https://www.jianshu.com/p/aebcaf8af76e
1、sgd
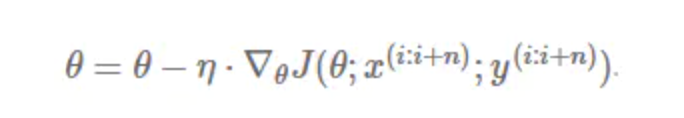
2、动量(Momentum)

3、adagrad

大多数的框架实现采用默认学习率α=0.01即可完成比较好的收敛。
4、RMSprop
 ,
,
其中:

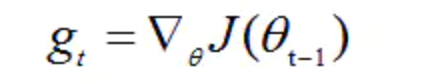
γ是遗忘因子(或称为指数衰减率),依据经验,默认设置为0.9。
5、adam
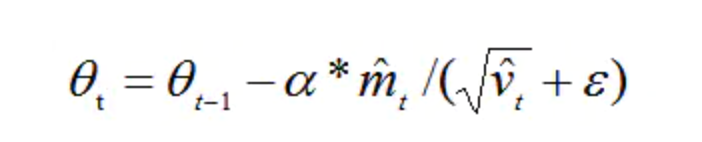 ,
,
其中:
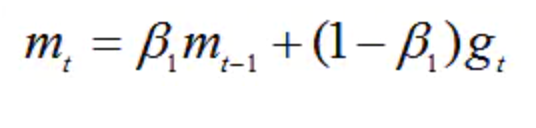
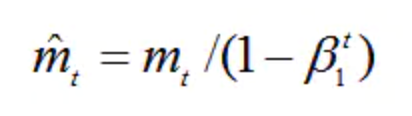
m0 初始化为0。
β1 系数为指数衰减率,控制权重分配(动量与当前梯度),通常取接近于1的值。
默认为0.9。
由于m0初始化为0,会导致mt偏向于0,尤其在训练初期阶段。
所以,此处需要对梯度均值mt进行偏差纠正,降低偏差对训练初期的影响。 vt同理。
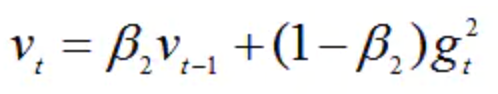

v0初始化为0。
β2 系数为指数衰减率,控制之前的梯度平方的影响情况。
类似于RMSProp算法,对梯度平方进行加权均值。
默认为0.999
