Python
先编译一个中间的字节码,然后再由解释器根据中间的字节码再次去解释执行
Python解释器在执行任何一个Python程序文件时,首先进行的动作都是先对文件中的Python源代码进行编译,编译的主要结果是产生的一组Python的字节码,然后将编译的结果交给Python虚拟机,由虚拟机按照顺序一条一条地执行字节码,从而完成对Python程序的执行动作。
# -*- coding: utf-8 -*-
python中一切皆是对象: 不论是是变量还是字面量(直接量)
id Type Valua
格式输出: 你想打印一个字符串加数字 直接用字符串方式来解决
a = 'asdfasf' b = 123 print(a+str(b)) #这样的代码不优雅,并且有时候忘了格式转换会出错 !!!!!只能将str(而不是“int”)连接到str
print('%s, %s' % (a,b)) #如果用格式输出就好多了

pyc:
- 持久化:提升下次的执行效率
- import中作为工具,不经常改
- 还可以保护源码
- 没import不会走pyc
 手动持久化操作
手动持久化操作
Python 中的变量赋值不需要类型声明。
10**20 = 1020
if 12>10: print("yes") else: print("no")
for:
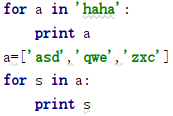
# 遍历 0 到 4
for i in range(5): print(i)
while:
a=1 while a<10: print a #输出1~9 a+=1 #python中没有++ --
列表(List):[]
删除列表:del list[2]
一个完整的切片表达式包含两个“:”,用于分隔三个参数(start_index、end_index、step),当只有一个“:”时,默认第三个参数step=1。

>>>a[:-6]
>>> [0, 1, 2, 3]
step=1,从左往右取值,从“起点”开始一直取到end_index=-6。元祖(Tuple):() 类似列表,不可更改
元组中只包含一个元素时,需要在元素后面添加逗号:a=(50,)
元组 tuple() 函数将列表转换为元组 字典返回键的值
字典(Dict):{} 键值
集合(Set):{} 无序、无重、不可变
输入:
name=input('请输入用户名字:')
print("a",end="a") print("a")
#输出aaa
#默认end=" " 改了就不换行了
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
a=" " b=['a','b','c'] print (a.join(b)) #输出 a b c
函数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict


加*表示接受一个tuple类型(元组)
加**表示接受一个dict类型(字典)
def f(**kargs): print(kargs) f(a=1, b=2) {'a': 1, 'b': 2}
面向对象
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法。
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
类的私有属性:__private_attrs __(2个) 注:实例不能访问私有变量
Python不允许实例化的类访问私有数据,但你可以使用 object._className__attrName( 对象名._类名__私有属性名 )访问属性 前面1个_后面2个__
模块:一组功能的集合体,我们的程序可以导入模块来复用模块里的功能。
__name__
内置变量,用于表示当前模块的名字,同时还能反映一个包的结构。 如:python -c "import asdasd.zx"
问题
data = [randint(-10,10) for _ in range(10)] #生成随机数
d={x:randint(60,100) for x in range(1,21)} #1~20 (不包括21)
乱七八糟
python中for _ in range(10)与for i in range(10)有何区别?
-
下划线表示 临时变量, 仅用一次,后面无需再用到
isinstance() 函数来判断一个对象是否是一个已知的类型
split() 通过指定分隔符对字符串进行切片
正则
. 匹配除换行符 之外的任何单字符
d 等同于[0-9]
w 等同于[a-z0-9A-Z_]匹配大小写字母、数字和下划线
import re
key = r"chuxiuhong@hit.edu.cn"
p = r"@.+?."#我想匹配到@后面一直到“.”之间的,在这里是hit
pattern = re.compile(p)
print( pattern.findall(key)) #['@hit.']
import re
key = r"<html><body><h1>hello world</h1></body></html>"#这段是你要匹配的文本
p1 = r"(?<=<h1>).+?(?=</h1>)"#这是我们写的正则表达式规则,你现在可以不理解啥意思
pattern1 = re.compile(p1)#我们在编译这段正则表达式
matcher1 = re.search(pattern1,key)#在源文本中搜索符合正则表达式的部分
print(matcher1.group(0))
#第一个?<=表示在被匹配字符前必须得有<h1>,后面的?=表示被匹配字符后必须有</h1>
p1 = r"(?<=<h1>).+?(?=<h1>)"
正则表达式默认是“贪婪”的 +? 解决
子表达式:几个字符的组合形式看做一个大的“字符”
回溯引用
-
p1 = r"<h([1-6])>.*?</h1>"
-
原本那个位置应该是
[1-6],但是我们写的是1 -
转义符
干的活就是把特殊的字符转成一般的字符,把一般的字符转成特殊字符。 -
普普通通的数字1被转移成什么了呢?
-
在这里1表示第一个子表达式,也就是说,它是动态的,是随着前面第一个子表达式的匹配到的东西而变化的。
-
比方说前面的子表达式内是
[1-6],在实际字符串中找到了1,那么后面的1就是1,如果前面的子表达式在实际字符串中找到了2,那么后面的1就是2。
python3
取消xrange
取消iteritems() 用 items()替换iteritems()
items() 将字典中的所有项,以列表方式返回
扩展功能
[(x,y)for x in [1,2]for y in [3,4]]
#[(1, 3), (1, 4), (2, 3), (2, 4)]
M = [[x, x+1, x+2] for x in [1, 4, 7]]
#[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
a={x ** 2 for x in [1, 2, 2]}
#{1, 4} for前面是输出的格式
随机数
import random
random.randrange(100, 1000, 2) # 输出 100 <= number < 1000 间的偶数
列表,字典,集合中根据条件筛选数据

列表
data = [randint(-10,10) for _ in range(10)]
通用:迭代
filter(lambda x:x>0,data) #filter函数
[x for x in data if x > 0] #列表解析 更快
方法:
-
迭代
-
filter函数
-
列表解析
字典
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
字典解析:
d={x:randint(60,100) for x in range(1,21)}
{k:v for k,v in d.items() if v >90} #在Python 3.x 里面,iteritems()方法已经废除了
集合
date = [randint(-10,10) for _ in range(10)] #[-6, -2, 2, -8, -7, -7, -10, 1, -10, -8]
s = set(date) #{1, 2, -10, -8, -7, -6, -2}
{x for x in s if x % 3 == 0} #{-6}
元组命名
元组:存储空间小,访问速度快
类似其他语言枚举
#NAME=0
#AGE=1
#SEX=2
#EMAIL=3
NAME,AGE,SEX,EMAIL = range(4)
student=('Jim','19','male','jim8721.@gmain.com')
print(student[NAME])
print(student[AGE])
print(student[SEX])
print(student[EMAIL])
collections.namedtuple替代内置tuple
from collections import namedtuple
Student = namedtuple('Student',['name','age','sex','email'])
s=Student('Jim','19','male','jim8721.@gmain.com')
print(s) #Student(name='Jim', age='19', sex='male', email='jim8721.@gmain.com')
print(s.name) #Jim
print(s.age) #19
print(isinstance(s,tuple)) #True
如何统计序列中元素出现的频率

列表变为字典的形式
from random import randint
data=[randint(0,20) for _ in range(10)] #生成10个0~20的随机数
print(data) #[1, 3, 7, 19, 17, 11, 14, 14, 16, 16]
c = dict.fromkeys(data,0)
print(c) #{1: 0, 3: 0, 7: 0, 19: 0, 17: 0, 11: 0, 14: 0, 16: 0}
for x in data:
c[x] += 1 #data中的数字的字典形式的键值+1(原来键值为0)
print(c) #{1: 1, 3: 1, 7: 1, 19: 1, 17: 1, 11: 1, 14: 2, 16: 2}
筛选字典中的值
{k:v for k,v in c.items() if v >1} #{14: 2, 16: 2} 字典解析
from collections import Counter #函数
c2 = Counter(data)
c2.most_common(3) #most_common 出现频度最高
对某文章单词词频统计
from collections import Counter
a = open('navicat.txt').read()
b= re.split('W+',a)
c = Counter(b)
d=c.most_common(3)
字典排序
将字典转化为元组 list(iter(d))
d = { x:randint(60,100) for x in 'xyzabc'}
#{'x': 79, 'y': 62, 'z': 62, 'a': 84, 'b': 83, 'c': 95}
q=list(iter(d)) #['x', 'y', 'z', 'a', 'b', 'c']
sorted(zip(d.values(),d.keys()))
#[(62, 'y'), (62, 'z'), (79, 'x'), (83, 'b'), (84, 'a'), (95, 'c')]
dprint(d) # {'x': 89, 'y': 69, 'z': 96, 'a': 69, 'b': 92, 'c': 78}
d.item() #dict_items([('x', 89), ('y', 69), ('z', 96), ('a', 69), ('b', 92), ('c', 78)])
sorted(d.items(),key=lambda x:x[1]) #将字典中的所有项,以列表方式返回,第二项做键值
多个字典的公共键
from random import randint,sample
sample('abcdefg',randint(3,6)) #随机取样
s1={x:randint(1,4) for x in sample('abcdefg',randint(3,6))}
s2={x:randint(1,4) for x in sample('abcdefg',randint(3,6))}
s3={x:randint(1,4) for x in sample('abcdefg',randint(3,6))}
res = []
for k in s1:
if k in s2 and k in s3:
res.append(k)
print(res)
Lambda
lambda argument_list: expression
-
匿名
-
有输入和输出
-
单行expression决定了lambda函数不可能完成复杂的逻辑,只能完成非常简单的功能。
add=lambda x, y: x+y
print(add(1,2)) #3
历史纪录
from collections import deque
history = deque([],5)
...
history.append(k)
...
if line == 'history':
print(list(history))
多进程
def main():
look_process = multiprocessing.Process(target=look)
walk_process = multiprocessing.Process(target=walk)
look_process.start()
walk_process.start()
if __name__ == '__main__':
main()
str转bytes
b=str1.encode()
bytes转换成str
b.decode()
pickle
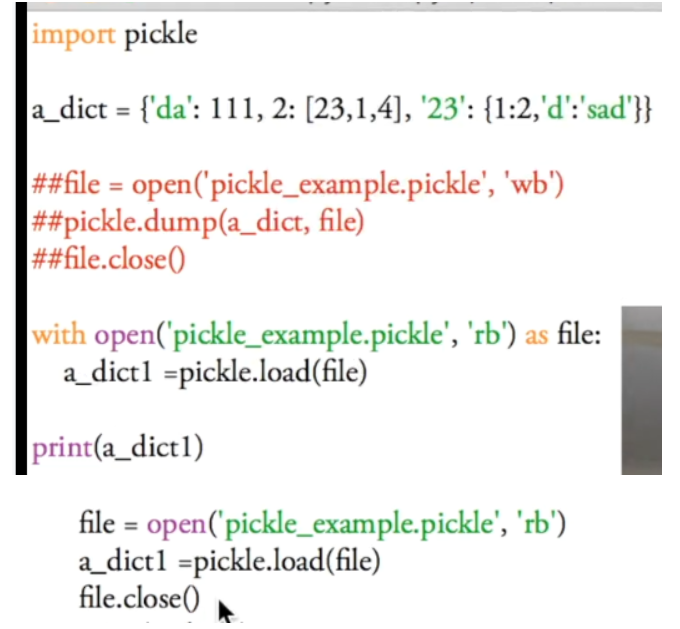
文件读写
写

追加

读

file.readline() 一行一行的读 全部后面加s 放在python列表中