一、冒泡排序
1.原理
1.比较相邻的元素。如果第一个比第二个大,就交换它们两个
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数
3.针对所有的元素重复以上的步骤,除了最后一个
4.重复步骤1~3,直到排序完成
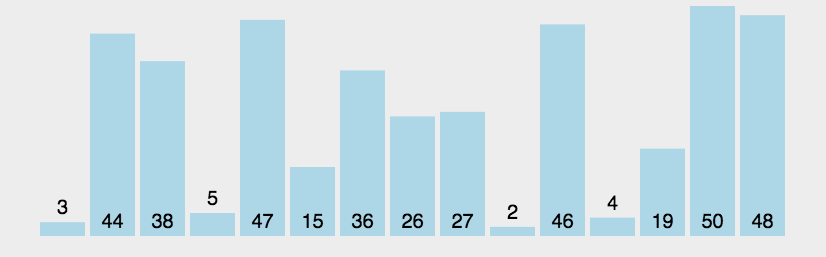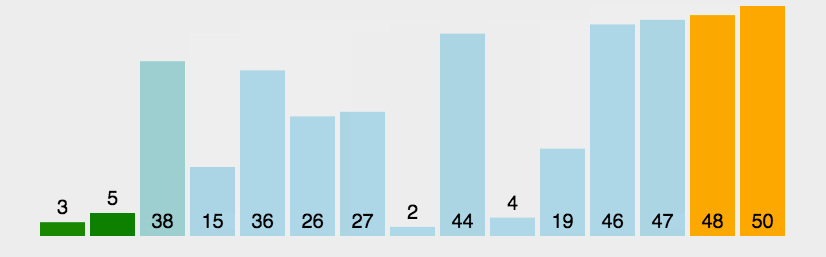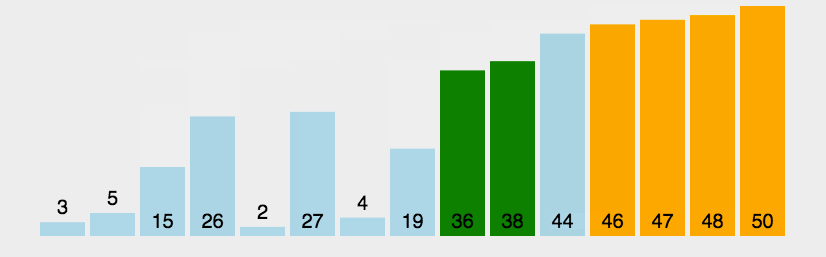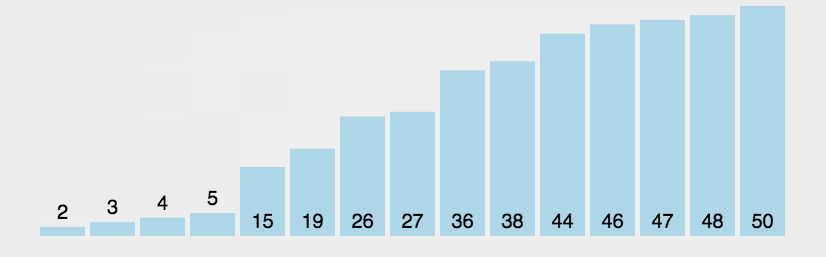
2.算法分析
冒泡排序的时间复杂度最好情况下为O(n),最坏情况下为O(n^2),平均时间复杂度为 O(n^2)
空间复杂度为O(1)
3.代码实现
#单个排序
def sort(alist):
for i in range(0,len(alist)-1):#循环n-1次,n就是列表元素的个数
if alist[i] > alist[i+1]:
alist[i],alist[i+1] = alist[i+1],alist[i]
print(alist)
alist = [3,8,5,7,6]
sort(alist)
#输出结果 [3,5,7,8]
# 完整版
def sort(alist):
for j in range(0,len(alist)-1):
for i in range(0,len(alist)-1-j):#循环n-1次,n就是列表元素的个数
if alist[i] > alist[i+1]:
alist[i],alist[i+1] = alist[i+1],alist[i]
return alist
alist = [3,8,5,7,6]
print(sort(alist))
# 输出结果 [3,5,6,7,8]
二、选择排序
1. 原理
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始(末尾)位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
2. 算法分析
插入排序的时间复杂度最好情况下为O(n2),最坏情况下为O(n2),平均时间复杂度为 O(n^2)
空间复杂度为O(1)
3.代码实现
# 我这里是将最大值 放置列表末尾
# 单个排序
def sort(alist):
max_index = 0 #最大值的下标,一开始假设第0个元素为最大值
for i in range(0,len(alist)-1):#为了找出最大值的下标
if alist[max_index] < alist[i+1]:
max_index = i+1
alist[max_index],alist[len(alist)-1] = alist[len(alist)-1],alist[max_index]
return alist
alist = [3,8,5,7,6]
print(sort(alist))
# 输出结果
[3, 6, 5, 7, 8]
#将上述操作在逐步的作用(n-1次)
def sort(alist):
for j in range(0,len(alist)-1):
max_index = 0 #最大值的下标,一开始假设第0个元素为最大值
for i in range(0,len(alist)-1-j):#为了找出最大值的下标
if alist[max_index] < alist[i+1]:
max_index = i+1
alist[max_index],alist[len(alist)-1-j] = alist[len(alist)-1-j],alist[max_index]
return alist
alist = [3,8,5,7,6]
print(sort(alist))
# 输出结果
[3, 5, 6, 7, 8]
三、插入排序
1. 原理
从第一个元素开始,该元素可以认为已经排好序,取下一个,在已经排好序的序列中向前扫描,有元素大于这个新元素,将已经在排好序中的元素移到下一个位置,依次执行。
2. 算法原理
插入排序的时间复杂度最好情况下为O(n),最坏情况下为O(n^2),平均时间复杂度为 O(n^2)
空间复杂度为O(1)
3. 代码实现
#有序序列只有一个元素,无序序列元素个数为n-1
i = 1
#alist[i-1]:有序序列的最后一个元素
#alist[i]:无序序列的第一个元素
if alist[i] < alist[i-1]:
alist[i],alist[i-1] = alist[i-1],alist[i]
i = 2 #有序序列有两个元素
#alist[i]:无序序列的第一个元素
#alist[i-1]:有序序列的最后一个元素
while i >= 1:
if alist[i] < alist[i-1]:
alist[i],alist[i-1] = alist[i-1],alist[i]
i -= 1
else:
break
#完整代码:自动处理i(1:len-1)
def sort(alist):
for i in range(1,len(alist)):
while i >= 1:
if alist[i] < alist[i-1]:
alist[i],alist[i-1] = alist[i-1],alist[i]
i -= 1
else:
break
return alist
alist = [49,38,65,97,76,13,27]
print(sort(alist))
# 输出结果
[13, 27, 38, 49, 65, 76, 97]
四、希尔排序
1.原理
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本,该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量(gap)”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率比直接插入排序有较大提高。

2. 算法原理
希尔排序的时间复杂度最好情况下为O(nlog2n),最坏情况下为O(n2),平均时间复杂度为 O(nlogn)
空间复杂度为O(1)
3.代码实现
# 第一次分组
def sort(alist):
gap = len(alist)//2 #分组
#将下属所有的1换成gap
for i in range(gap,len(alist)):
while i >= gap:#判断条案件
if alist[i] < alist[i-gap]:#判断组里两个值就行排序
alist[i],alist[i-gap] = alist[i-gap],alist[i]
i -= gap
else:
break
return alist
alist=[49,38,65,97,76,13,27]
sort(alist)
# 输出结果
[27, 38, 13, 49, 76, 65, 97]
#完整代码
#缩减增量
def sort(alist):
gap = len(alist)//2
while gap >= 1:
#将下属所有的1换成gap
for i in range(gap,len(alist)):
while i >= gap:
if alist[i] < alist[i-gap]:
alist[i],alist[i-gap] = alist[i-gap],alist[i]
i -= gap
else:
break
gap //= 2 #缩减增量
return alist
alist = [49,38,65,97,76,13,27]
print(sort(alist))
# 输出结果
[13, 27, 38, 49, 65, 76, 97]
五、快速排序
1. 原理
定义一个数组,找X,然后将数组跟X比大小排列。我没有研究哪一个当标杆好,不如就选第一个数字吧。

选择第一个数字为“标杆数”
下面我们就要依据“标杆数”,也就是数字“5”(其序数为0),对其余部分进行分堆了。我们想分为“<=5”与“>5”的两部分,并使前者位于左侧,后者位于右侧,操作步骤如下:
1. 命名左侧序数为 i,初始 i = 1;命名右侧序数为 j,初始 j = len(data)-1(即最后一位)。

初始化i、j
2. 让j开始移动并进行判断:
- 若j所在的数字<=5,则让i开始向右移动,直到i所在的数字>5,接着交换data中i, j所对应的数字,即:
data[i], data[j] = data[j], data[i]


- 若j所在数字>5,则忽略,继续向左移动。

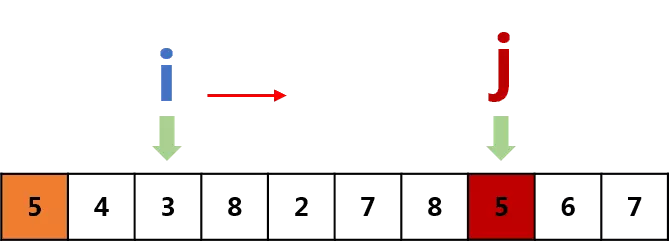


3. 当 j == i 时,意味着交换结束,列表除了首位的“标杆数”,其余部分分为<=5和>5两堆,那么我们还应该把“5”放到这两堆中间,让列表看上去更有序。即:
data[0], data[j] = date[j], data[0]



注意:如果j此时不在列表中间呢,比如由于数据特殊,j最终停在在首、尾处呢?

不能交换

可以交换
考虑到这一点,我们就可以意识到,要做的是把一开始找的标杆放到应有的位置上,即最后一个<=5的数的位置。因此,我们在交换前加一个判断:
if data[j] <= data[0]:
data[0], data[j] = data[j], data[0]
4. 结束操作,返回此时的data。
以上部分讲的是单次排序的(啰嗦)细节,整个快速排序是若干次单次排序的递归,下面讲解一下递归部分:
首先简化模型,我们把不直观的“数字比大小”转换为直观的“图形排序”,将data中的“标杆数5”及<=5的数替换为“☻”,将>5的数替换为“█”,则有:


接着,用上述的i,j排序规则操作一遍之后,得到:

是不是清晰许多?
进行递归,我们要做的就是把分大小排序的data拆分为两个data,分界线即为“标杆数”,然后分别对两个拆分data排序,直至抵达递归的回归条件(len(data) <= 1即终止)。
对示例列表进行快速排序的原理如下:

2.算法原理
快速排序的时间复杂度最好情况下为O(nlogn),最坏情况下为O(n^2),平均时间复杂度为 O(nlogn)
空间复杂度为O(logn)
3.代码实现
#将基数放置到合适的位置:基数左侧为比基数小的数值,基数右侧为比基数大的数值
# 传入 数组、初始值、终值
def sort(alist,start,end):
#头
low = start
#尾
high = end
# 如果头大于尾 结束
if low > high:#结束递归的条件
return
# 标杆
mid = alist[low]#基数
while low < high:# 头小于尾
while low < high:# 头小于尾
if alist[high] > mid:# 如果尾大于标杆
high -= 1#high向左偏移
else:
# 否则 将头和尾互换
alist[low] = alist[high]
break
while low < high:# 头小于尾
if alist[low] < mid:# 如果头小于标杆
low += 1# 向右移动
else:
# 否则 将头和尾互换
alist[high] = alist[low]
break
if low == high:# 如果头尾相等
alist[low] = mid#标杆为 中间值
#递归
sort(alist,start,high-1)#处理基数左部分的乱序序列
sort(alist,low+1,end)#处理基数右部分的乱序序列
return alist
alist = [49,38,65,97,76,13,27]
print(sort(alist,0,len(alist)-1))
#输出结果
[13, 27, 38, 49, 65, 76, 97]