摘要: 今天在生产环境发生了数据库进程卡死的现象,除了sql因为全量更新,没加索引的原因,最主要还是我们的接口的服务器端接口出现问题了。忽视了更新接口的幂等性,以及调用方feign client的重试,导致接口重复执行。万幸的是数据已经修复,花了几个小时跟踪feign和ribbon的源码,把其原理彻底搞明白了。
feign是netflix提供的服务间基于http的rpc调用框架,在spring cloud得到广泛应用。默认情况下,一个feign client是在hystrix断路器中执行,并利用ribbon进行软负载选择远程target service,所以可以想象出一个feign client的层次架构是包裹的层次,hystrix控制整个rpc从调用到方法返回,而ribbon控制从选址到socket返回,关于它们的超时设置,请参考我上一篇博客:SpringCloud重试机制配置。
今天先不讨论hystrix,仅从feign在spring cloud中应用容易踩到坑和从源码debug的角度看执行过程。我们先来填坑,看看这个配置:
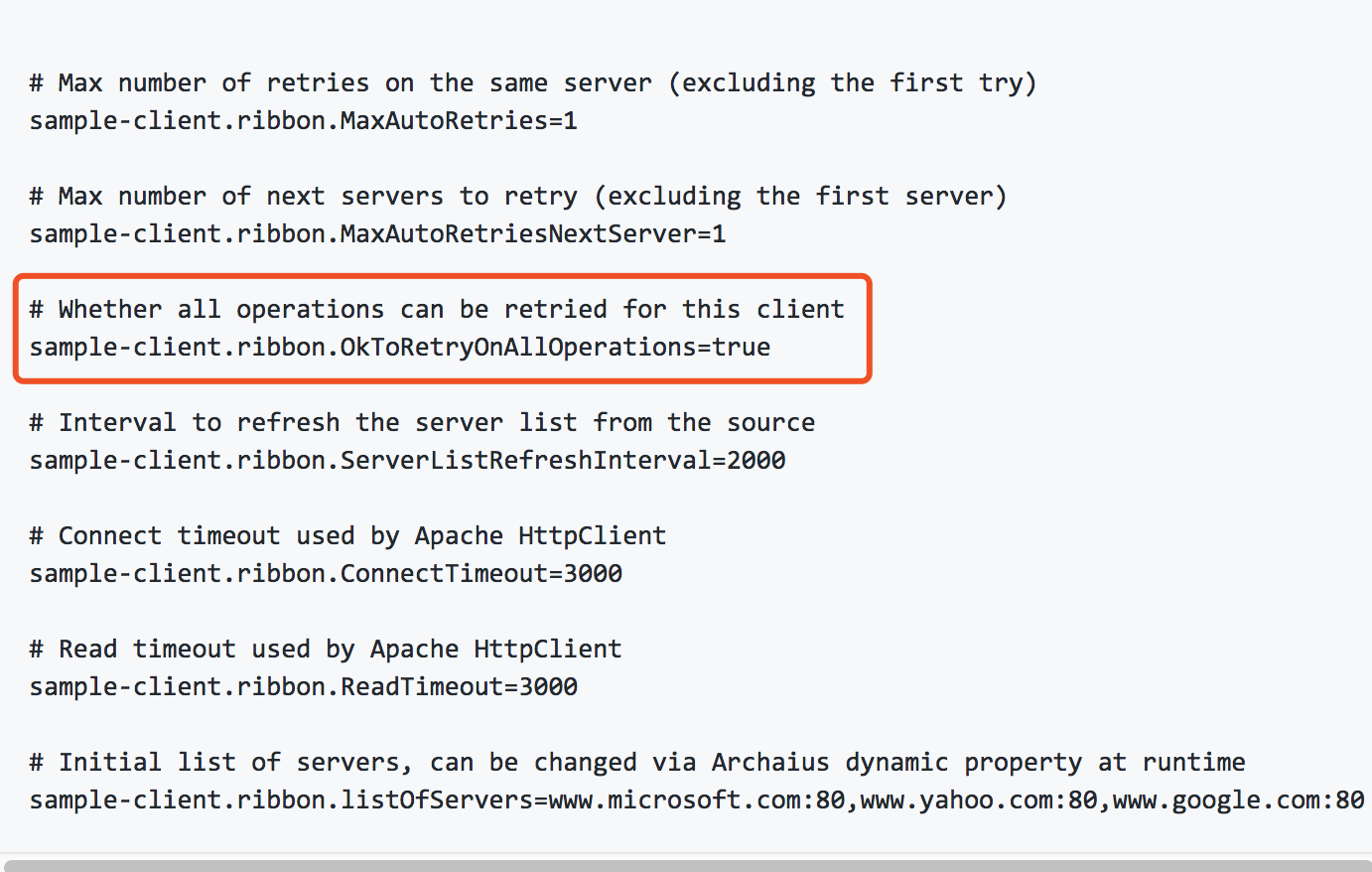
这是ribbon在github wiki上的给我们的默认配置,OKToRetryOnAllOperations的意义是无论是请求超时或者socket read timeout都进行重试,
这个OKToRetryOnAllOperations=true我建议改成false或者不设,为什么?我们直接上源码分析:
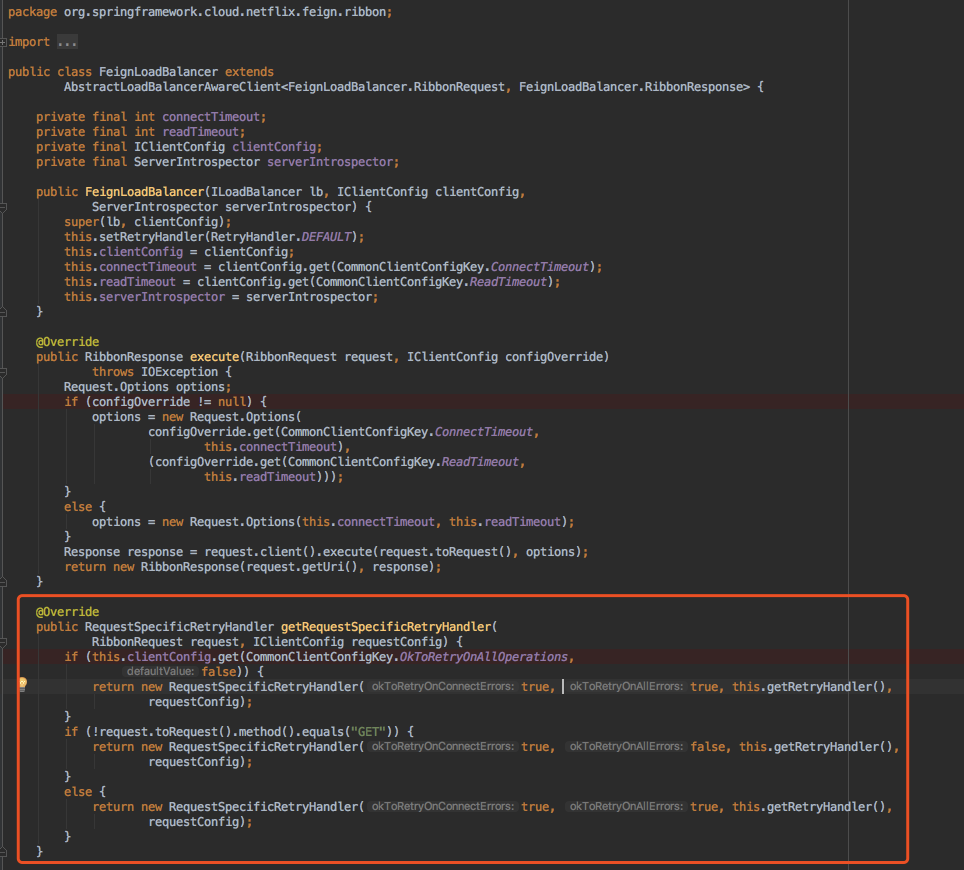
这是feign初始化它的ribbon重试控制器,它的逻辑是如果设置了OKToRetryOnAllOperations这个参数为true,第一个if的构造函数就设置为true,这就比较危险了,如果接口是post或者put请求,这是进行修改操作,如果服务器长时间不返回,客户端发生socket read timeout会进行重试,如果服务器接口没做幂等性,这个后果自己想想。继续看后面两个判断,得出的结论是:如果是Get请求设置为OKToRetryOnAllOperations=true不影响,因为只涉及到读操作,如果是其他http方法,默认只会在socket还没建立连接时进行重试,比如突然网络抖动或者一台服务实例挂了,这是没问题的,因为只保证了服务器端执行一次(还是建议涉及到修改的接口做好幂等性)。
关于超时再提一下两个配置ribbon.ConnectTimeout和ReadTimeout,根据自己服务调用情况,慎重进行设置,我的建议是ReadTimeout可以稍微设大点(同时注意hystrix线程池超时时间)。
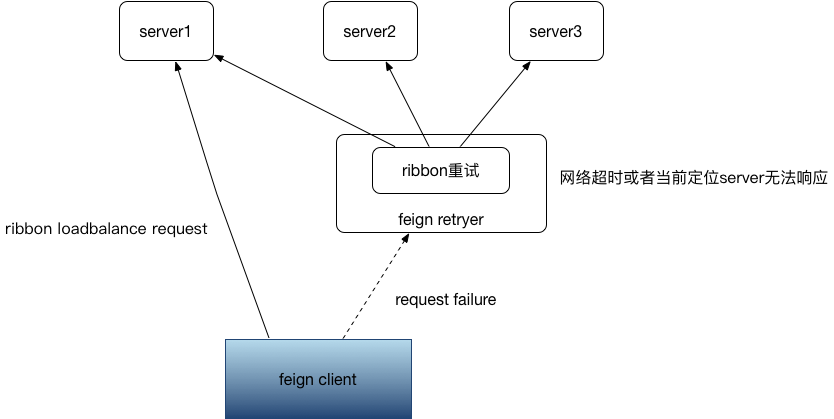
下面我们分析下feign的执行过程和重试机制,下面这个图是我简易画的,这是总体概览
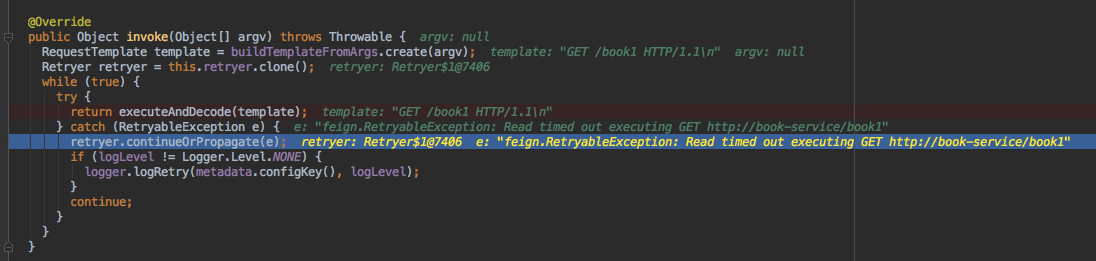
1、一个feign请求开始,通过动态代理的方式包裹了一层feign retryer逻辑,控制最外层的feign自身的重试机制:
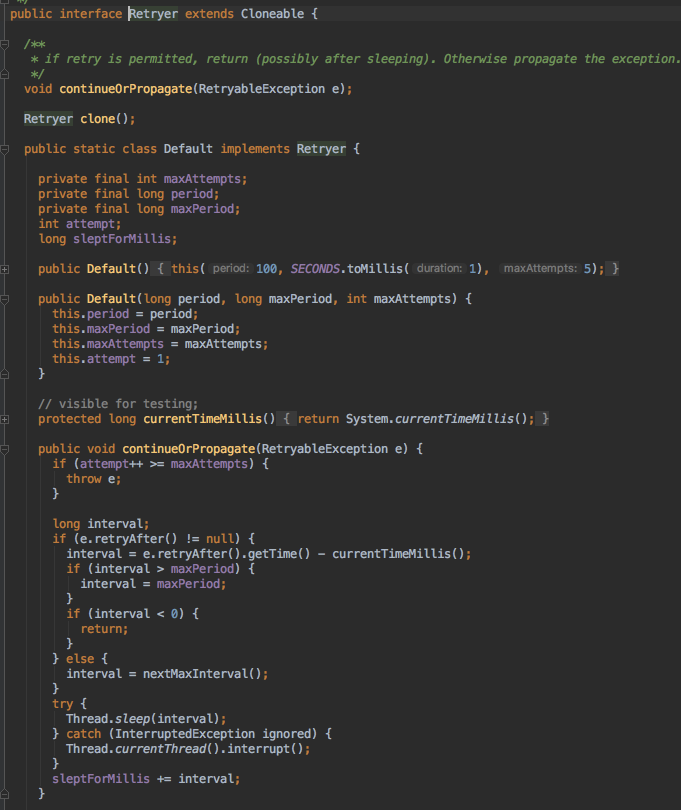
2、continueOrPropagate是控制是否重试和跳出上层死循环的最终出口:
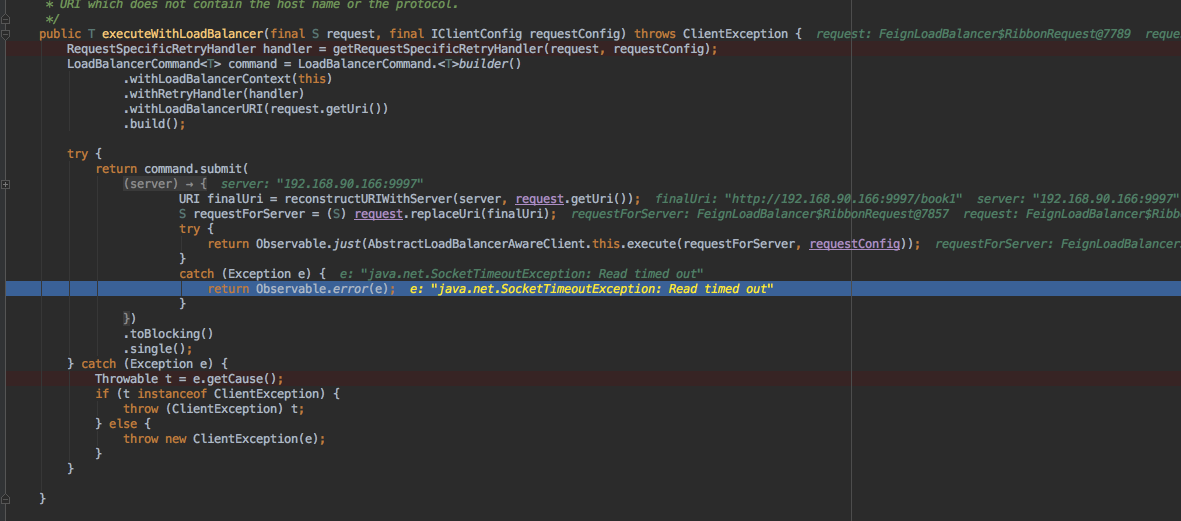
3、必要的ribbon设置,并调用真实执行逻辑
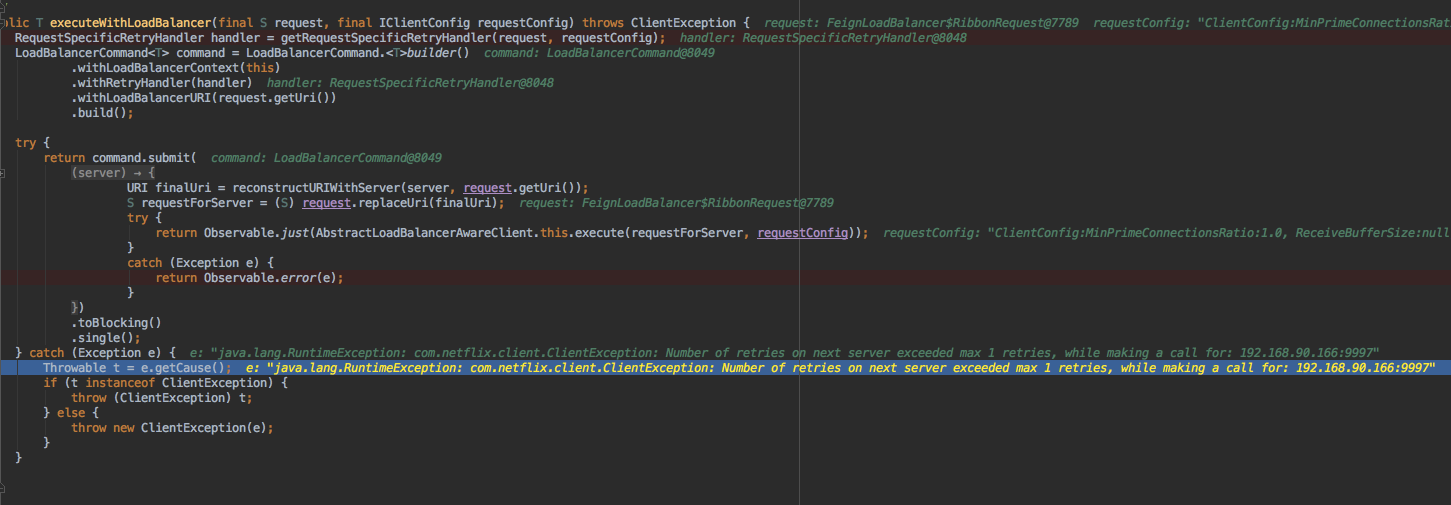
4、在AbstractLoadBalancerAwareClinet中执行,LoadBalancerCommand中控制ribbon选取server、重试、记录执行状态、封装错误返回,这都是利用RXJava的观察者模式来做的
- 第一个catch控制ribbon请求的Exception
- 第二个catch控制整个一轮ribbon重试(ribbon.MaxAutoRetries、ribbon.MaxAutoRetriesNextServer)下来,仍然异常。
- 回到方法调用入口的catch,进行feign的retryer的逻辑,决定是整体再重试还是直接抛出异常跳出循环(默认是5次重试)
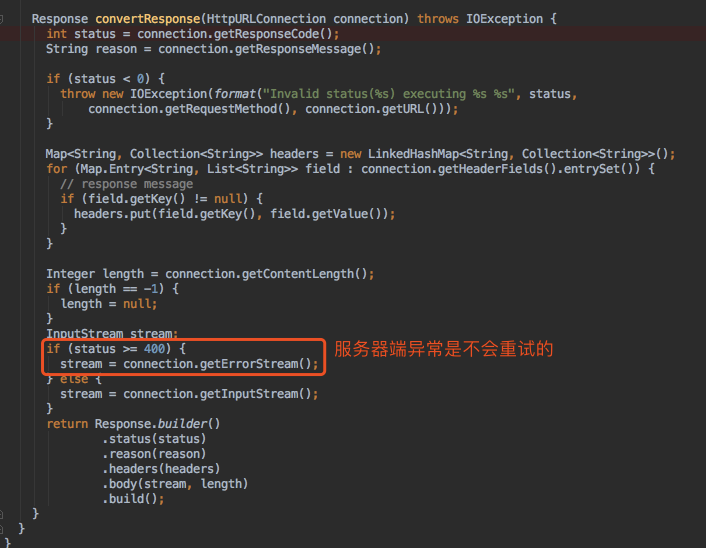
5、默认情况下,在feign.Client.Default的内部类里进行真实的http请求,默认是用Java的网络api(这块可以替换掉自己写,比如使用:netty)
总结下,注意我们的接口请求方式,设置合适的超时时间,OKToRetryOnAllOperations这个参数慎用。如果对网络请求性能要求较高,可以在适当位置重写源码。