迭代器和生成器是python中的重要特性,本章作者花了很大的篇幅来介绍迭代器和生成器的用法.
首先来看一个单词序列的例子:
import re
re_word=re.compile(r'w+')
class Sentence(object):
def __init__(self,text):
self.text=text
self.word=re_word.findall(text)
def __getitem__(self, item):
return self.word[item]
def __len__(self):
return len(self.word)
def __str__(self):
return 'Sentence(%s)' % self.word
if __name__=="__main__":
s=Sentence("Today is Tuesday")
print s
for word in s:
print word
E:python2.7.11python.exe E:/py_prj/fluent_python/chapter14.py
Sentence(['Today', 'is', 'Tuesday'])
Today
is
Tuesday
在上面的这个例子中,for word in s 是在迭达整个序列。但是我们知道一个对象可以迭代是因为实现了__iter__方法,但是在Sentence中并没有实现__iter__方法。那为什么可以迭代呢
原因在于在python中实现了iter和getitem的都是可迭代的。首先会检查是否实现了iter方法,如果实现了则调用,如果没有但是实现了__item__方法。Python就会创建一个迭代器。尝试按照顺序获取元素。如果尝试失败则会抛出typeerror异常,提示object is not iterable.
因此如果对象实现了能返回迭代器的__iter__方法,那么对象就是可迭代的。如果实现了__getitem__方法,而且其参数是从零开始的索引。这种对象也可以迭代。我们用__iter__方法来改造之前的Sentence。在__iter__中返回一个可迭代对象iter(self.word)。当执行for word in s的时候就会调用__iter__方法
import re
re_word=re.compile(r'w+')
class Sentence(object):
def __init__(self,text):
self.text=text
self.word=re_word.findall(text)
def __iter__(self):
return iter(self.word)
def __len__(self):
return len(self.word)
def __str__(self):
return 'Sentence(%s)' % self.word
if __name__=="__main__":
s=Sentence("Today is Tuesday")
print s
for word in s:
print word
我们在来看下next, next的作用是返回下一个元素,如果没有元素了,抛出stopIteration异常。我们来看下next的使用方法。如果要遍历一个字符串,最简单的方法如下:
s='abc'
for char in s:
print char
如果不用for方法,代码需要修改如下:
s='abc'
it=iter(s)
while True:
try:
print next(it)
except StopIteration:
del it
break
首先将s变成一个iter对象,然后不断调用next获取下一个字符,如果没有字符了,则会抛出StopIteration异常释放对it的引用。废弃迭代对象。
比如下面的用法则会抛出异常:
s='abc'
it=iter(s)
print it.next()
print it.next()
print it.next()
print it.next()
E:python2.7.11python.exe E:/py_prj/fluent_python/chapter14.py
Traceback (most recent call last):
File "E:/py_prj/fluent_python/chapter14.py", line 21, in <module>
print it.next()
StopIteration
a
b
c
因为只有3个字符,但是调用了4次it.next()导致已经找不到字符因此抛出异常。
将到这里,我们需要解释两个概念,可迭代对象和迭代器
可迭代对象:实现了__iter__方法,就是可迭代的,可以返回自身作为迭代器。也可以返回其他一个可迭代对象
迭代器:在Python2中实现了next方法,在python3中实现了__next__方法。
我们来看下下面的这个图,首先要让x通过iter变成一个可迭代对象,然后使用迭代器来调用元素

我们将上面Sentence的代码修改下:
class Sentence(object):
def __init__(self,text):
self.text=text
self.word=re_word.findall(text)
self.index=0
def __iter__(self):
return self ⑴
def next(self): ⑵
try:
word=self.word[self.index]
except IndexError:
raise StopIteration
self.index+=1
return word
def __len__(self):
return len(self.word)
def __str__(self):
return 'Sentence(%s)' % self.word
if __name__=="__main__":
s=Sentence('Today is tuesday')
for word in s:
print word
E:python2.7.11python.exe E:/py_prj/fluent_python/chapter14.py
Today
is
Tuesday
在(1)中,首先这个类是可迭代的,因为具有__iter__方法,也是它自身的迭代器,因为具有next方法
在(2)中,由于实例是可迭代对象,因此可以不停的获取下一个元素
这和之前的实现有什么区别呢:
之前的代码虽然也实现了__iter__,但是返回的却是另外一个可迭代对象:iter(self.word),因此当我们使用for word in s的时候,其实是在迭代iter(self.word)
def __iter__(self):
return iter(self.word)
而如下的实现,其实是在迭代Sentence本身
def __iter__(self):
return self
def next(self):
try:
word=self.word[self.index]
except IndexError:
raise StopIteration
self.index+=1
return word
这里总结一下:
1 可迭代对象是迭代器的一个身份证明,只有是可迭代对象才能实现迭代器
2 迭代器其实具体工作的方法,就好比可迭代对象是政府,迭代器是公务员,只有依托于政府,公务员的工作才能进行。
下面介绍另外一个高级应用:生成器 yield.在函数中实现了yield的都是生成器函数。我们来看一个简单的例子:
def odd():
n=1
while True:
yield n
n+=2
if __name__=="__main__":
for o in odd():
print o
if o > 12:
break
在这里odd函数就是一个生成器。每当for o in odd()的时候。会自动生成一个值o。生成器的工作原理如下:
在每次for循环执行的时候,每次循环都会执行odd函数内部的代码,执行到yield n的时候就返回一个迭代值,并且保存当时所有的函数变量。下次迭代的时候,代码从yield n的下一条语句继续执行。看到这你会先到中断,对的yield就是有采用中断的方法。而且生成器从本质上说也是一个可迭代对象。也就是说实现了yield的函数既是一个可迭代对象,也是一个迭代器。我们来看下前面odd的另外一种用法:
o=odd()
print next(o)
print next(o)
print next(o)
print next(o)
print next(o)
E:python2.7.11python.exe E:/py_prj/fluent_python/chapter14.py
1
3
5
7
9
用next方法可以不停的生成返回的值。直到执行了o.close()关闭生成器。
在这里我们归纳下生成器,迭代器,可迭代对象之间的关系,用下面的图来表示,从图上可以看到,生成器是可迭代对象和迭代器的一种高级封装。
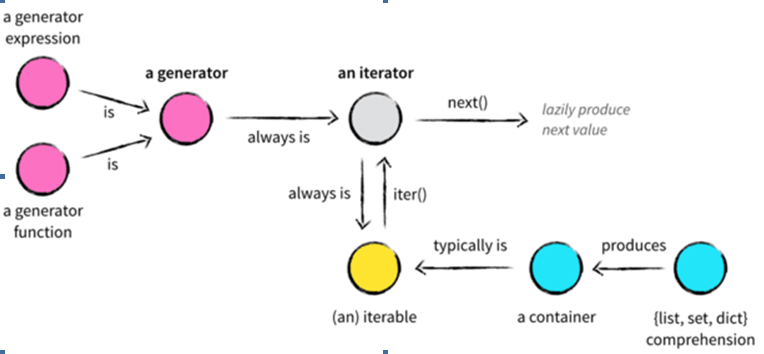
有了生成器,我们就可以将之前的Sentence改造如下:
class Sentence(object):
def __init__(self,text):
self.text=text
self.word=re_word.findall(text)
self.index=0
def __iter__(self):
for word in self.word:
yield word
def __len__(self):
return len(self.word)
def __str__(self):
return 'Sentence(%s)' % self.word
那么生成器除了能实现可迭代对象和迭代器,还有其他好处么。我们首先来看下这样的一种应用。我们想实现一个函数,这个函数返回值是得到100之内的所有数的平方值,我们根据这个返回值然后对各个值进行处理。一般来说我们会这样实现:
def data_generate(value):
number=[]
for i in range(value):
num=i*i
number.append(num)
return number
首先定义一个列表,然后将value内的值全部取平方。然后加入到number中去。等所有的数都生成后直接用return返回。这里看上去没啥问题。但是如果我们设置的value是10000或者是更大的数。那么对应的列表number也会变得更大。这样就需要更多的内存来存储值。如果这个value足够大,仅仅为了存储这些值就得耗尽所有的内存,哪该怎么办呢。有没有一种方法每当生成一个数的时候,就返回这个值,这样就不需要专门定义一个列表来存储了。
但是return语句每当调用的时候整个函数就停止了。无法满足我们的诉求。不用急,python中的生成器完全我们的需求。而且用法很简单
代码改造成如下
def data_generate(value):
for i in range(value):
num=i*i
yield num
如下调用
for i in data_generate(100):
print i
通过代码可以看到我们去掉了number列表以及return语句。添加了yield num语句。并用调用迭代器的方式调用data_generate函数。最终也达到了我们要的效果。而且最重要的是在函数中我们不需要申请一个占用内存的列表。完美的实现了我们的诉求。
那么我们可以用生成器来优化之前的Sentence实例。在之前的__init__实现中,我们首先用self.word=re_word.findall(text)将所有匹配的字符提取出来存入到self.word中,如果文本内容很大,那么就需要开辟一个大内存的列表来存储。如果我们只需要迭代前面几个单词,那么多余的内存就是不必要的。因此我们用生成器来优化下。re.finditer是函数re.findall的变种,返回的不是列表,而是一个生成器。代码改成如下:这里省去了self.word的赋值。也就不用开辟一块内存来专门存储。这样极大的节约了内存代码也变得更简短
class Sentence(object):
def __init__(self,text):
self.text=text
def __iter__(self):
for match in re.finditer(self.text):
yield match.group()
def __len__(self):
return len(self.word)
def __str__(self):
return 'Sentence(%s)' % self.word
另外生成器还可以用在列表推导上:
l=[x*x for x in range(10)]
l1=(x*x for x in range(10))
l是一个列表,而l1是一个生成器。也能达到节省内存的作用。
在python的自带库里面,也有很多生成器。
Filter(predict,it)把it中的各个元素传给predict,如果predict返回true,那么产出对应的元素。
def vowel(c):
return c.lower() in 'aeiou'
if __name__=="__main__":
print list(filter(vowel,'Aardvark'))
ifilterfalse:和filter相反,当predict返回False的时候才产出对应的元素
print list(itertools.ifilterfalse(vowel,'Aardvark'))
itertools.chain(it1,….itn):先产出it1中的元素,然后产出it2中的元素,以此类推,无缝连接在一起
print list(itertools.chain('abc',range(2)))
类似的在itertools中还有很多,这里就不一一介绍了
最后来看下iter函数的一个用法。Iter函数可以传入2个参数。第一个参数可以是可调用的对象,用于不断调用产出各个值,第二值是标记符,当可调用对象返回这个值的时候,触发迭代器抛出StopIteration异常。示例代码如下:
def d6():
return randint(1,6)
if __name__=="__main__":
d6_iter=iter(d6,1)
for roll in d6_iter:
print roll
iter(d6,1),首先采用d6函数不断产生整数,直到产生的数为1的时候停止。