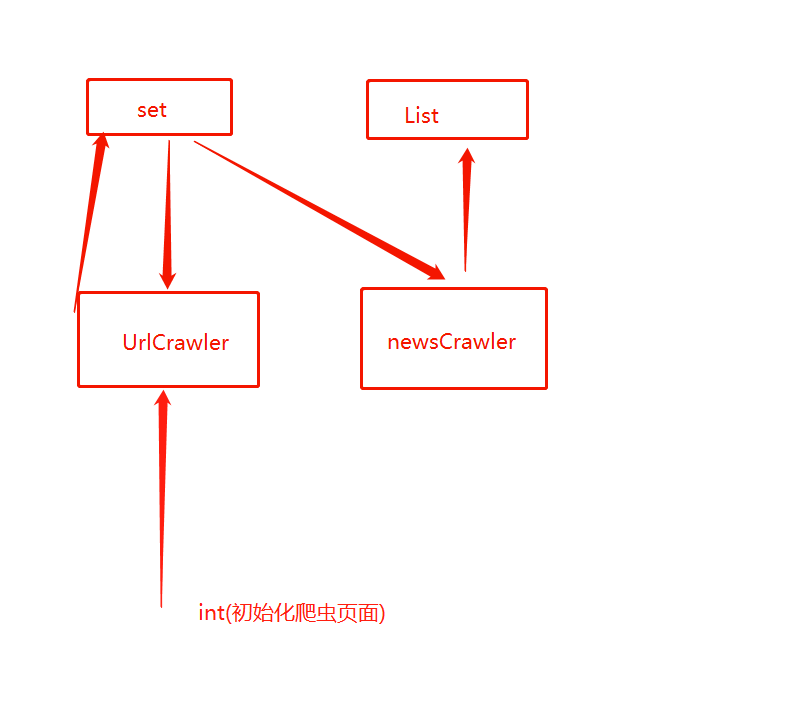
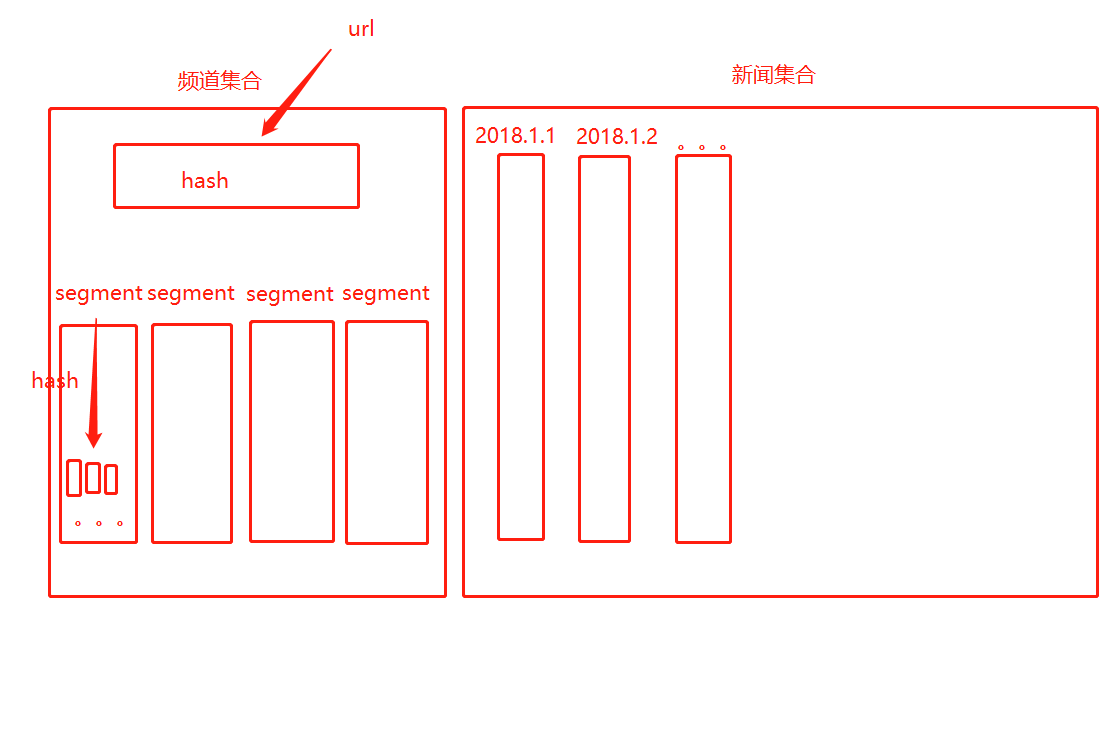
凤凰新闻爬虫实现 凤凰新闻爬虫实现 凤凰新闻扒取爬虫第一版 第一版已经正常运行,但是会出现一些问题: 1. set是存放链接的集合,它会越来越大 2. 因为链接的集合越来越大,造成从集合中查到链接越来越费时间 为了解决这一问题,现在将存放链接的集合拆分为多个集合: