在MongoDB中,聚合(aggregate)主要用于处理数据(比如统计平均值、求和等),返回计算后的数据结果。
aggregate 语法
aggregate() 方法的基本语法格式如下所示:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
简单用法
1、集合中的数据如下:

2、使用 aggregate() 计算每个作者所写的文章数 —— 使用表达式 “$sum : 1” 计算每个作者对应的文档数。如下:

以上实例类似sql语句: select by_user, count(*) from mycol group by by_user
在上面的例子中,我们通过字段by_user字段对数据进行分组,并计算by_user字段相同值的总和。
MongoDB 聚合表达式
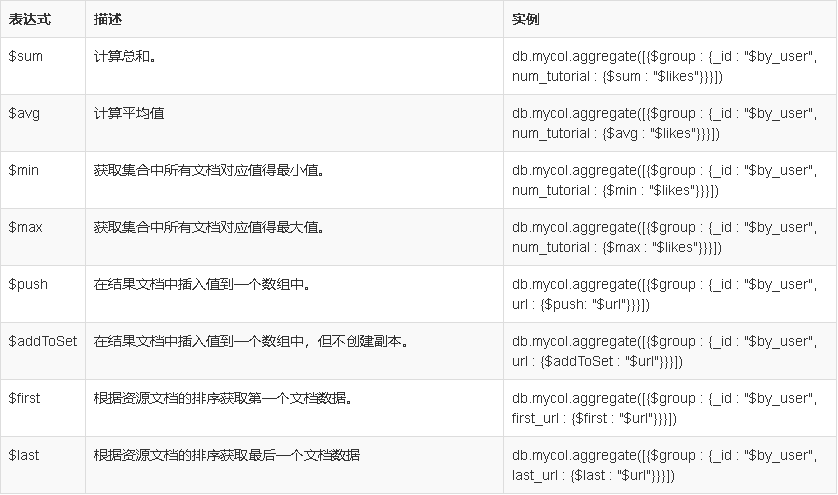
高级用法 -- 管道
管道概念:在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的输入参数。
MongoDB的聚合(aggregate)管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。
1、MongoDB 聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
2、管道操作符实例
db.resume.aggregate( [ {$match:{delete_status:false,work_experiences:{$ne:null}}}, {$sort:{"refresh_time":-1}}, {$project:{"work_experiences":{$slice:["$work_experiences", -1]},count:{$size:'$work_experiences'}}}, {$match:{count:{$gt:1}}}, {$match:{"work_experiences.industry":/^02./}}, {$project:{_id:1}} ])
参考文档:https://www.mongodb.org.cn/tutorial/33.html
$slice 说明:http://www.javashuo.com/article/p-qnlhnyqv-ez.html