前面已经介绍了django的各种用法,从这一章开始,将实际搭建一个blog系统。
首先我们需要设计blog的模型,在models.py中添加如下内容
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import sys
from django.db import models
from django.utils import timezone
from django.contrib.auth.models import User
from django.contrib import admin
from django.db import models
#下面的部分是设置编码,否则在输入中文的时候会报错
default_encoding = 'utf-8'
reload(sys)
sys.setdefaultencoding(default_encoding)
# Create your models here.
class Post(models.Model):
STATUS_CHOICES=(('draft','Draft'),('published','Published'),)
title=models.CharField(max_length=250,verbose_name=u'标题')
slug=models.SlugField(max_length=250,unique_for_date='publish')
author=models.ForeignKey(User,related_name='blog_posts',verbose_name=u'作者')
body=models.TextField(verbose_name=u'正文')
publish=models.DateTimeField(default=timezone.now,verbose_name=u'发表时间')
created=models.DateTimeField(auto_now_add=True,verbose_name=u'创建时间')
updated=models.DateTimeField(auto_now=True,verbose_name=u'更新时间')
status=models.CharField(max_length=10,choices=STATUS_CHOICES,default='draft',verbose_name=u'状态')
class Meta:
ordering=('-publish',)
def __str__(self):
return self.title这就是给blog使用的基础模型,来看下各个字段的定义:
title:这个字段对应帖子的标题。它是CharField,在SQL数据库中会被转化成VARCHAR。
slug:这个字段将会在URLs中使用。slug就是一个短标签,该标签只包含字母,数字,下划线或连接线
author:这是一个ForeignKey。这个字段定义了一个多对一(many-to-one)的关系。我们告诉Django一篇帖子只能由一名用户编写,一名用户能编写多篇帖子。根据这个字段,Django将会在数据库中通过有关联的模型(model)主键来创建一个外键。在这个场景中,我们关联上了Django权限系统的User模型(model)。我们通过related_name属性指定了从User到Post的反向关系名
body:这是帖子的主体。它是TextField,在SQL数据库中被转化成TEXT。
publish:这个日期表明帖子什么时间发布。我们使用Djnago的timezone的now方法来设定默认值
created:这个日期表明帖子什么时间创建。因为我们在这儿使用了auto_now_add,当一个对象被创建的时候这个字段会自动保存当前日期。
updated:这个日期表明帖子什么时候更新。因为我们在这儿使用了auto_now,当我们更新保存一个对象的时候这个字段将会自动更新到当前日期
status:这个字段表示当前帖子的展示状态。我们使用了一个choices参数,这样这个字段的值只能是给予的选择参数中的某一个值
verbose_name 是给各个字段起了一个别名,便于识别
模型设置后好,通过python manage.py makemigrations blog和python manage.py migrate进行数据库迁移,同步
zhf@zhf-maple:~/py_prj/mysite$ python manage.py makemigrations blog
Migrations for 'blog':
blog/migrations/0001_initial.py
- Create model Post
zhf@zhf-maple:~/py_prj/mysite$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, blog, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying blog.0001_initial... OK
Applying sessions.0001_initial... OK
同时在models.py中添加Post的管理设置
class PostAdmin(admin.ModelAdmin):
list_display = ('title', 'slug', 'author', 'publish',
'status')
list_filter = ('status', 'created', 'publish', 'author')
search_fields = ('title', 'body')
prepopulated_fields = {'slug': ('title',)}
raw_id_fields = ('author',)
date_hierarchy = 'publish'
ordering = ['status', 'publish']
并在admin.py中
接下来我们将要创建一个超级用户对我们的博客系统进行管理。这个超级用户主要是进入后台admin的时候使用。关于后台admin的使用参考之前的帖子
www.cnblogs.com/zhanghongfeng/p/8018415.html
zhf@zhf-maple:~/py_prj/mysite$ python manage.py createsuperuser
Username (leave blank to use 'zhf'): root
Email address: maple412@163.com
Password:
Password (again):
This password is too short. It must contain at least 8 characters.
Password:
Password (again):
Superuser created successfully.
运行程序,并在浏览器中输入http://127.0.0.1:8000/admin/, 用刚才创建的超级账户登录便可以看到后台的信息

界面是英文版的,且标题也是默认的.如果想修改界面和标题.需要在admin.py和setting.py中进行修改
admin.py中增加修改标题和title
admin.site.site_header=u"张红枫的博客"
admin.site.site_title=u"张红枫的博客"
setting.py中增加django.middleware.locale.LocaleMiddleware
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.locale.LocaleMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]ting.py中增加
这样就能看到一个中文版的界面
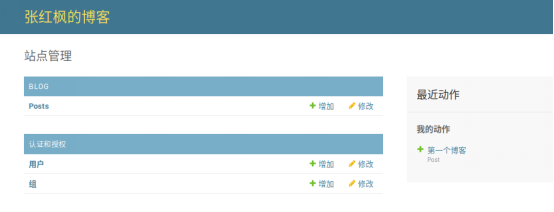
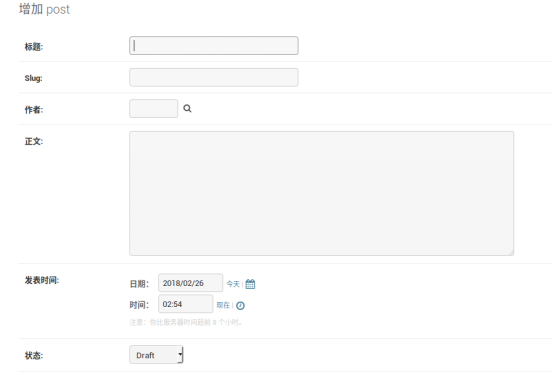
点击新增Post就可以看到定义的字段
我们增加一个后就可以显示出来

模型定义后好,接下来定义个视图的测试文件,在views.py中定义个test函数来显示所有的博客
from django.shortcuts import HttpResponse
from .models import Post
# Create your views here.
def test(request):
posts=Post.objects.all()
return HttpResponse(posts)
接下里就需要为试图添加URL模式,也就是路由了.在blog应用下添加一个urls.py文件
from django.conf.urls import url
from . import views
urlpatterns = [
# post views
url(r'^$', views.test, name='post_list'),
]
现在你需要将你blog中的URL模式包含到项目的主URL模式中。编辑你的项目中的mysite文件夹中的urls.py文件,如下所示:
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^blog/',include('blog.urls',namespace='blog',app_name='blog')),
]
通过include(‘blog.urls’)的方式就将blog应用下的url和主url拼接了起来.在浏览器中输入http://127.0.0.1:8000/blog/的时候将会跳转到去执行视图函数test

views.py中的test函数是通过Httpresponse的方式直接进行反馈.接下来我们要为视图创建模板:template. 在template中创建如下的文档结构.base.html文件将会包含站点主要的HTML结构以及分割内容区域和一个导航栏。list.html和detail.html文件会继承base.html文件来渲染各自的blog帖子列和详情视图(view)。

在base.html中添加如下代码:
{% load staticfiles %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}{% endblock %}</title>
<link href="{% static "css/blog.css" %}" rel="stylesheet">
</head>
<body>
<div id="content">
{% block content %}
{% endblock %}
</div>
</body>
</html>
你可以看到有两个{% block %}标签(tags)。这些是用来告诉Django我们想在这个区域中定义一个区块(block)。继承这个模板(template)的其他模板(templates)可以使用自定义的内容来填充区块(block)。我们定义了一个区块(block)叫做title,另一个区块(block)叫做content。
在post/list.html中添加如下代码:
{% extends "blog/base.html" %}
{% block title %}My Blog{% endblock %}
{% block content %}
<h1>My Blog</h1>
{% for post in posts %}
<h2>
<a href="{{ post.get_absolute_url }}">
{{ post.title }}
</a>
</h2>
<p class="date">
Published {{ post.publish }} by {{ post.author }}
</p>
{{ post.body|truncatewords:30|linebreaks }}
{% endfor %}
{% endblock %}
通过{% extends %}模板标签(template tag),我们告诉Django需要继承blog/base.html 模板(template)。然后我们在title和content区块(blocks)中填充内容。我们通过循环迭代帖子来展示它们的标题,日期,作者和内容
在views.py中添加post_list函数
def post_list(request):
posts=Post.objects.all()
return render(request,'post/list.html',{'posts':posts}
在blog中的urls.py添加对应的路由:
urlpatterns = [
# post views
url(r'^$', views.post_list, name='post_list'),
]
在浏览器中输入http://127.0.0.1:8000/blog/后可以显示所有的博客内容
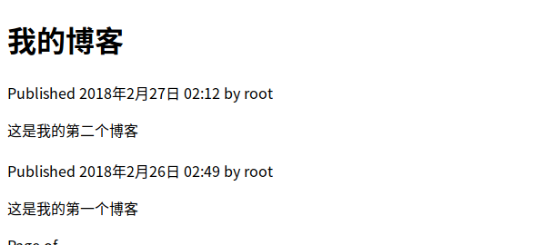
在这个页面中我们显示了所有的博客内容,如果我们不想在一个页面中显示所有的内容,需要采取分页的方法,比如一页只显示一个.这就需要采集分页的方法django有一个内置的Paginator类允许你方便的管理分页。编辑blog应用下的views.py文件导入Django的页码类修改post_list如下所示:
def post_list_page(request):
object_list = Post.objects.all()
paginator = Paginator(object_list, 1) # 1 posts in each page
page = request.GET.get('page')
try:
posts = paginator.page(page)
except PageNotAnInteger:
posts = paginator.page(1)
except EmptyPage:
posts = paginator.page(paginator.num_pages)
return render(request,
'post/list.html',
{'page': page,
'posts': posts,
})
那么这个Paginator是如何工作的呢,
1 首先创建一个Paginator实例类并且传入查询到的所有对象
2 获取到page GET参数来指明页数
3 通过调用Paginator的 page()方法在期望的页面中获得了对象
4 如果page参数不是一个整数,我们就返回第一页的结果。如果这个参数数字超出了最大的页数,我们就展示最后一页的结果
5 传递页数并且获取对象给这个模板(template)
现在,我们必须创建一个模板(template)来展示分页处理,它可以被任意的模板(template)包含来使用分页。在blog应用的templates文件夹下创建一个新文件命名为pagination.html。在该文件中添加如下HTML代码
<div class="pagination">
<span class="step-links">
{% if page.has_previous %}
<a href="?page={{ page.previous_page_number }}">Previous</a>
{% endif %}
<span class="current">
Page {{ page.number }} of {{ page.paginator.num_pages }}.
</span>
{% if page.has_next %}
<a href="?page={{ page.next_page_number }}">Next</a>
{% endif %}
</span>
</div>
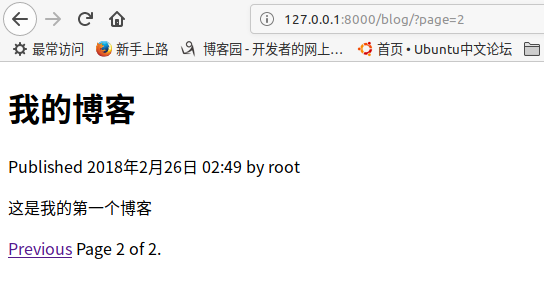
我们来看下实际的效果.输入http://127.0.0.1:8000/blog/后显示如下页面.由于我们在url中并没有输入page参数,因此调用posts = paginator.page(1)显示地一个博客内容对象.

当我们点击next后,浏览器中的url变成了http://127.0.0.1:8000/blog/?page=2. 此时我们获取到了page参数,因此通过posts = paginator.page(page) 获取对应page的博客对象.