-
机器学习的分类
机器学习主要分为监督学习和无监督学习,监督学习就是数据集中的每个样本都有正确的答案,比如回归问题和分类问题。无监督学习使用的数据集没有任何标签,让机器自己学习,比如聚类算法,主要学习了监督学习中的线性回归算法和逻辑回归算法。
-
线性回归
单变量线性回归算法,比如我们根据房子的面积去预测房价时,首先我们设定一个假设函数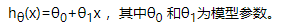 根据这个假设函数求得一个预测值,那么我们怎么去确定参数从而到达精准预测的目的呢?我们可以通过代价函数来确定函数的参数,代价函数为
根据这个假设函数求得一个预测值,那么我们怎么去确定参数从而到达精准预测的目的呢?我们可以通过代价函数来确定函数的参数,代价函数为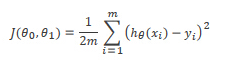 也就是用预测到的值减去真实值的平方和再求平均,只有这个函数的值越来越小时,预测到的结果值才越接近真实值,因此我们要确定参数使得代价函数取得最小值,这个时候就用到梯度下降的方法,梯度下降公式中的a值是学习率,学习率可以控制参数更新的快慢,对两个参数进行求导,
也就是用预测到的值减去真实值的平方和再求平均,只有这个函数的值越来越小时,预测到的结果值才越接近真实值,因此我们要确定参数使得代价函数取得最小值,这个时候就用到梯度下降的方法,梯度下降公式中的a值是学习率,学习率可以控制参数更新的快慢,对两个参数进行求导,
将求导的结果带入到梯度下降的公式中,每一次循环就对参数进行更新,直到找到最优的参数,得到代价函数的最小值。
-
逻辑回归
逻辑回归算法适用于二分类问题,同样也是通过代价函数,采用梯度下降的方法不断地更新参数,但是采用误差平方的代价函数不利于梯度更新,因此我们采用了另一种方式来定义代价函数。![]() 采用这种方式的原因见笔记本。和线性回归一样,采用梯度下降的方式迭代更新参数,获取到代价函数的最小值。
采用这种方式的原因见笔记本。和线性回归一样,采用梯度下降的方式迭代更新参数,获取到代价函数的最小值。
-
卷积神经网络
深度学习主要学习了三个神经网络模型,首先是卷积神经网络模型,它在计算机视觉方面应用比较广泛,图中所示的是LeNet-5模型,输入的图片是一个32*32*1大小的图片,卷积层中的过滤器大小为5*5*6,因此会得到一个28*28*6矩阵,之后经过池化层,过滤器大小为2*2,步长为2,会得到一个14*14*6大小的矩阵,在经过大小为5*5*16的过滤器,得到10*10*16大小的矩阵,再经过池化层,过滤器大小为2*2,步长为2,得到5*5*16大小的矩阵,最后经过全连接层,共有400个节点,每个节点有120个神经元,有时这400个节点会抽出部分神经元构建另一个全连接层,这样就会有两个全连接层,第二个全连接层有84个特征,最后得到输出。
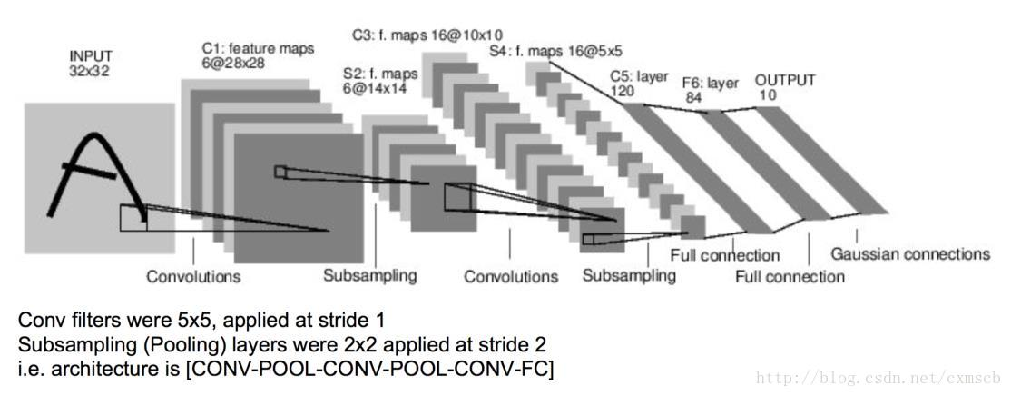
前向传播和反向传播,首先计算出神经网络地输出,然后进行反向传播操作,计算出对应地梯度,从而更新参数。