SSD: Single Shot MultiBox Detector
SSD 的贡献是:
1, 比state-of-the-art single shot detector YOLO取得了更快和更准确的表现。
2, SSD的核心是使用convolutional filter在feature map的很多给定的Bounding boxes中得到category scores 和 box offsets。
3, 为了获得高的detection accuracy , 在不同 scales 上的feature maps 进行预测。
网络结构:
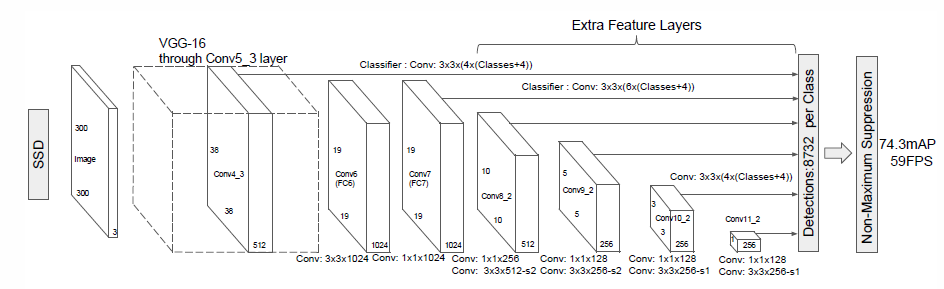
SSD的关键特点有:
(1), 使用 multi-scale feature maps 来detect,
(2), Convolutional predictors , 没有采用FC layer,这样可以适用于各种size的image,对于一个NxMxP的feature map, prediction detection 是 3x3xP的small kernel
(3),利用filter作为classifier 和 regressor,来对feature map的每一个pixels所在的位置是否object并且判断bbox相对于ground true的offsets。此时,filter将classifier和regressor结合起来,所以产生了filter产生的vector的维度是 (c + 4) x K, 其中c是categories number, 4 是bbox相对于ground true的4个offsets,k值是不同aspect和scale的bbox的数量。
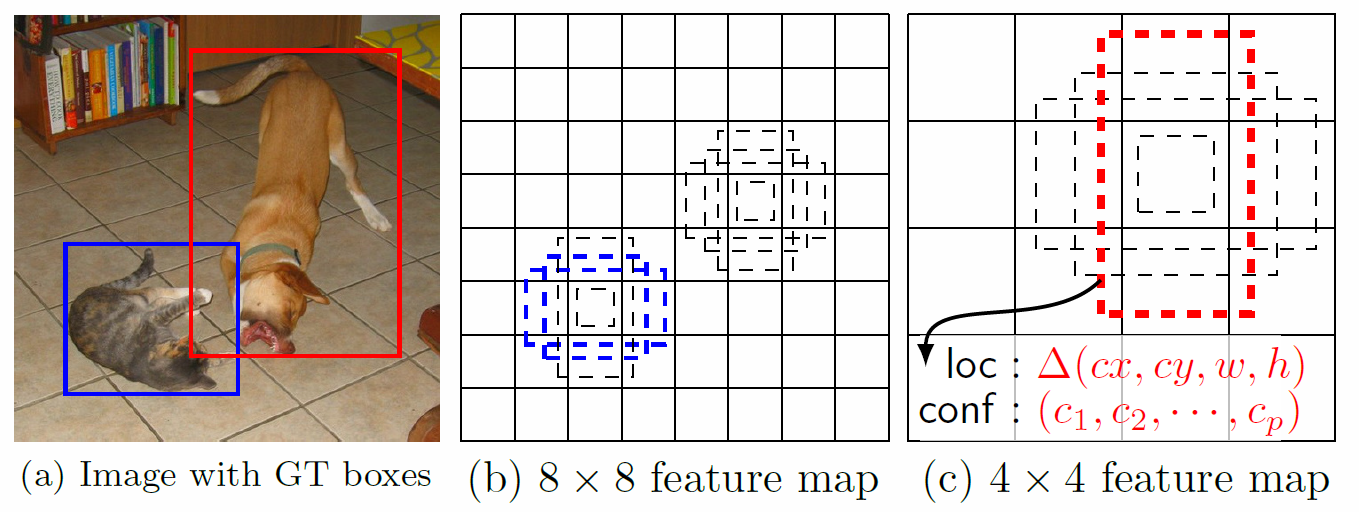
Training:
包含: default boxes集合和detection scale的选择,hard negative mining 和 data augmentation。Hard negative mining,因为出来的绝大多数的bbox都是negatives,为了使得categories balance,sort 之后取最高的confidence loss的bbox,其中限制 negative/positive 最大为3.
对于Matching,用jaccard overlap来衡量每一个candidate的bounding boxes。
其中training loss是:

Loss function 是localization 和 confidence 结合的加权和。
Aspect和scale的选取:
假设我们想要选择m个feature maps来做prediction,scale的计算可为:

其中 Smin是0.2,表示lowest layer的scale是0.2。Smax是0.9。
总结:
(1), 用filter来做classification和regression是一个新的创新,这样就可以不引入fc,从而让image可以任意shape
(2),用multi-scale进行detection,浅层的feature map对较小的object有保证。
(3),多级的filter进行detection,有个疑问,不同scale的backpropagation对network的影响不同,浅层scale的backpropagation对前面的主干cnn影响较大,而后面scale的对前面的主干cnn的影响较小,是否会有影响?