import os
import shutil
import requests
# 文件路径处理
base_dir = os.path.dirname(os.path.abspath(__file__))
download_folder = os.path.join(base_dir, 'files', 'package')
if not os.path.exists(download_folder):
os.makedirs(download_folder)
# 1.下载文件
file_url = 'https://files.cnblogs.com/files/wupeiqi/HtmlStore.zip'
res = requests.get(url=file_url)
# 2.将下载的文件保存到当前执行脚本同级目录下 /files/package/ 目录下(且文件名为 HtmlStore.zip )
file_name = file_url.split('/')[-1]
zip_file_path = os.path.join(download_folder, file_name) # .../files/package/HtmlStore.zip
with open(zip_file_path, mode='wb') as file_object:
file_object.write(res.content)
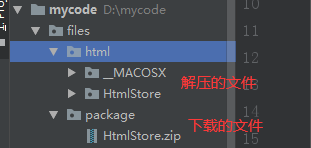
# 3.在将下载下来的文件解压到 /files/html/ 目录下
unpack_folder = os.path.join(base_dir, 'files', 'html')
shutil.unpack_archive(filename=zip_file_path, extract_dir=unpack_folder, format='zip')