特征工程
从数据中抽取出来的对预测结果有用的信息,通过专业的技巧进行数据处理,是的特征能在机器学习算法中发挥更好的作用。优质的特征往往描述了数据的固有结构。 最初的原始特征数据集可能太大,或者信息冗余,因此在机器学习的应用中,一个初始步骤就是选择特征的子集,或构建一套新的特征集,减少功能来促进算法的学习,提高泛化能力和可解释性。
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性。
特征工程的意义:
- 更好的特征意味着更强的鲁棒性
- 更好的特征意味着只需用简单模型
- 更好的特征意味着更好的结果
特征处理:
特征工程中最重要的一个环节就是特征处理,特征处理包含了很多具体的专业技巧
- 特征预处理
- 单个特征
- 归一化
- 标准化
- 缺失值
- 多个特征
- 降维
- PCA
- 降维
- 单个特征
特征工程之特征抽取与特征选择:
如果说特征处理其实就是在对已有的数据进行运算达到我们目标的数据标准。特征抽取则是将任意数据格式(例如文本和图像)转换为机器学习的数字特征。而特征选择是在已有的特征中选择更好的特征。后面会详细介绍特征选择主要区别于降维。
安装Scikit-learn机器学习库:
创建一个基于Python3的虚拟环境:
mkvirtualenv -p /usr/local/bin/python3.6 ml3
在ubuntu的虚拟环境当中运行以下命令
pip3 install Scikit-learn
数据的特征抽取
现实世界中多数特征都不是连续变量,比如分类、文字、图像等,为了对非连续变量做特征表述,需要对这些特征做数学化表述,因此就用到了特征提取. sklearn.feature_extraction提供了特征提取的很多方法
字典特征抽取
sklearn.feature_extraction.DictVectorizer(sparse = True)
将映射列表转换为Numpy数组或scipy.sparse矩阵
- sparse 是否转换为scipy.sparse矩阵表示,默认开启
方法:
fit_transform(X,y):应用并转化映射列表X,y为目标类型
inverse_transform(X[, dict_type]):将Numpy数组或scipy.sparse矩阵转换为映射列表
from sklearn.feature_extraction import DictVectorizer
# 字典特征抽取
d = DictVectorizer()
data = d.fit_transform([{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}])
# 获取特征名称
print(d.get_feature_names())
print(d.inverse_transform(data))
# 特征结果数据
print(data)
输出结果:
['city=上海', 'city=北京', 'city=深圳', 'temperature']
[{'city=北京': 1.0, 'temperature': 100.0}, {'city=上海': 1.0, 'temperature': 60.0}, {'city=深圳': 1.0, 'temperature': 30.0}]
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
如果按照数值来表示字典(例如1表示上海,2表示北京,3表示深圳),可能会对结果有较大的影响,上面的结果使用的是one-hot编码,如下:
| 北京 | 上海 | 深圳 | temperature | |
|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 100.0 |
| 1 | 1 | 0 | 0 | 60.0 |
| 2 | 0 | 0 | 1 | 30.0 |
文本特征抽取
文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
(1)文档的中词的出现次数:
数值为1表示词表中的这个词出现,为0表示未出现
sklearn.feature_extraction.text.CountVectorizer():将文本文档的集合转换为计数矩阵(scipy.sparse matrices)
方法:fit_transform(raw_documents,y)
学习词汇词典并返回词汇文档矩阵
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
data = cv.fit_transform(["life is short,i like python",
"life is too long,i dislike python"])
print(cv.get_feature_names())
print(data)
输出结果:
['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']
(0, 5) 1
(0, 3) 1
(0, 6) 1
(0, 1) 1
(0, 2) 1
(1, 0) 1
(1, 4) 1
(1, 7) 1
(1, 5) 1
(1, 1) 1
(1, 2) 1
对于中文文本进行特征抽取结果不理想,从下面的结果可以看出对于中文,只用逗号分隔符进行了分隔。对于中文应该先使用分词器进行分词,然后再使用分隔符进行连接就行了。
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
data = cv.fit_transform(["人生苦短,我喜欢python",
"人生太长,我不用python"])
print(cv.get_feature_names())
print(data)
输出结果:
['人生太长', '人生苦短', '我不喜欢python', '我不用python']
(0, 3) 1
(0, 1) 1
(1, 2) 1
(1, 0) 1
使用中文分词器来处理
from sklearn.feature_extraction.text import CountVectorizer
import jieba
cv = CountVectorizer()
content = ["人生苦短,我喜欢python", "人生太长,我不用python"]
content = [" ".join(list(jieba.cut(i, cut_all=True))) for i in content]
data = cv.fit_transform(content)
print(cv.get_feature_names())
print(data)
输出结果:
['python', '不用', '人生', '喜欢', '太长', '苦短']
(0, 0) 1
(0, 3) 1
(0, 5) 1
(0, 2) 1
(1, 1) 1
(1, 4) 1
(1, 0) 1
(1, 2) 1
(2)TF-IDF表示词的重要性:
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TfidfVectorizer会根据指定的公式将文档中的词转换为概率表示。
sklearn.feature_extraction.text.TfidfVectorizer()
方法:fit_transform(raw_documents,y),学习词汇和idf,返回术语文档矩阵。
from sklearn.feature_extraction.text import TfidfVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = TfidfVectorizer(stop_words='english')
print(vectorizer.fit_transform(content).toarray())
print(vectorizer.vocabulary_)
数据的特征预处理
特征处理是通过特定的统计方法(数学方法)将数据转换成算法要求的数据。
归一化
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义,其次可以程序可以运行更快。
特点:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
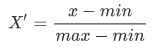
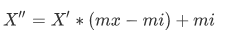
注:作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0。
MinMaxScalar(feature_range=(0, 1)
- 每个特征缩放到给定范围(默认[0,1])
- 方法:fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler(feature_range=(0, 1))
data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])
print(data)
输出结果:
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
标准化
通过对原始数据进行变换把数据变换到均值为0,方差为1范围内。
公式:
注:作用于每一列,mean为平均值,σ为标准差(考虑数据的稳定性)
std为方差,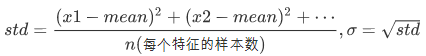
对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然 会发生改变。对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
StandardScaler(...):
- 处理之后每列来说所有数据都聚集在均值0附近方差为1
- StandardScaler.fit_transform(X,y)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
from sklearn.preprocessing import StandardScaler
s = StandardScaler()
data = s.fit_transform([[1., -1., 3.], [2., 4., 2.], [4., 6., -1.]])
print(data)
输出结果:
[[-1.06904497 -1.35873244 0.98058068]
[-0.26726124 0.33968311 0.39223227]
[ 1.33630621 1.01904933 -1.37281295]]
缺失值处理
由于各种原因,许多现实世界的数据集包含缺少的值,通常编码为空白,NaN或其他占位符。然而,这样的数据集与scikit的分类器不兼容,它们假设数组中的所有值都是数字,并且都具有和保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能是有价值的数据(即使不完整)的代价。更好的策略是估算缺失值,即从已知部分的数据中推断它们。
填充缺失值 使用sklearn.preprocessing中的Imputer类进行数据的填充
from sklearn.preprocessing import Imputer
import numpy as np
im = Imputer(missing_values="NaN", strategy="mean", axis=0)
data = im.fit_transform([[1, 2], [np.nan, 4], [5, np.nan]])
print(data)
输出结果:
[[1. 2.]
[3. 4.]
[5. 3.]]
特征选择
特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。
特征选择的原因:
-
冗余:部分特征的相关度高,容易消耗计算性能
-
噪声:部分特征对预测结果有负影响
降维本质上是从一个维度空间映射到另一个维度空间,特征的多少并没有减少,当然在映射的过程中特征值也会相应的变化。举个例子,现在的特征是1000维,我们想要把它降到500维。降维的过程就是找个一个从1000维映射到500维的映射关系。原始数据中的1000个特征,每一个都对应着降维后的500维空间中的一个值。假设原始特征中有个特征的值是9,那么降维后对应的值可能是3。而对于特征选择来说,有很多方法:
- Filter(过滤式):VarianceThreshold
- Embedded(嵌入式):正则化、决策树
- Wrapper(包裹式)
其中过滤式的特征选择后,数据本身不变,而数据的维度减少。而嵌入式的特征选择方法也会改变数据的值,维度也改变。Embedded方式是一种自动学习的特征选择方法,后面讲到具体的方法的时候就能理解了。
特征选择主要有两个功能:
(1)减少特征数量,降维,使模型泛化能力更强,减少过拟合
(2)增强特征和特征值之间的理解
sklearn特征选择API:sklearn.feature_selection.VarianceThreshold
删除所有低方差特征:VarianceThreshold(threshold = 0.0)
方法:VarianceThreshold.fit_transform(X,y)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:训练集差异低于threshold的特征将被删除。
- 默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
from sklearn.feature_selection import VarianceThreshold
var = VarianceThreshold(threshold=1.0)
data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])
print(data)
输出结果:
[[0]
[4]
[1]]
降纬
PCA(Principal component analysis),主成分分析。特点是保存数据集中对方差影响最大的那些特征,PCA极其容易受到数据中特征范围影响,所以在运用PCA前一定要做特征标准化,这样才能保证每维度特征的重要性等同。
本质:PCA是一种分析、简化数据集的技术
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
作用:可以削减回归分析或者聚类分析中特征的数量
PCA语法:
PCA(n_components=None)
- 将数据分解为较低维数空间
- PCA.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
from sklearn.decomposition import PCA
pca = PCA(n_components=0.9)
data = pca.fit_transform([[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]])
print(data)
输出结果:
[[ 1.28620952e-15 3.82970843e+00]
[ 5.74456265e+00 -1.91485422e+00]
[-5.74456265e+00 -1.91485422e+00]]