cache(高速缓存--书桌)
现在也用来塞着那些基于局部性原理来管理的存储器
前言:
两级层次结构中存储信息交换的最小单元称为块block或行line(一个信息块就是一本书)
90%的时间只access到10%的memory
一个重要的原理:

- 数据项的读取

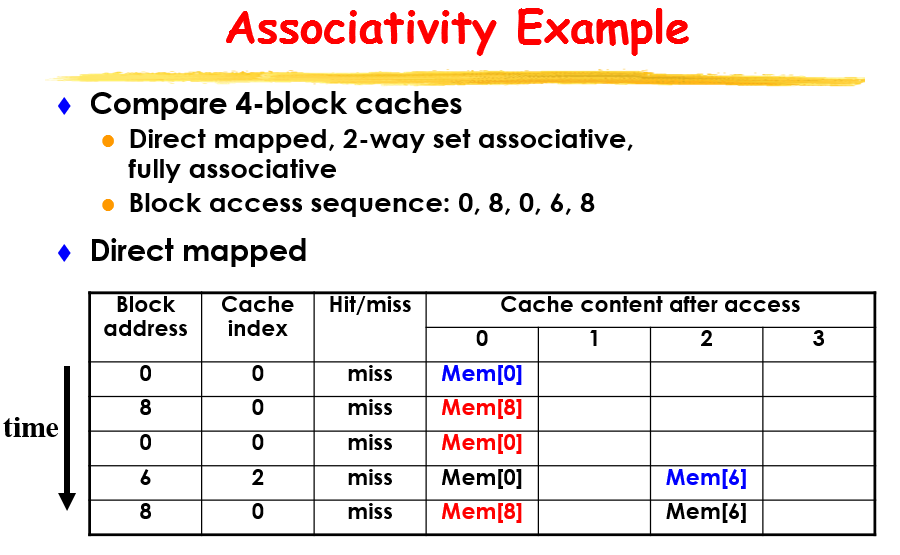
直接映射:
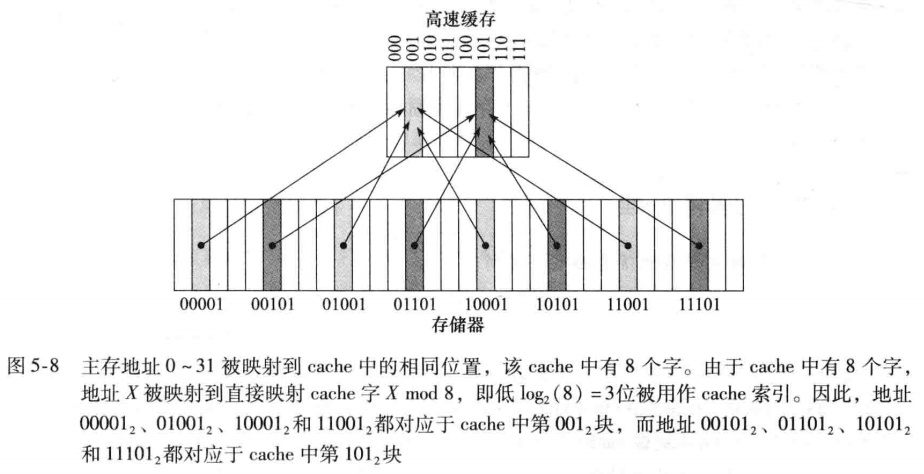
由于cache中的每个位置可能对应于主存中多个不同的地址,如何知道cache中的数据项是否是所请求的字呢?cache里要摆放data和tag

有效位被设置,表示可以使用该块中的值
举个栗子
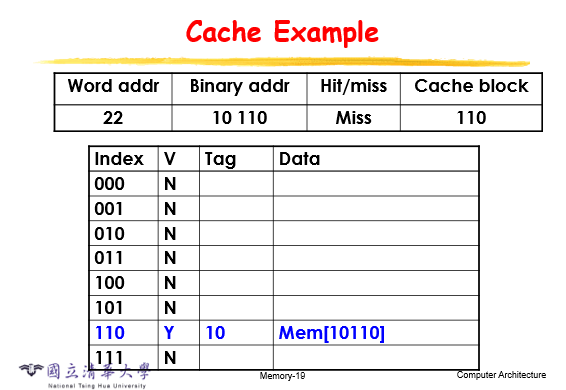
如果是hit的话表明cache里面有,就不用从底层调用了
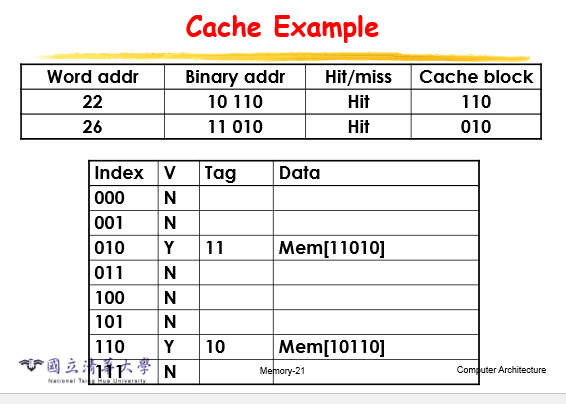
如果data的tag不一样的话,要把旧的写回去或者被盖过去
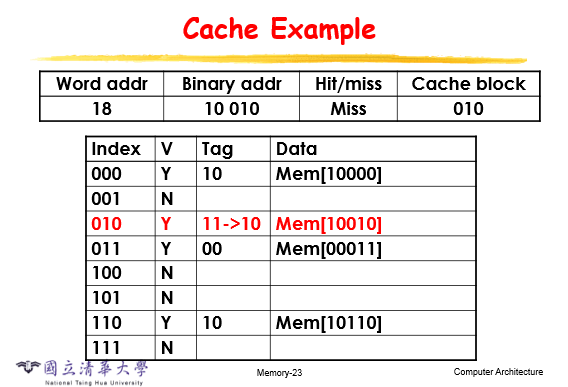
举个栗子
cache有64个block,一个block是16位
一个块,offset就是4位 0-3 指向block中的每一位
因为有64个块,所以index就是6位
剩下的都是tag
这里的32位是指memory的块地址

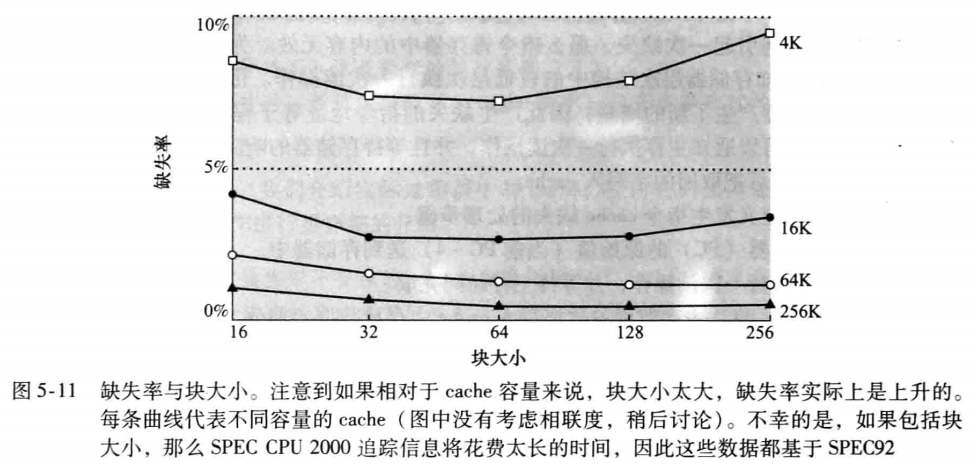
块不能太大也不能太小


读cache,会有hit和miss

写cache,也会有hit和miss,由于写回memory太浪费时间所以引入buffer,写入cache的data被写入buffer,由buffer再慢慢写回去


对于write miss,有两种情况:
1.把data从main memory搬进cache,再进行写操作,write through;
2.直接写进main memory,不经过cache(因为对于这一块数据除了写操作就没别的了),write back;
举个栗子:
内置FastMATH处理器的cache

有三种存储带宽 one-word-wide/wide/interleaved

对于cache和memory之间的数据传输有access time 和cycle time
access time是指从memory里面拿到资料的时间
cycle time是指 要等这么长的时间才能拿到下一笔资料
miss penalty

access DRAM的方法和cache不一样,按行按列找,先把整个行读下来

DDR SDRAMhttps://www.cnblogs.com/shengansong/archive/2012/09/01/2666213.html

每个章节和小标题要背一下 top-down
cache性能的计算举例


cache性能的提升
结构上的优化:
direct mapped
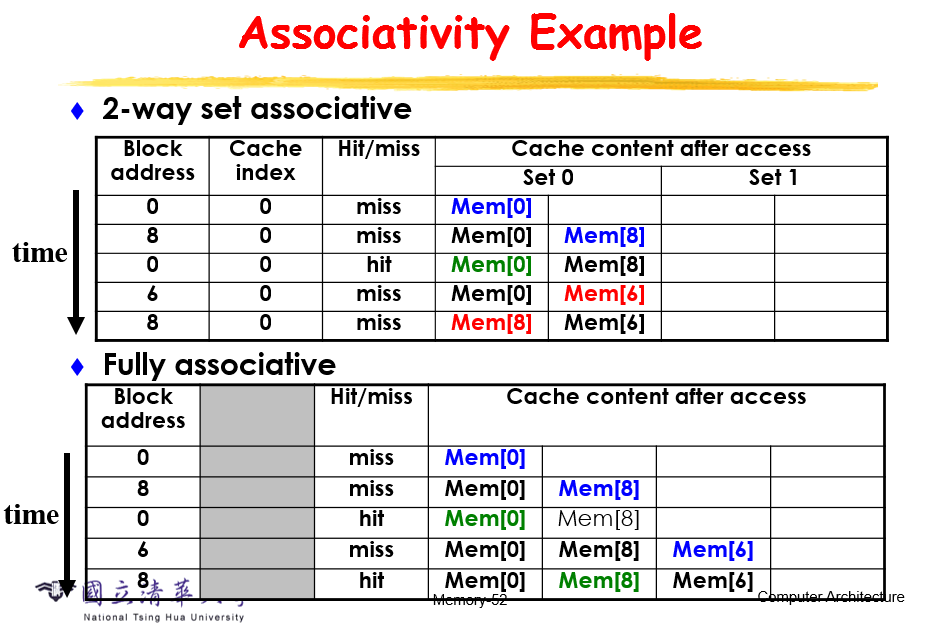
fully associate(成本高)
这两种比较极端
取一个中间的 set associate
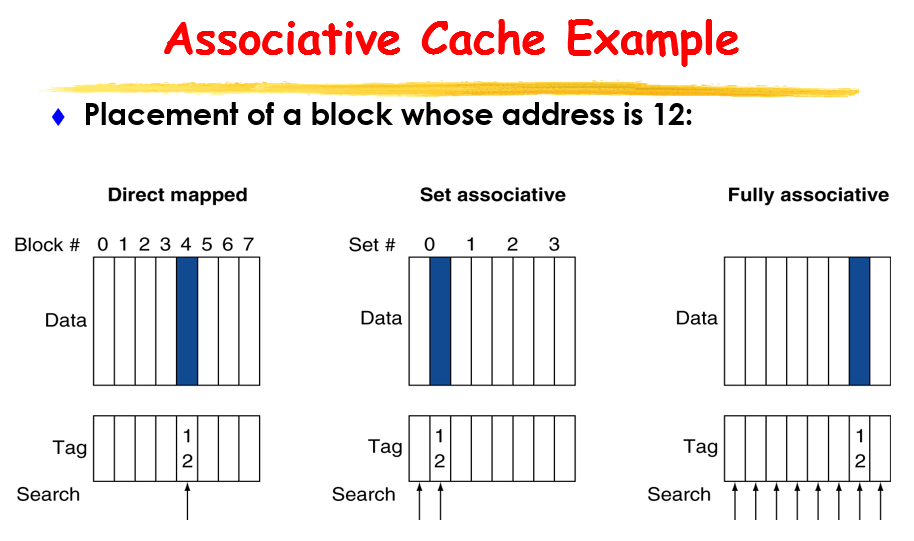
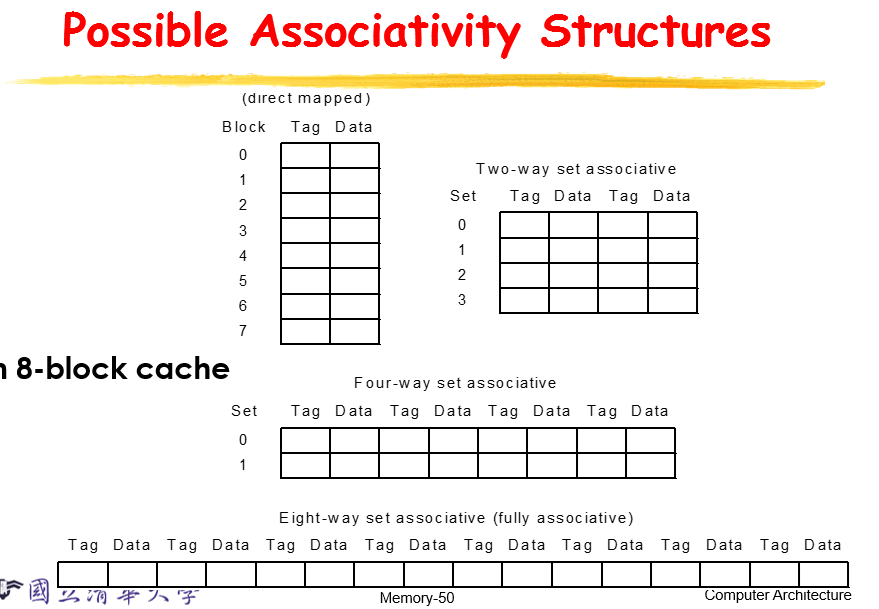
再次举例说明这三种的区别
多层cache,数量上增加:
第一层小而快,为了减少hit时间
第二层略大,为了减少miss概率
