转载请注明出处http://www.cnblogs.com/zhangcaiwang/p/6886037.html
以前都没有正儿八经地看过英文类文档,神经网络方面又没啥基础,结果第一章就花费了我将近一周的晚上。不过还是有收获的,希望英文阅读水平越来越高吧。
上一章讲解了神经网络如何通过梯度下降学习权重和偏差,但是没有讲解代价函数(cost function)的梯度是怎么求解的。本章中主要讲解一个用来计算代价函数梯度的快速算法:反向传播(backpropagation)算法。
Warm up: a fast matrix-based approach to computing the output from a neural network
定义![]() 表示第(l-1)层的第k个神经元到第l层的第j个神经元的权重。
表示第(l-1)层的第k个神经元到第l层的第j个神经元的权重。![]() 表示第l层的第j个神经元的bias。
表示第l层的第j个神经元的bias。![]() 表示地l层的第j个神经元的激活值。
表示地l层的第j个神经元的激活值。
接下来我们要把下面的等式向量化:
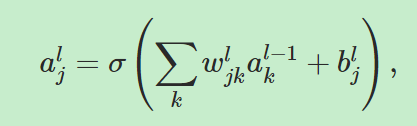 =====》
=====》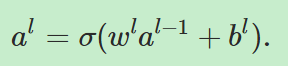
其中al表示第l层网络的神经元的激活值构成的向量,wl、bl同理。其中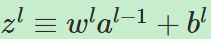 被称为加权输入(weighted input).
被称为加权输入(weighted input).
The two assumptions we need about the cost function
第一个假设是,损失函数可以写为单个训练样例(x1,x2,x3,x4,...,xn)的损失函数的平均值,也就是:![]() ,这个假设在本系列文章中的其他损失函数中同样成立。我们做这个假设的原因是因为反向传播实际上让我们计算的是
,这个假设在本系列文章中的其他损失函数中同样成立。我们做这个假设的原因是因为反向传播实际上让我们计算的是![]() ,然后我们通过对每一个训练样例做平均来得到
,然后我们通过对每一个训练样例做平均来得到![]() 。
。
第二个假设是,损失函数可以写成神经网络的输出的函数,如下所示:
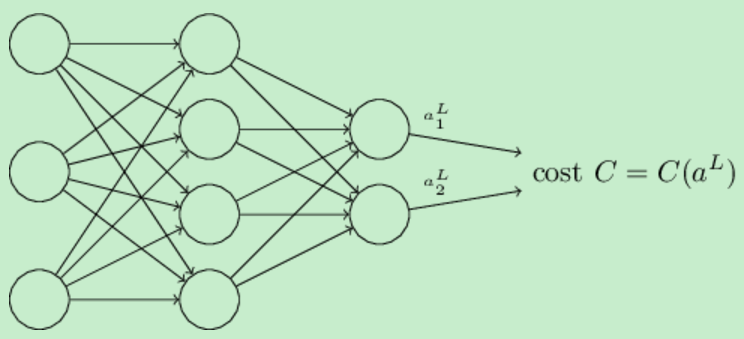
比如说二次损失函数(quadratic cost function)就满足这个要求,因为对于一个训练样例x的损失函数可以被写成![]() ,而它正是输出激活值的函数。
,而它正是输出激活值的函数。
The Hadamard product, s⊙t
Hadamard乘积是用来定义向量之间的乘积。向量s和向量t的乘积的结果仍为一个向量,且元素为sjtj,也就是有![]() 比如:
比如:
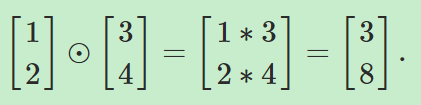
反向传播的四个基本方程
理解反向传播就是理解改变权重和bias是如何影响损失函数的。最终,这意味着计算![]() ,为了计算它们,我们要先引入一个中间量
,为了计算它们,我们要先引入一个中间量![]() ,它被称为第l层的第j个神经元的误差。定义:
,它被称为第l层的第j个神经元的误差。定义:
公式一,输出层误差公式:
 ------------------------>输出层单个神经元误差
------------------------>输出层单个神经元误差
 ------------->输出层误差向量形式,
------------->输出层误差向量形式,![]() 是偏导数
是偏导数![]() 的向量。
的向量。
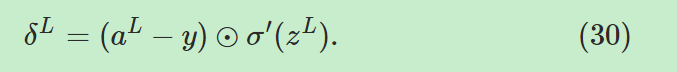 ------------->输出层误差向量形式。如果单个神经元对单个输入样例的损失函数有
------------->输出层误差向量形式。如果单个神经元对单个输入样例的损失函数有![]() 的形式,那么很容易有
的形式,那么很容易有![]() 。
。
公式二,误差传递公式:
![]() 。对于这个公式的前一部分
。对于这个公式的前一部分![]() ,我们可以直观地认为当误差通过网络反向传播时
,我们可以直观地认为当误差通过网络反向传播时
它给了我们一种测量第l层神经元误差的方式。第二部分![]() 把误差又进行反向传播并通过了激励函数,这样我们就得到了第l层加权输入中的误差。通过公式一和公式二,我们可以计算任意一层的误差,由公式一我们可以得到第L层的误差,用公式二反向传播可以获得l-1层的误差。依次向下进行。。。
把误差又进行反向传播并通过了激励函数,这样我们就得到了第l层加权输入中的误差。通过公式一和公式二,我们可以计算任意一层的误差,由公式一我们可以得到第L层的误差,用公式二反向传播可以获得l-1层的误差。依次向下进行。。。
公式三,损失函数对网络中bias的偏导公式:
 ,这就是说
,这就是说![]() 实际上等于损失函数的改变率
实际上等于损失函数的改变率![]() 。该公式可以重写如公式(31):
。该公式可以重写如公式(31):
 ,它的意思是说某一神经元的δ值由该神经元的bias值表示。
,它的意思是说某一神经元的δ值由该神经元的bias值表示。
公式四,损失的改变率与网络中的权重的等式:
 ,这个公式表明了,如何通过a和δ计算
,这个公式表明了,如何通过a和δ计算![]() 。它可以被简化重写如(32):
。它可以被简化重写如(32):
 ,用图表示就是
,用图表示就是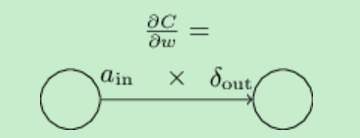 。公式(32)表明,当ain很小的时候,损失函数对权重的偏导数也会很小,我们称之为学习慢(learn slowly),也就是说从低激发值神经元深处的权重学习慢。
。公式(32)表明,当ain很小的时候,损失函数对权重的偏导数也会很小,我们称之为学习慢(learn slowly),也就是说从低激发值神经元深处的权重学习慢。
由以上分析可知,反向传播通过δ来计算代价函数对权重和偏置的偏导数,进而可以通过梯度下降推导出的公式对权重进行更新。反向传播算法的意义就在于不用通过对权重和bias真正求出偏导数,这省去了很大的麻烦。