安装jdk1.7
http://www.cnblogs.com/zhangXingSheng/p/6228432.html
-------------------------------------------------------------
新增个域名
[root@node4 sysconfig]# more /etc/hosts
127.0.0.1 localhost
192.168.177.124 hadoop-node4.com node4
[root@node4 sysconfig]#
修改主机名
[root@node4 sysconfig]# more network
NETWORKING=yes
HOSTNAME=node4
[root@node4 sysconfig]#
配置hadoop环境变量(vi /etc/profile)
###############hadoop################ export HADOOP_HOME=/usr/local/development/hadoop-2.6.4 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1:配置hadoop.env.sh,配置javahome (文件路径:/usr/local/development/hadoop-2.6.4/etc/hadoop)
export JAVA_HOME=/usr/local/development/jdk1.7.0_15
2: yarn-env.sh 修改javahome变量 (文件路径:/usr/local/development/hadoop-2.6.4/etc/hadoop)
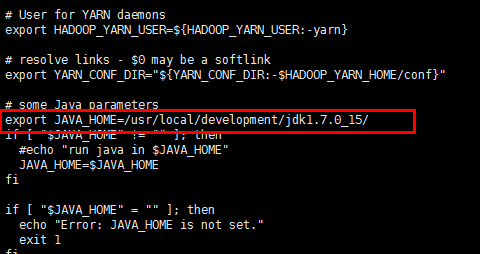
3:修改slave文件,里面默认是localhost,修改为你的全域名,或者主机名( 文件路径:/usr/local/development/hadoop-2.6.4/etc/hadoop)
[root@node4 hadoop]# more slaves
node4
[root@node4 hadoop]#
4:core.site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> //配置hadoop运行时临时文件的目录位置 <value>file:/home/zhangxs/data/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://hadoop-zhangxs.com:9000</value>//配置nameNode的端口 </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration>
5:hdsf.site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value>//存储文件的副本数 </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/zhangxs/data/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/zhangxs/data/hadoop/tmp/dfs/data</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
6:修改mapred.site.xml(这个文件默认是没有的,可以复制同目录下mapred.site.xml.template文件,并重命名为 mapred.site.xml)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-zhangxs.com:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-zhangxs.com:19888</value> </property> </configuration>
7:配置yarn.site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-zhangxs.com</value> </property> <property> //nodeManager上运行的附属服务,需要配置mapreduce_shuffle才可以运行mapreduce程序 <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
8:启动并验证hadoop
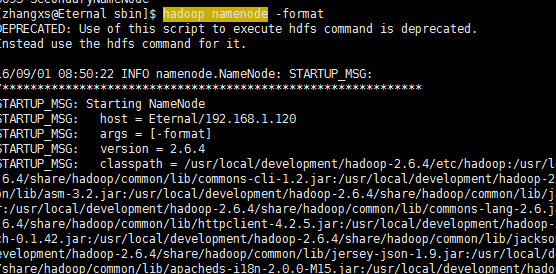
8-1:格式化hdfs文件系统(hadoop namenode -format)
8-2:启动start.dsf.sh start yarn.sh
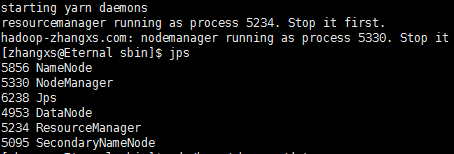
8-3:输入jps,查看运行进程
8-1 格式化hdfs文件系统(hadoop namenode -format)
8-2 启动start.dsf.sh start yarn.sh
8-3 输入jps,查看运行进程
可以通过页面访问
http://192.168.177.124:50070 hdfs文件管理
http://192.168.177.124:8088 ResourceManager
-----------------------------------------------------------------------
如果页面访问不到,把linux的防火墙关闭
service iptables stop//这个只是暂时关闭,系统重启后失效