本文首先介绍了操作系统,然后引出容器技术以及虚拟机技术,最后介绍了 Docker 和 Hyper 技术。通过本文可以清楚地对三者有感性认识。
操作系统概述
我们可以把操作系统简化为:
操作系统 = 内核 + apps
其中内核负责管理底层硬件资源,包括CPU、内存、IO设备等,并向上为 apps 提供系统调用接口,上层 apps 应用必须通过系统调用方式使用硬件资源,通常并不能直接访问资源。这里的 apps 指的是用户接口,比如 shell、gui、services、包管理工具等(Linux 的图形界面也是作为可选应用之一,而不像 Windows 是集成到内核中的),注意与我们手动安装的应用区别开来。同一个内核加上不同的 apps,就构成了不同的操作系统发行版,比如 Ubuntu、Red Hat、Android 等。因此我们可以认为,不同的 Linux 发行版本其实就是由应用 apps 构成的环境的差别,比如默认安装的软件、链接库、软件包管理以及图形界面等。我们把所有这些 apps 环境打成一个包,就可以称之为镜像。
问题来了,假如我们同时有多个 apps 环境,能否在同一个内核上运行呢?因为操作系统只负责提供服务,而并不管为谁服务,因此同一个内核之上可以同时运行多个 apps 环境是没有问题的。比如假设我们现在有 ubuntu 和 fedora 的 apps 环境,即两个发行版镜像,分别位于 /home/int32bit/ubuntu 和 /home/int32bit/fedora,我们最简单的方式,采用 chroot 工具即可快速切换到指定的应用环境中,相当于同时有多个 apps 环境在运行。
容器技术
我们以上通过 chroot 方式,感觉上就已经接近了容器的功能,但其实容器并没有那么简单,工作其实还差得远。首先要作为云资源管理还必须满足:
资源隔离
因为云计算本质就是集中资源再分配(社会主义),再分配过程就是资源的逻辑划分,提供资源抽象的实现方式,我们暂且定义为虚拟实体,虚拟实体可以是虚拟机、容器等。虚拟实体必须满足隔离性,包括用户隔离(或者说权限隔离)、进程隔离、网络隔离、文件系统隔离等,即虚拟实体只能感知其内部的资源,并且自以为是独占整个资源空间,它既不能感知其所在宿主机的真实资源,也不能感知其他虚拟实体的资源。
资源控制
资源控制指为虚拟实体分配一定量的资源,虚拟实体得到所分配的资源,不能超出资源最大使用量。
以上是虚拟实体的两个最基本要求,当然还包括其他很多条件,比如安全、性能等。本文主要基于以上两个基本条件进行研究。
虚拟机技术
显然满足以上两个条件,虚拟机是一种实现方式,这是因为:
- 隔离毋容置疑,因为不同的虚拟机运行在不同的内核,虚拟机内部是一个独立的隔离环境
- 资源控制也是毋容置疑的,Hypervisor能够对虚拟机分配指定的资源
目前 OpenStack Nova 和 AWS EC2 都是基于虚拟机提供计算服务,实现 CPU、RAM、Disk 等资源分配。其他比如 Vagrant 也是基于虚拟机快速构建应用环境。
但是虚拟机也带来很多问题,比如:
- 镜像臃肿庞大,不仅包括 apps,还包括一个庞大的内核
- 创建和启动时间开销大,不利于应用快速构建重组
- 额外资源开销大,部署密度小
- 性能损耗
容器技术
除了虚拟机,有没有其他实现方式能符合以上两个基本条件呢?容器技术便是另一种实现方式。表面上和我们使用 chroot 方式相似,所有的容器实例直接运行在宿主机中,所有实例共享宿主机的内核,而虚拟机实例内部的进程是运行在 GuestOS 中。由以上原理可知,容器相对于虚拟机有以下好处:
- 镜像体积更小,只包括 apps 以及所依赖的环境,没有内核
- 创建和启动快,不需要启动 GuestOS,应用启动开销基本就是应用本身启动的时间开销
- 无 GuestOS,无 Hypervisor,无额外资源开销,资源控制粒度更小,部署密度大
- 使用的是真实物理资源,因此不存在性能损耗
- 轻量级
目前比较流行的容器实现比如 LXC、LXD 以及 rkt 等,我们需要验证容器是否能够实现资源隔离和控制。
隔离性
主要通过内核提供 Namespace 技术实现隔离性,以下参考酷壳(http://coolshell.cn/articles/17010.html)
Linux Namespace 是 Linux 提供的一种内核级别环境隔离的方法。不知道你是否还记得很早以前的 Unix 有一个叫 chroot 的系统调用(通过修改根目录把用户 jail 到一个特定目录下),chroot 提供了一种简单的隔离模式:chroot 内部的文件系统无法访问外部的内容。Linux Namespace 在此基础上,提供了对 UTS、IPC、mount、PID、network、User 等的隔离机制。
Linux Namespace 有如下种类:
- Mount Namespaces
- UTS Namespaces
- IPC Namespaces
- PID Namespaces
- Network Namespaces
- User Namespaces
官方文档在这里《Namespace in Operation》(http://lwn.net/Articles/531114/)
由上表可知,容器利用内核的 Namespaces 技术可以实现隔离性。比如网络隔离,我们可以通过 sudo ip netns ls 查看 Namespaces,通过 ip netns add NAME 增加 Namespaces,不同的 Namespaces 可以有不同的网卡、Router、iptables 等。
资源控制
内核实现了对进程组的资源控制,即 Linux Control Group,简称 CGroup,它能为系统中运行进程组根据用户自定义组分配资源。简单来说,可以实现把多个进程合成一个组,然后对这个组的资源进行控制,比如CPU,内存大小、网络带宽、磁盘 iops 等,Linux 把 CGroup 抽象成一个虚拟文件系统,可以挂载到指定的目录下,Ubuntu 14.04 默认自动挂载在 /sys/fs/cgroup 下,用户也可以手动挂载,比如挂载 Memory 子系统(子系统可以实现某类资源的控制,比如 CPU、Memory、blkio 等)到 /mnt 下:
sudo mount -t cgroup -o memory /mnt
挂载后就能像查看本地文件一样浏览进程组以及资源控制情况,控制组并不是孤立的,而是组织成树状结构构成进程组树,控制组的子节点会继承父节点。下面以 Memory 子系统为例:
ls /sys/fs/cgroup/memory/
输出:
cgroup.clone_children memory.kmem.failcnt memory.kmem.tcp.usage_in_bytes memory.memsw.usage_in_bytes memory.swappiness cgroup.event_control memory.kmem.limit_in_bytes memory.kmem.usage_in_bytes memory.move_charge_at_immigrate memory.usage_in_bytes cgroup.procs memory.kmem.max_usage_in_bytes memory.limit_in_bytes memory.numa_stat memory.use_hierarchy cgroup.sane_behavior memory.kmem.slabinfo memory.max_usage_in_bytes memory.oom_control notify_on_release docker memory.kmem.tcp.failcnt memory.memsw.failcnt memory.pressure_level release_agent memory.failcnt memory.kmem.tcp.limit_in_bytes memory.memsw.limit_in_bytes memory.soft_limit_in_bytes tasks memory.force_empty memory.kmem.tcp.max_usage_in_bytes memory.memsw.max_usage_in_bytes memory.stat user
以上是根控制组的资源限制情况,我们以创建控制内存为 4MB 的 Docker 容器为例:
docker run -m 4MB -d busybox ping localhost
返回 ID 为 0532d4f4af67,自动会创建以 Docker 实例 ID 为名的控制组,位于 /sys/fs/cgroup/memory/docker/0532d4f4af67...,我们查看该目录下的 memory.limit_in_bytes 文件内容为:
cat memory.limit_in_bytes 4194304
即最大的可使用的内存为 4MB,正好是我们启动 Docker 所设定的。
由以上可知,容器可以通过 CGroup 实现资源控制。
Docker技术
在 Docker 之前其实容器技术早就有了,Google 的 Borg 以及 Omega 都利用了容器技术。但是之前容器一直没有形成一个标准,也没有一个很好的管理工具。LXC 是 Linux 原生支持的容器,很多工具依赖于具体的发行版,可能会出现移植性差的问题,并且也缺乏一组完善的管理工具集。而 Docker 基于底层的内核特性的基础上,在上层构建了一个更高层次的具备多个强大功能的工具集,它是 PaaS 提供商 dotCloud 开源的一个基于 LXC 的高级容器引擎,简单说 Docker 提供了一个能够方便管理容器的工具并形成标准。Docker 相当于把应用以及应用所依赖的环境完完整整地打成了一个包,这个包拿到哪里都能原生运行。
其特性包括:
- 快速构建基于容器的分布式应用
- 具有容器的所有优点
- 提供原生的资源监控
- 自动构建和版本控制
- 快速构建和重组
Docker 与虚拟机原理对比:

容器技术在很早就有了,因此不能说 Docker 发明了容器技术,而仅仅是发明了一套完整的管理容器的工具集。但其实 Docker 核心的创新在于它的镜像管理,因此有人说:
Docker = LXC + Docker Image
Docker 镜像的创新之处在于使用了类似层次的文件系统 AUFS,简单说就是一个镜像是由多个镜像层层叠加的,从一个 Base 镜像中通过加入一些软件构成一个新层的镜像,依次构成最后的镜像,如图:

知乎:Docker 的几点疑问
Image 的分层,可以想象成 Photoshop 中不同的 layer。每一层中包含特定的文件,当 Container 运行时,这些叠加在一起的层就构成了 Container 的运行环境(包括相应的文件、运行库等,不包括内核)。Image 通过依赖的关系,来确定整个镜像内到底包含那些文件。之后版本的 Docker,会推出 Squash 的功能,把不同的层压缩成为一个,和 Photoshop 中合并层的感觉差不多。
作者:Honglin Feng
链接:https://www.zhihu.com/question/25394149/answer/30671258
这里利用了COW(copy on write)技术,即从一个镜像启动一个容器实例,这个镜像是以只读形式挂载的,即不允许任何修改操作。当在容器实例中修改一个文件时,会首先从镜像里把这个文件拷贝到可写层,然后执行更新操作。当读一个文件时,会首先从可写层里找这个文件,若这个文件存在,直接返回文件内容,如果不存在这个文件,则会从最顶层的镜像开始查找,直到最底层的 Base 镜像。这里存在的一个问题是,当镜像层很多时,查找一个文件可能需要一层一层查找,影响性能。基于 Ceph 构建 OpenStack 创建虚拟机也一样的原理,我们上传一个镜像到 Glance 时,首先对这个镜像创建一个快照并保护起来不允许写操作,当基于这个镜像创建虚拟机时,直接从镜像快照克隆一个新的 rbd image 作为虚拟机的根磁盘,最开始这个根磁盘除了指向其 parent 快照的指针,没有任何内容,不占任何磁盘空间,当虚拟机需要修改一个对象时,首先从 parent 中拷贝这个对象到它所在的空间,再执行更新操作。当读一个文件时,如果存在这个文件,直接读取,否则需要去 parent 所在的 image 中查找。
这样的好处是:
- 节省存储空间——多个镜像共享 Base Image 存储
- 节省网络带宽——拉取镜像时,只需要拉取本地没有的镜像层,本地已经存在的可以共享,避免多次传输拷贝
- 节省内存空间——多个实例可共享 Base Image,多个实例的进程命中缓存内容的几率大大增加。如果基于某个镜像启动一个虚拟机需要资源 k,则启动 n 个同一个镜像的虚拟机需要占用资源 kn,但如果基于某个镜像启动一个 Docker 容器需要资源 k,无论启动多少个实例,资源都是k
- 维护升级方便——相比于 copy-on-write 类型的 FS,Base Image 也是可以挂载为可 Writeable 的,可以通过更新 Base Image 而一次性更新其之上的 Container
- 允许在不更改 Base Image 的同时修改其目录中的文件——所有写操作都发生在最上层的 writeable 层中,这样可以大大增加 Base Image 能共享的文件内容
使用容器技术,带来了很多优点,但同时也存在一些问题:
- 隔离性相对虚拟机弱-由于和宿主机共享内核,带来很大的安全隐患,容易发生逃逸
- 如果某些应用需要特定的内核特性,使用容器不得不更换宿主机内核
更多关于 AUFS 参考酷壳:Docker 基础技术-AUFS(http://coolshell.cn/articles/17061.html)
Hyper技术
上文提到容器存在的问题,并且 Docker 的核心创新在于镜像管理,即:
Docker = LXC + Docker Image
于是就有人提出把容器替换成最初的 Hypervisor,而又利用 Docker Image 的优势,接下来介绍的 Hyper 技术以及 VMware 最新的 vic 技术大体如此,Hyper 官方(https://hyper.sh/)定义:
Hyper – a Hypervisor-based Containerization solution
即:
Hyper = Hypervisor + Docker Image
简而言之 Hyper 是一种基于虚拟化技术(Hypervisor)的 Docker 引擎。官方(http://mt.sohu.com/20150625/n415640410.shtml)认为:
虽然 Hyper 同样通过 VM 来运行 Docker 应用,但 HyperVM 里并没有 GuestOS,相反的,一个 HyperVM 内部只有一个极简的 HyperKernel,以及要运行的 Docker 镜像。这种 Kernel Image 的”固态”组合使得 HyperVM 和 Docker 容器一样,实现了 Immutable Infrastructure 的效果。借助 VM 天然的隔离性,Hyper 能够完全避免 LXC 共享内核的安全隐患。
创建一个基于 Hyper 的 Ubuntu:
sudo hyper run -t ubuntu:latest bash
创建时间小于1秒,确实达到启动容器的效率。
查看内核版本:
root@ubuntu-latest-7939453236:/# uname -a Linux ubuntu-latest-7939453236 4.4.0-hyper #0 SMP Mon Jan 25 01:10:46 CST 2016 x86_64 x86_64 x86_64 GNU/Linux
宿主机内核版本:
$ uname -a Linux lenovo 3.13.0-77-generic #121-Ubuntu SMP Wed Jan 20 10:50:42 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
启动基于 Docker 的 Ubuntu 并查看内核版本:
$ docker run -t -i ubuntu:14.04 uname -a Linux 73a88ca16d94 3.13.0-77-generic #121-Ubuntu SMP Wed Jan 20 10:50:42 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
我们发现 Docker 和宿主机的内核版本是一样的,即 3.13.0-77-generic,而 Hyper 内核不一样,版本为 4.4.0-hyper。
以下为官方数据(https://github.com/hyperhq/hyper):
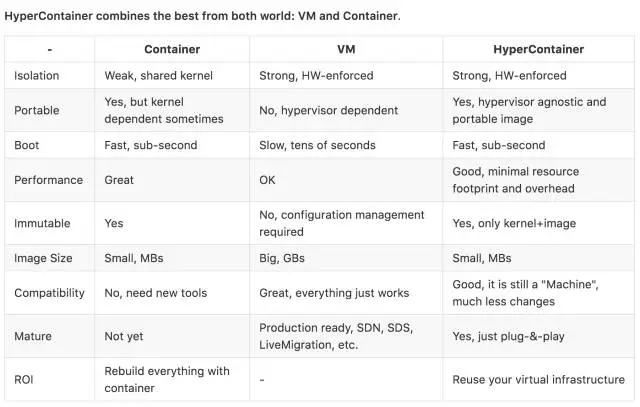
因此 Hyper 是容器和虚拟机的一种很好的折衷技术,未来可能前景广大,但需要进一步观察,我个人主要存在以下疑问:
- 使用极简的内核,会不会导致某些功能丢失?
- 是不是需要为每一个应用维护一个微内核?
- 有些应用需要特定内核,这些应用实际多么?可以通过其他方式避免么?
- Hyper 引擎能否提供和 Docker 引擎一样的 API,能否在生态圈中相互替代?
- 隔离性加强的同时也牺牲了部分性能,如何权衡?
总结
近年来容器技术以及微服务架构非常火热,CaaS 有取代传统 IaaS 的势头,未来云计算市场谁成为主流值得期待。