import os
import re
import requests
from urllib import request
from bs4 import BeautifulSoup
dirName = './美女图片'
if not os.path.exists(dirName):
os.mkdir(dirName)
url = "http://pic.netbian.com/4kmeinv/index_{}.html"
for page in range(6, 8):
print("正在爬取第{}页数据:".format(page))
new_url = url.format(page)
response = requests.get(new_url)
response.encoding = "gbk"
soup = BeautifulSoup(response.text, "html.parser")
div_obj = soup.find(name="div", attrs={"class": "slist"})
li_list = div_obj.find_all(name="li")
for li in li_list:
img = li.find(name="img")
img_src = img.get("src")
new_img_src = "http://pic.netbian.com/" + img_src
img_name = new_img_src.split('/')[-1]
img_path = dirName + '/' + img_name # ./imgLibs/xxxx.jpg
request.urlretrieve(new_img_src, filename=img_path)
print(img_name, '下载成功!!!')
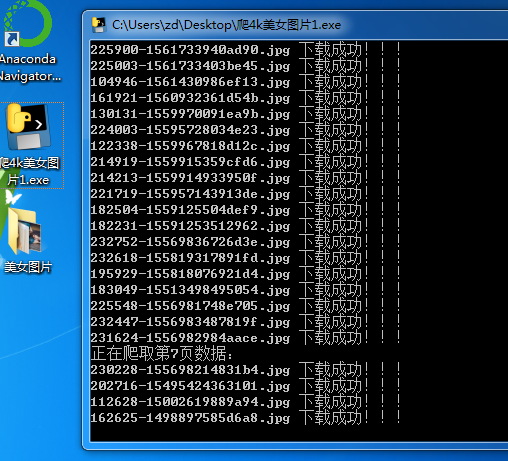
效果:
打包exe: