Numpy最重要的一个特点就是N维数组对象。就是我们通常说的矩阵。通过Numpy可以对矩阵进行快速的运算。首先来看下创建方法. 通过array的方法将一个嵌套列表转换为2行4列的矩阵数组。通过shape可以看到矩阵的维度
In [1]: data=[[1,2,3,4],[5,6,7,8]]
In [2]: import numpy as np
In [3]: arr=np.array(data)
In [4]: arr
Out[4]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
In [6]: arr.shape
Out[6]: (2, 4)
In [7]: arr.dtype
Out[7]: dtype('int64')
除了array外,还有一些函数可以创建数组。比如zeros和ones可以分别创建指定长度的全0或全1数组。
In [8]: np.zeros(10)
Out[8]: array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [9]: np.zeros((3,6))
Out[9]:
array([[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.]])
In [10]: np.empty((2,3))
Out[10]:
array([[ 4.66186750e-310, 4.66186748e-310, 4.66186587e-310],
[ 6.91331345e-310, 0.00000000e+000, 0.00000000e+000]])
In [11]: np.ones((2,3))
Out[11]:
array([[ 1., 1., 1.],
[ 1., 1., 1.]])
从上面可以看到,empy产生的数都是一些未初始化过的值。其实使用起来没有实际的意义。还可以通过eye产生一个N×N的单位矩阵,也就是对角线都是1,其他位置为0的矩阵。
In [12]: np.eye(3)
Out[12]:
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
前面用dtype的时候得到的结果是int64,也就是64位的整型。如果我们想得到浮点数或者32位的整数,该如何操作呢,同样的也是通过dtype来指定类型。
In [13]: arr=np.array(data,dtype=np.int32)
In [14]: arr.dtype
Out[14]: dtype('int32')
In [15]: arr=np.array(data,dtype=np.float32)
In [16]: arr
Out[16]:
array([[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.]], dtype=float32)
dtype的类型和我们平常写代码的差不多,比如int8和uint8分别代表有符号的8位数和无符号的8位数。其中复数的表示方法:complex64,complex128,complex256来表示2个32位,64位,128位浮点数的复数
还有object和string_分别表示python对象类型和固定长度的字符串
如果针对已经生成的数组要想转换类型可以通过astype的方法来进行转换。
In [17]: arr.astype(np.int32)
Out[17]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]], dtype=int32)
介绍完了数组的定义,下面来看下数组和标量之间的运算。这里的运算不是矩阵之间的相乘。而是数组相同位置的数组进行相乘
In [18]: arr*arr
Out[18]:
array([[ 1., 4., 9., 16.],
[ 25., 36., 49., 64.]], dtype=float32)
In [19]: arr+arr
Out[19]:
array([[ 2., 4., 6., 8.],
[ 10., 12., 14., 16.]], dtype=float32)
In [20]: 1/arr
Out[20]:
array([[ 1. , 0.5 , 0.33333334, 0.25 ],
[ 0.2 , 0.16666667, 0.14285715, 0.125 ]], dtype=float32)
In [21]: arr-arr
Out[21]:
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]], dtype=float32)
切片:
ndarry的切片和Python列表的切片的用法是类似的
In [44]: arr1
Out[44]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [45]: arr1[1:3]
Out[45]:
array([[4, 5, 6],
[7, 8, 9]])
In [46]: arr1[1:2]
Out[46]: array([[4, 5, 6]])
In [47]: arr1[1]
Out[47]: array([4, 5, 6])
In [48]: arr[1:4]
Out[48]: array([[ 5., 6., 7., 8.]], dtype=float32)
In [49]: arr1[:2]
Out[49]:
array([[1, 2, 3],
[4, 5, 6]])
下面的两种方法代表分别从行和列分别进行切片。下面的第一个代表1行2列的元素
In [50]: arr1[1:2,2:3]
Out[50]: array([[6]])
这个代表1,2行和1,2列的元素
In [51]: arr1[1:3,1:3]
Out[51]:
array([[5, 6],
[8, 9]])
数组转置和轴对换
转置是矩阵函数中常用的操作。通过.T的操作就可以将矩阵转置
In [4]: arr
Out[4]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
In [5]: arr.T
Out[5]:
array([[1, 5],
[2, 6],
[3, 7],
[4, 8]])
既然能够转置,那么也就能够进行内积运算,通过np.dot就可以进行计算
In [6]: np.dot(arr.T,arr)
Out[6]:
array([[26, 32, 38, 44],
[32, 40, 48, 56],
[38, 48, 58, 68],
[44, 56, 68, 80]])
另外如果通过np.array()申明矩阵的时候是一维的,想改造成多维的话就需要用到resharp函数
In [11]: arr
Out[11]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
使用resharp的时候需要注意的是行,列数要和数字的数目能够对应得上,比如15个数字对应的就是3行4列或者4行3列。如果不能满足的话就会报如下的错误
In [9]: arr=np.arange(15).reshape((3,4))
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-9-12cfece7f834> in <module>()
----> 1 arr=np.arange(15).reshape((3,4))
ValueError: cannot reshape array of size 15 into shape (3,4)
通用函数:
在numpy中也默认了提供了很多数学运算函数。可以对矩阵数据进行各种的运算
如开平方:
In [13]: np.sqrt(arr)
Out[13]:
array([[ 0. , 1. , 1.41421356, 1.73205081, 2. ],
[ 2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ],
[ 3.16227766, 3.31662479, 3.46410162, 3.60555128, 3.74165739]])
指数运算:
In [14]: np.exp(arr)
Out[14]:
array([[ 1.00000000e+00, 2.71828183e+00, 7.38905610e+00,
2.00855369e+01, 5.45981500e+01],
[ 1.48413159e+02, 4.03428793e+02, 1.09663316e+03,
2.98095799e+03, 8.10308393e+03],
[ 2.20264658e+04, 5.98741417e+04, 1.62754791e+05,
4.42413392e+05, 1.20260428e+06]])
对数运算:
In [15]: np.log(arr)
/usr/local/bin/ipython:1: RuntimeWarning: divide by zero encountered in log
#!/usr/bin/python
Out[15]:
array([[ -inf, 0. , 0.69314718, 1.09861229, 1.38629436],
[ 1.60943791, 1.79175947, 1.94591015, 2.07944154, 2.19722458],
[ 2.30258509, 2.39789527, 2.48490665, 2.56494936, 2.63905733]])
这些都是一元函数,接受一个参数也就是数据本身就可以了。一元函数有下面这些:

另外还有二元函数,也就是输入2个参数,一个是数据本身,一个是和数据进行运算的参数。例如下面的这个例子,将矩阵的各个元素进行乘3处理
In [17]: np.multiply(arr,3)
Out[17]:
array([[ 0, 3, 6, 9, 12],
[15, 18, 21, 24, 27],
[30, 33, 36, 39, 42]])
二元函数有下面表格的这些
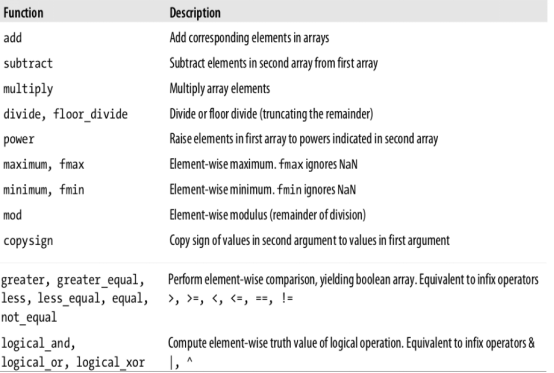
将条件逻辑表述为数组运算
如果我们有test1和test2两个数组,并且有cond作为判决条件。当cond中的值为True的时候选择test1的数据,当为False的时候选择test2的数据。
In [25]: test1=np.array([1,2,3,4,5])
In [26]: test2=np.array([6,7,8,9,10])
In [27]: cond=np.array([True,False,True,True,False])
我们自然而然会想到利用python中的ZIP函数来做
In [28]: result=[(x if c else y) for x,y,c in zip(test1,test2,cond)]
In [29]: result
Out[29]: [1, 7, 3, 4, 10]
但是面对大量数据的时候,这样的运行效率就比较低了,numpy自带了对应的函数也就是where来实现对应的功能。语法有更简单。cond作为第一个参数,如果为真就取第二个参数的数据,否则取第三个参数的数据
In [30]: result=np.where(cond,test1,test2)
In [31]: result
Out[31]: array([ 1, 7, 3, 4, 10])
where的第一个参数还可以是一个矩阵。这个例子中如果arr中的参数值大于3则为0,否则为-1
In [32]: arr
Out[32]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [33]: result=np.where(arr>3,0,-1)
In [34]: result
Out[34]:
array([[-1, -1, -1, -1, 0],
[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0]])
数学和统计方法:
numpy还提供了很多统计函数对数据进行统计运算,比如求平均,求方差等等。具体参考下表


In [35]: arr
Out[35]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [36]: np.mean(arr)
Out[36]: 7.0
In [37]: np.std(arr)
Out[37]: 4.3204937989385739
In [38]: np.var(arr)
Out[38]: 18.666666666666668
有了这些方法,我们就可以针对不同的行或者列进行运算。比如下面的元算就是计算第一列的所有数据平均值
In [43]: np.mean(arr[0:3,0:1])
Out[43]: 5.0
保存到文件:
通过save可以将arr的数据保存到test文件,后缀名为npy。然后通过load将文件的内容加载进来。这里保存的路径是当前的工作路径
In [45]: np.save('test',arr)
In [46]: ret=np.load('test.npy')
In [47]: ret
Out[47]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
也可以通过savez保存为一个压缩文件,其中可以通过设置参数保存多个数据。
In [49]: np.savez('test',a=arr,b=arr1)
在加载的时候,通过字典的方式得到各个不同的数据
In [51]: ret=np.load('test.npz')
In [52]: ret['a']
Out[52]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [53]: ret['b']
Out[53]:
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])