1 顺序查找
全局索引查找 乱序列表适用 缺点就是列表所有元素都要遍历
def search(alist,item): find = False cur = 0 #遍历下标 while cur < len(alist): #确定循环次数用for 不确定的话用while if alist[cur] == item: find = True break else: cur += 1 return find alist = [1, 3, 5, 2, 7, 8] print(search(alist,6))
有序列表的 有限次数索引查找 核心就是找到了后面的元素就不遍历了 提高了查找的效率
def search(alist,item): find = False cur = 0 while cur < len(alist): if alist[cur] == item: find = True break elif item < alist[cur]: break else: cur += 1 return find alist = [10, 20, 33, 55, 77, 99, 110] print(search(alist,7))
2 二分查找
有序列表对于我们的实现搜索是很有用的。在顺序查找中,当我们与第一个元素进行比较时,如果第一个元素不是我们要查找的,则最多还有 n-1 个元素需要进行比较。 二分查找则是从中间元素开始,而不是按顺序查找列表。 如果该元素是我们正在寻找的元素,我们就完成了查找。 如果它不是,我们可以使用列表的有序性质来消除剩余元素的一半。如果我们正在查找的元素大于中间元素,就可以消除中间元素以及比中间元素小的一半元素。如果该元素在列表中,肯定在大的那半部分。然后我们可以用大的半部分重复该过程,继续从中间元素开始,将其与我们正在寻找的内容进行比较。
二分查找 先定位到最中间的元素,奇数就是本身, [left .. .. .. right] def search(alist,item): left = 0 #下标 right = len(alist)-1 #下标 find = False #标识 while left <= right: mid_index = (left+right)//2 #取中间值的索引 if item == alist[mid_index]: find = True break else: if item > alist[mid_index]: #往右比较 left = mid_index + 1 else: #往左比较 right = mid_index - 1 left = left return find alist = [10,12,22,33,44] print(search(alist,12))
3 冒泡
原理: 默认升序, 原始列表元素拿出来两两比较,大的往后走,直到最后 -- 最终排好序了
a = [8,3,5,7,6] def sort(alist): length = len(alist) for j in range(0,length-1):
for i in range(0,length-1-j): #内层循环 if alist[i] > alist[i+1]: #左>右 交换赋值 alist[i],alist[i+1] = alist[i+1],alist[i] sort(a) print(a)
4 选择排序
原理 : 一次找到最大值,放到适当的位置 减少了数据交换次数
a = [8,33,51,7,6] def sort(alist): length = len(alist) for j in range(length-1,0,-1): #[5, 4, 3, 2, 1] max_index = 0 # 最大值元素的下标 for i in range(1,j+1): if alist[max_index] < alist[i]: max_index = i alist[max_index], alist[j] = alist[j], alist[max_index] #交换位置 sort(a) print(a)
5 插入排序
#插入排序 红色是核心代码 a = [49,38,65,97,76,13,27] #分2部分 49(表示有序列表)//...(乱序表每个元素一次插入到有序表里合适位置) def sort(alist): length = len(alist) #长度 for j in range(1,length): #38,65,97,76,13,27 i = j # i就是无序列表中的第一个元素 while i>0: #内层循环 要判断和交换数据 if alist[i] < alist[i-1]: alist[i],alist[i-1] = alist[i-1],alist[i] i -= 1 else: break sort(a) print(a)
6 希尔排序 缩小增量排序 用到了 - 间隔
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本,该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量(gap)”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率比直接插入排序有较大提高
#希尔排序 gap 间隔 一种特殊的插入排序 是插入排序的时间复杂度1.3倍左右 a = [3,8,5,7,6,1,99] def sort(alist): gap = len(alist) // 2 while gap >= 1: #不确定循环次数 for j in range(gap, len(alist)): i = j # i就是无序列表中的第一个元素 while i>0: if alist[i] < alist[i-1]: #[8,3] alist[i],alist[i-gap] = alist[i-gap],alist[i] i -= gap else: break gap = gap//2 #增量 缩小 sort(a) print(a)
7 快排 快速排序 Quicksort 是对冒泡排序的一种改进
原理 : 比mid小,放左边, 比mid大,放右边
基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
# [start/low .. .. .. end/high] alist = [1,2,3,2,3,6,7,4,8,9,77,4,55] def sort(alist,start,end): low = start high = end if low >= high: return mid = alist[low] #列表中第一个元素 while low < high: while low < high: if alist[high] >= mid: high -= 1 #向左偏移 else: alist[low] = alist[high] #结束该侧循环 break while low < high: if alist[low] < mid: low += 1 #向右偏移 else: alist[high] = alist[low] break alist[low] = mid #核心 中间值的存放 sort(alist,start,low-1) # 在mid左侧列表中递归调用该函数 左边都是小的 sort(alist,high+1,end) # mid右侧 右边都是大的 sort(alist,0,len(alist)-1) print(alist)
两个原理links: https://blog.csdn.net/nrsc272420199/article/details/82587933 https://blog.csdn.net/qq_33404395/article/details/80358241
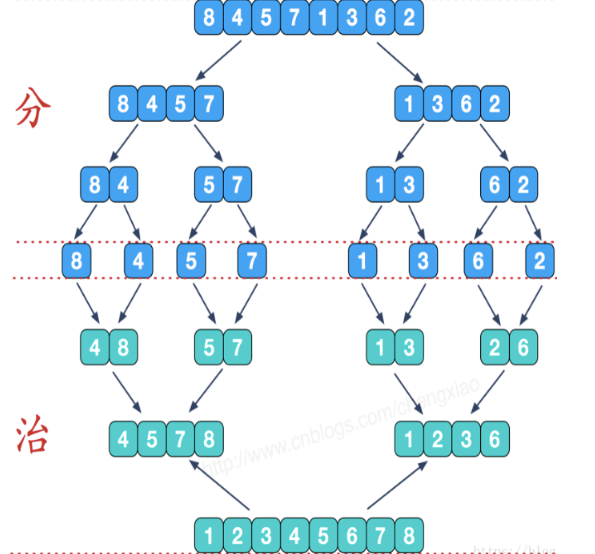
8 归并
- 归并排序采用分而治之的原理: - 将一个序列从中间位置分成两个序列; - 在将这两个子序列按照第一步继续二分下去; - 直到所有子序列的长度都为1,也就是不可以再二分截止。这时候再两两合并成一个有序序列即可。 - 如何合并? 下图中的倒数第三行表示为第一次合并后的数据。其中一组数据为 4 8 , 5 7。该两组数据合并方式为:每一小组数据中指定一个指针,指针指向每小组数据的第一个元素,
通过指针的偏移指定数据进行有序排列。排列情况如下: 1. p1指向4,p2指向5,p1和p2指向的元素4和5进行比较,较小的数据归并到一个新的列表中。经过比较p1指向的4会被添加到新的列表中,则p1向后偏移一位,指向了8,p2不变。 2.p1和p2指向的元素8,5继续比较,则p2指向的5较小,添加到新列表中,p2向后偏移一位,指向了7。 3.p1和p2指向的元素8,7继续比较,7添加到新列表中,p2偏移指向NULL,比较结束。 4.最后剩下的指针指向的数据(包含该指针指向数据后面所有的数据)直接添加到新列表中即可。
def merge_sort(alist): n = len(alist) #结束递归的条件 if n <= 1: return alist #中间索引 mid = n//2 left_li = merge_sort(alist[:mid]) right_li = merge_sort(alist[mid:]) #指向左右表中第一个元素的指针 left_pointer,right_pointer = 0,0 #合并数据对应的列表:该表中存储的为排序后的数据 result = [] while left_pointer < len(left_li) and right_pointer < len(right_li): #比较最小集合中的元素,将最小元素添加到result列表中 if left_li[left_pointer] < right_li[right_pointer]: result.append(left_li[left_pointer]) left_pointer += 1 else: result.append(right_li[right_pointer]) right_pointer += 1 #当左右表的某一个表的指针偏移到末尾的时候,比较大小结束,将另一张表中的数据(有序)添加到result中 result += left_li[left_pointer:] result += right_li[right_pointer:] return result alist = [3,8,5,7,6,0,12,66,22] print(merge_sort(alist))