ZIPKIN
这玩意最坑的就是环境了,所以上来先把环境给它整好了,伺候好了,后面也就舒服了。
(一)环境准备:
1:java环境
yum -y install java
2:npm环境
随同NodeJS一起安装的包管理工具
这个国内目前我知道的只有淘宝有。
alias npm="npm --registry=https://registry.npm.taobao.org --disturl=https://npm.taobao.org/mirrors/node"
3:node环境
版本:V5.5.0
yum install npm -y
git clone https://github.com/creationix/nvm.git /usr/local/nvm
source /usr/local/nvm/install.sh
nvm --version
nvm install v5.5.0
4:准备FQ环境
zipkin从git上git下来后,因为需要FQ才能安装,我们需要对他的配置文件进行如下的修改:
zipkin目录下有这个文件gradle.properties,添加在文件的末尾即可。地址是本机的IP。
systemProp.http.proxyHost=192.168.100.33
systemProp.http.proxyPort=8118
systemProp.https.proxyHost=192.168.100.33
systemProp.https.proxyPort=8118
环境准备到此为止。
(二)架构图:
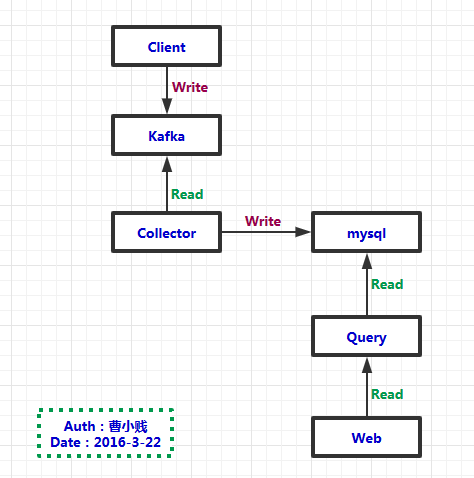
(三)安装部署:
建议不要git最新版本的,有坑。。。我使用的是V1.33.2版本。也可以直接下载下来解压。
# get the zipkin source and change to its directory $ git clone https://github.com/openzipkin/zipkin;cd zipkin # start the query server in a new terminal session or tab $ ./bin/query ##### 数据从DB中查询出来,用给WEB展示# start the collector server in a new terminal session or tab $ ./bin/collector ##### 将数据从kafka中读取出来,并写入到DB中# start the web server in a new terminal session or tab $ ./bin/web ##### 将数据从WEB中展示出来# create dummy traces $ ./bin/tracegen ##### 测试使用,向DB中写入数据,以供测试# open the ui and look at them! $ open http://localhost:8080/
官方提供的数据库因为有问题,我们再此不用,使用mysql代替。
(四)数据库的配置:
yum -y install mysql
添加zipkin用户,定义密码123456。
进入数据库,执行以下操作
SET GLOBAL innodb_file_format=Barracuda
show global variables like 'innodb_file_format'
create database if not exists zipkin
找到zipkin-anormdb/src/main/resources/mysql.sql导入进去,因为文件不大,可以直接复制里面的语句操作。
(五)编写启动脚本:
因为不使用他们自带的数据库cassandra,那么query和collector就不能使用原本的启动文件,再次我们编写他们分别的配置文件
query:
#!/bin/bashMYSQL_DB=zipkin MYSQL_HOST=192.168.100.128 MYSQL_USER=root MYSQL_PASS=123456 MYSQL_TCP_PORT=3306 java -jar/application/zipkin/zipkin-query-service/build/libs/zipkin-query-service-1.33.3-SNAPSHOT-all.jar -f/application/zipkin/zipkin-query-service/config/query-mysql.scala
解析:
数据库名称、地址、用户名、密码、端口、指定运行的java程序和配置文件。
collector:
#!/bin/bashKAFKA_ZOOKEEPER=192.168.100.131:2181,192.168.100.130:2181,192.168.100.132:2181/kafka/q-voerd639 MYSQL_DB=zipkin MYSQL_HOST=192.168.100.128 MYSQL_USER=root MYSQL_PASS=123456 MYSQL_TCP_PORT=3306 java -jar/application/zipkin/zipkin-collector-service/build/libs/zipkin-collector-service-1.33.3-SNAPSHOT-all.jar -f/application/zipkin/zipkin-collector-service/config/collector-mysql.scala
解析:
1:kafka的管理是使用zookeeper来管理的
2:ZooKeeper的连接(kafka在ZK中注册的地址)、数据库名称、地址、用户名、密码、端口、指定运行的java程序和配置文件。
检查测试:
1:检查zipkin的服务是否正常启动,可以简单的通过访问本机的8080端口,能访问即可。
2:因为之前执行了./bin/tracegen,向数据库中写入测试数据,去数据库的zipkin数据库中查看是否有数据
3:在网页上选择要看的项目后,点击Find Traces查看
http://www.cnblogs.com/caoxiaojian/p/5309745.html