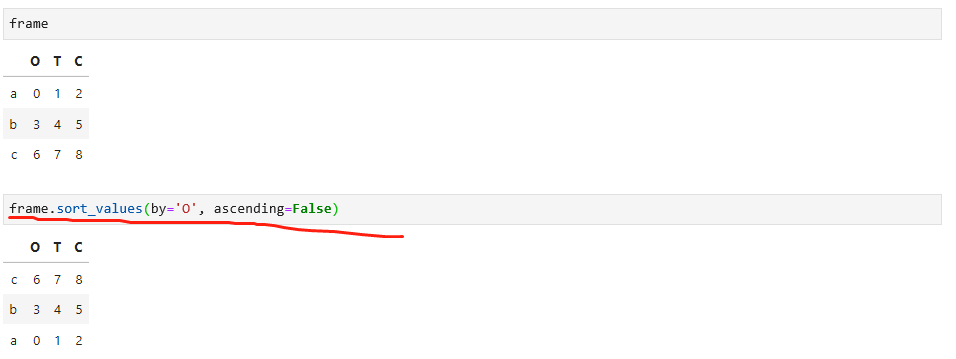
当对DataFrame排序时,可以使用一列或多列作为排序键,这个时候,通过可选参数by,如下:
通过rank函数来实现排名,如下:

3、描述性统计的概述与计算
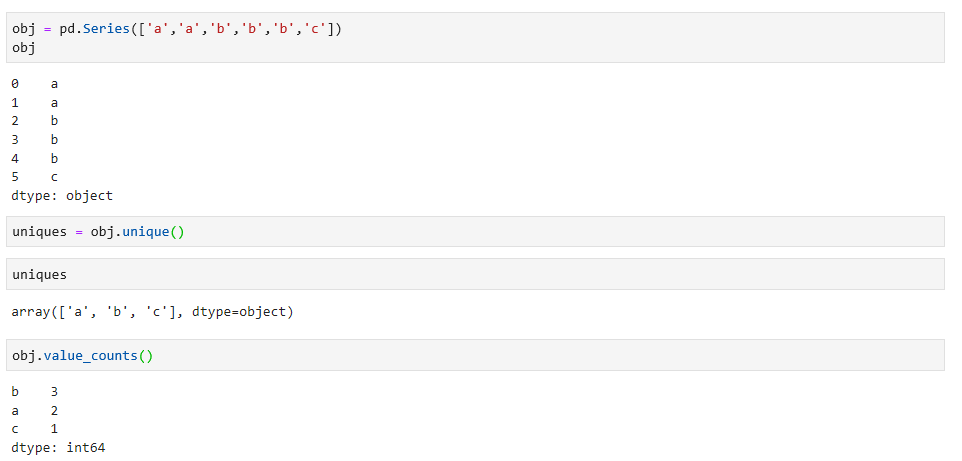
唯一值:unique
计数:counts
具体代码示例如下:
以上,就是本章讲解的重点内容,祝学习愉快!
以下链接,可以供你了解这个系列学习笔记的所有章节最新进度